Compare commits
180 Commits
| Author | SHA1 | Date |
|---|---|---|
|
|
f855572ebf | |
|
|
cc9bbddfff | |
|
|
45bf6f6b65 | |
|
|
3e99dad408 | |
|
|
54d05e1330 | |
|
|
178168cc68 | |
|
|
c646c01789 | |
|
|
ad73a01a03 | |
|
|
22d6a9b137 | |
|
|
527b52cae2 | |
|
|
868a8fff99 | |
|
|
079cef0c2a | |
|
|
a677ccb018 | |
|
|
61397d616d | |
|
|
6940eae650 | |
|
|
ab08e54e37 | |
|
|
8757956636 | |
|
|
affdaa8fab | |
|
|
3443331501 | |
|
|
4353c84837 | |
|
|
b01382f267 | |
|
|
9d6a2be49e | |
|
|
39aada312c | |
|
|
87d59648cf | |
|
|
24d23ad230 | |
|
|
1c2bd2545c | |
|
|
bd3bff1f0d | |
|
|
01c50f4644 | |
|
|
99578f8577 | |
|
|
c2b4c38e2f | |
|
|
c6b29c2fab | |
|
|
070402eb1e | |
|
|
56f9aac92a | |
|
|
04f6881131 | |
|
|
2175231bc1 | |
|
|
669ceee48a | |
|
|
1704406cdf | |
|
|
fa65929c97 | |
|
|
8bc87a4b74 | |
|
|
4c210b9e52 | |
|
|
2a8bb7cf28 | |
|
|
52dc84cd13 | |
|
|
df80d2708b | |
|
|
4c04188ade | |
|
|
1271df5ca7 | |
|
|
577d914e93 | |
|
|
63f3901eaf | |
|
|
99f3220048 | |
|
|
d4b45a7a99 | |
|
|
ef71146e87 | |
|
|
cc1ff1c989 | |
|
|
5b68d7865e | |
|
|
d7c1cbf8ae | |
|
|
7b59e623ff | |
|
|
d1b5bd2958 | |
|
|
68c8ea0946 | |
|
|
49e63f753f | |
|
|
e734c51fe0 | |
|
|
b83ac15e68 | |
|
|
46c379bdaf | |
|
|
23d2c37486 | |
|
|
0ba450dcfe | |
|
|
8bb5fc9b23 | |
|
|
267c48962e | |
|
|
5d34eda4b9 | |
|
|
8424219bfc | |
|
|
de88ab6459 | |
|
|
2094e521e2 | |
|
|
bfac933203 | |
|
|
399139e6b4 | |
|
|
3051861a27 | |
|
|
36f2769d5e | |
|
|
a0eebfa6b6 | |
|
|
5ad725569d | |
|
|
8c93b88718 | |
|
|
df44ae75a5 | |
|
|
86595984a0 | |
|
|
906332e61d | |
|
|
72e9851922 | |
|
|
732e3381ba | |
|
|
c8ce5847d4 | |
|
|
bde9f7adec | |
|
|
43710c6324 | |
|
|
71f71d554c | |
|
|
1f6ec20685 | |
|
|
92b788862a | |
|
|
a515b9c1fd | |
|
|
8c9673a067 | |
|
|
4c84257fc1 | |
|
|
6c41ae40ac | |
|
|
f3782f08ad | |
|
|
e835902471 | |
|
|
786a21c61d | |
|
|
5e887ed479 | |
|
|
87987f72d1 | |
|
|
58529d659b | |
|
|
725553e501 | |
|
|
5034c3e82b | |
|
|
268c426349 | |
|
|
3e297d9643 | |
|
|
4228525dc3 | |
|
|
5e81860090 | |
|
|
f11a1105c9 | |
|
|
b1e4369f5d | |
|
|
779533a234 | |
|
|
c6f65211bd | |
|
|
6357080255 | |
|
|
9b8c8d9081 | |
|
|
bf19aee67d | |
|
|
4fe575fa85 | |
|
|
2a0dd80035 | |
|
|
b81f97e737 | |
|
|
0b3be0efca | |
|
|
7e01277dc2 | |
|
|
881fb6cba1 | |
|
|
1522931f6f | |
|
|
d14fb608d3 | |
|
|
abb37f17fd | |
|
|
cf770892f1 | |
|
|
1c2fb8db18 | |
|
|
64b94bfea5 | |
|
|
349e46739c | |
|
|
7f1c29df2d | |
|
|
318b7ebadc | |
|
|
8aba2a5612 | |
|
|
6bd2d0cf0e | |
|
|
4f8f3213c4 | |
|
|
3b237a0339 | |
|
|
ba05436fec | |
|
|
7a35d31c4b | |
|
|
df79746c71 | |
|
|
3e6284b04d | |
|
|
1964a0e488 | |
|
|
f9b263a718 | |
|
|
3640e4e70a | |
|
|
89f76b7f58 | |
|
|
837e934476 | |
|
|
7cbd77edc5 | |
|
|
36fd27c83c | |
|
|
06335058f3 | |
|
|
4448220085 | |
|
|
95e906a196 | |
|
|
4e2709468b | |
|
|
34277a3c67 | |
|
|
b5a442c042 | |
|
|
16752df99c | |
|
|
a2e9279189 | |
|
|
51ae29e851 | |
|
|
2a185a4119 | |
|
|
e70be5f158 | |
|
|
a38c65f265 | |
|
|
088e2a459f | |
|
|
42b786b7f3 | |
|
|
31056e8250 | |
|
|
ef34756046 | |
|
|
fd353d57cc | |
|
|
de857c6543 | |
|
|
c10ad67e43 | |
|
|
c9e1c22ee1 | |
|
|
5d3120e554 | |
|
|
41c0c3e3a0 | |
|
|
0ec5795f82 | |
|
|
12db8e001a | |
|
|
a6313ca406 | |
|
|
8bb1674bef | |
|
|
f81176b3dc | |
|
|
48b4da80e5 | |
|
|
0e4e979494 | |
|
|
5901071697 | |
|
|
ad71293f0a | |
|
|
5035a598ff | |
|
|
c5bbd11414 | |
|
|
eea35ce204 | |
|
|
3b1a2e67a7 | |
|
|
4af7c6a365 | |
|
|
615a36257b | |
|
|
be087c01cd | |
|
|
f31c40353c | |
|
|
15c826d03e | |
|
|
26da00f1a2 |
7
.flake8
|
|
@ -1,7 +0,0 @@
|
|||
[flake8]
|
||||
extend-ignore = E203, E266, E501
|
||||
# line length is intentionally set to 80 here because black uses Bugbear
|
||||
# See https://github.com/psf/black/blob/master/docs/the_black_code_style.md#line-length for more details
|
||||
max-line-length = 80
|
||||
max-complexity = 18
|
||||
select = B,C,E,F,W,T4,B9
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
# These are supported funding model platforms
|
||||
|
||||
github: [nathom]
|
||||
patreon: # Replace with a single Patreon username
|
||||
open_collective: # Replace with a single Open Collective username
|
||||
ko_fi: # Replace with a single Ko-fi username
|
||||
tidelift: # Replace with a single Tidelift platform-name/package-name e.g., npm/babel
|
||||
community_bridge: # Replace with a single Community Bridge project-name e.g., cloud-foundry
|
||||
liberapay: # Replace with a single Liberapay username
|
||||
issuehunt: # Replace with a single IssueHunt username
|
||||
otechie: # Replace with a single Otechie username
|
||||
lfx_crowdfunding: # Replace with a single LFX Crowdfunding project-name e.g., cloud-foundry
|
||||
custom: # Replace with up to 4 custom sponsorship URLs e.g., ['link1', 'link2']
|
||||
|
|
@ -36,9 +36,9 @@ body:
|
|||
attributes:
|
||||
label: Debug Traceback
|
||||
description: |
|
||||
Run your command, with `-vvv` appended to it, and paste the output here.
|
||||
Run your command with the `-vvv` option and paste the output here.
|
||||
For example, if the problematic command was `rip url https://example.com`, then
|
||||
you would run `rip url https://example.com -vvv` to get the debug logs.
|
||||
you would run `rip -vvv url https://example.com` to get the debug logs.
|
||||
Make sure to check the logs for any personal information such as emails and remove them.
|
||||
render: "text"
|
||||
placeholder: Logs printed to terminal screen
|
||||
|
|
@ -49,7 +49,7 @@ body:
|
|||
attributes:
|
||||
label: Config File
|
||||
description: |
|
||||
Find the config file using `rip config --open` and paste the contents here.
|
||||
Find the config file using `rip config open` and paste the contents here.
|
||||
Make sure you REMOVE YOUR CREDENTIALS!
|
||||
render: toml
|
||||
placeholder: Contents of config.toml
|
||||
|
|
|
|||
|
|
@ -1,17 +1,2 @@
|
|||
# Number of days of inactivity before an issue becomes stale
|
||||
daysUntilStale: 60
|
||||
# Number of days of inactivity before a stale issue is closed
|
||||
daysUntilClose: 7
|
||||
# Issues with these labels will never be considered stale
|
||||
exemptLabels:
|
||||
- pinned
|
||||
- security
|
||||
# Label to use when marking an issue as stale
|
||||
staleLabel: stale
|
||||
# Comment to post when marking an issue as stale. Set to `false` to disable
|
||||
markComment: >
|
||||
This issue has been automatically marked as stale because it has not had
|
||||
recent activity. It will be closed if no further activity occurs. Thank you
|
||||
for your contributions.
|
||||
# Comment to post when closing a stale issue. Set to `false` to disable
|
||||
closeComment: false
|
||||
- name: Close Stale Issues
|
||||
uses: actions/stale@v9.0.0
|
||||
|
|
|
|||
|
|
@ -18,6 +18,6 @@ jobs:
|
|||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- name: Build and publish to pypi
|
||||
uses: JRubics/poetry-publish@v1.6
|
||||
uses: JRubics/poetry-publish@v1.17
|
||||
with:
|
||||
pypi_token: ${{ secrets.PYPI_TOKEN }}
|
||||
|
|
|
|||
|
|
@ -0,0 +1,41 @@
|
|||
name: Python Poetry Test
|
||||
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
- dev
|
||||
pull_request:
|
||||
branches:
|
||||
- main
|
||||
- dev
|
||||
|
||||
jobs:
|
||||
test:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
name: Check out repository code
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: '3.10' # Specify the Python version
|
||||
|
||||
- name: Install and configure Poetry
|
||||
uses: snok/install-poetry@v1
|
||||
with:
|
||||
version: 1.5.1
|
||||
virtualenvs-create: false
|
||||
virtualenvs-in-project: true
|
||||
installer-parallel: true
|
||||
|
||||
- name: Install dependencies
|
||||
run: poetry install
|
||||
|
||||
- name: Run tests
|
||||
run: poetry run pytest
|
||||
|
||||
- name: Success message
|
||||
if: success()
|
||||
run: echo "Tests passed successfully!"
|
||||
|
|
@ -0,0 +1,11 @@
|
|||
name: Ruff
|
||||
on: [push, pull_request]
|
||||
jobs:
|
||||
ruff:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
- uses: chartboost/ruff-action@v1
|
||||
- uses: chartboost/ruff-action@v1
|
||||
with:
|
||||
args: 'format --check'
|
||||
|
|
@ -20,3 +20,4 @@ StreamripDownloads
|
|||
*test.py
|
||||
/.mypy_cache
|
||||
.DS_Store
|
||||
pyrightconfig.json
|
||||
|
|
|
|||
|
|
@ -1,3 +0,0 @@
|
|||
[settings]
|
||||
multi_line_output=3
|
||||
include_trailing_comma=True
|
||||
53
.mypy.ini
|
|
@ -1,53 +0,0 @@
|
|||
[mypy-mutagen.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-tqdm.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-pathvalidate.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-pick.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-simple_term_menu.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-setuptools.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-requests.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-tomlkit.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-Crypto.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-Cryptodome.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-click.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-PIL.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-cleo.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-deezer.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-appdirs.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-m3u8.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-aiohttp.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-aiofiles.*]
|
||||
ignore_missing_imports = True
|
||||
78
README.md
|
|
@ -1,26 +1,27 @@
|
|||
# streamrip
|
||||

|
||||
|
||||
[](https://pepy.tech/project/streamrip)
|
||||
[](https://github.com/python/black)
|
||||
|
||||
A scriptable stream downloader for Qobuz, Tidal, Deezer and SoundCloud.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
## Features
|
||||
|
||||
- Super fast, as it utilizes concurrent downloads and conversion
|
||||
- Fast, concurrent downloads powered by `aiohttp`
|
||||
- Downloads tracks, albums, playlists, discographies, and labels from Qobuz, Tidal, Deezer, and SoundCloud
|
||||
- Supports downloads of Spotify and Apple Music playlists through [last.fm](https://www.last.fm)
|
||||
- Automatically converts files to a preferred format
|
||||
- Has a database that stores the downloaded tracks' IDs so that repeats are avoided
|
||||
- Easy to customize with the config file
|
||||
- Concurrency and rate limiting
|
||||
- Interactive search for all sources
|
||||
- Highly customizable through the config file
|
||||
- Integration with `youtube-dl`
|
||||
|
||||
## Installation
|
||||
|
||||
First, ensure [Python](https://www.python.org/downloads/) (version 3.8 or greater) and [pip](https://pip.pypa.io/en/stable/installing/) are installed. If you are on Windows, install [Microsoft Visual C++ Tools](https://visualstudio.microsoft.com/visual-cpp-build-tools/). Then run the following in the command line:
|
||||
First, ensure [Python](https://www.python.org/downloads/) (version 3.10 or greater) and [pip](https://pip.pypa.io/en/stable/installing/) are installed. Then install `ffmpeg`. You may choose not to install this, but some functionality will be limited.
|
||||
|
||||
```bash
|
||||
pip3 install streamrip --upgrade
|
||||
|
|
@ -34,7 +35,16 @@ rip
|
|||
|
||||
it should show the main help page. If you have no idea what these mean, or are having other issues installing, check out the [detailed installation instructions](https://github.com/nathom/streamrip/wiki#detailed-installation-instructions).
|
||||
|
||||
If you would like to use `streamrip`'s conversion capabilities, download TIDAL videos, or download music from SoundCloud, install [ffmpeg](https://ffmpeg.org/download.html). To download music from YouTube, install [youtube-dl](https://github.com/ytdl-org/youtube-dl#installation).
|
||||
For Arch Linux users, an AUR package exists. Make sure to install required packages from the AUR before using `makepkg` or use an AUR helper to automatically resolve them.
|
||||
```
|
||||
git clone https://aur.archlinux.org/streamrip.git
|
||||
cd streamrip
|
||||
makepkg -si
|
||||
```
|
||||
or
|
||||
```
|
||||
paru -S streamrip
|
||||
```
|
||||
|
||||
### Streamrip beta
|
||||
|
||||
|
|
@ -61,17 +71,13 @@ Download multiple albums from Qobuz
|
|||
rip url https://www.qobuz.com/us-en/album/back-in-black-ac-dc/0886444889841 https://www.qobuz.com/us-en/album/blue-train-john-coltrane/0060253764852
|
||||
```
|
||||
|
||||
|
||||
|
||||
Download the album and convert it to `mp3`
|
||||
|
||||
```bash
|
||||
rip url --codec mp3 https://open.qobuz.com/album/0060253780968
|
||||
rip --codec mp3 url https://open.qobuz.com/album/0060253780968
|
||||
```
|
||||
|
||||
|
||||
|
||||
To set the maximum quality, use the `--max-quality` option to `0, 1, 2, 3, 4`:
|
||||
To set the maximum quality, use the `--quality` option to `0, 1, 2, 3, 4`:
|
||||
|
||||
| Quality ID | Audio Quality | Available Sources |
|
||||
| ---------- | --------------------- | -------------------------------------------- |
|
||||
|
|
@ -81,30 +87,24 @@ To set the maximum quality, use the `--max-quality` option to `0, 1, 2, 3, 4`:
|
|||
| 3 | 24 bit, ≤ 96 kHz | Tidal (MQA), Qobuz, SoundCloud (rarely) |
|
||||
| 4 | 24 bit, ≤ 192 kHz | Qobuz |
|
||||
|
||||
|
||||
|
||||
```bash
|
||||
rip url --max-quality 3 https://tidal.com/browse/album/147569387
|
||||
rip --quality 3 url https://tidal.com/browse/album/147569387
|
||||
```
|
||||
|
||||
Search for albums matching `lil uzi vert` on SoundCloud
|
||||
> Using `4` is generally a waste of space. It is impossible for humans to perceive the difference between sampling rates higher than 44.1 kHz. It may be useful if you're processing/slowing down the audio.
|
||||
|
||||
Search for playlists matching `rap` on Tidal
|
||||
|
||||
```bash
|
||||
rip search --source soundcloud 'lil uzi vert'
|
||||
rip search tidal playlist 'rap'
|
||||
```
|
||||
|
||||

|
||||
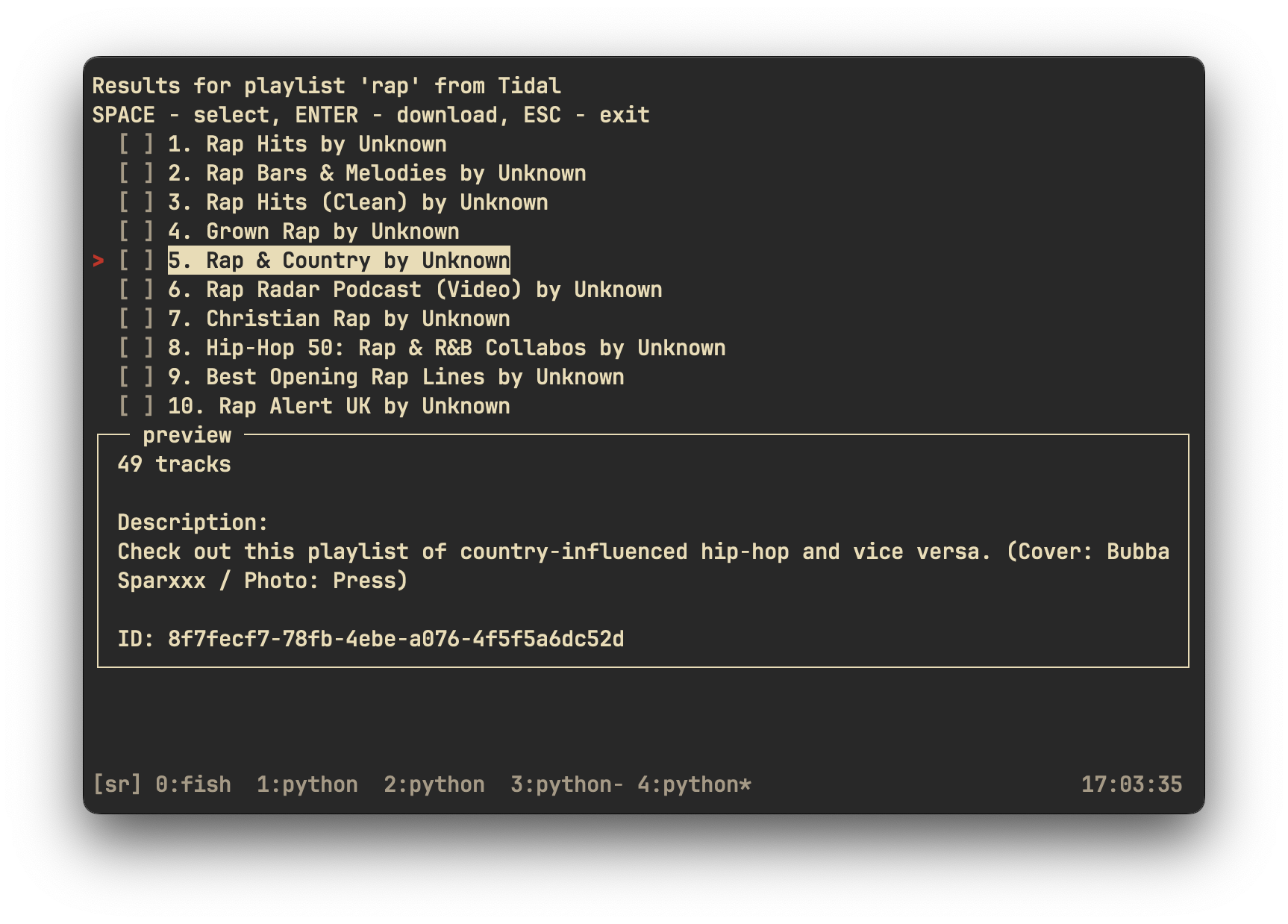
|
||||
|
||||
Search for *Rumours* on Tidal, and download it
|
||||
|
||||
```bash
|
||||
rip search 'fleetwood mac rumours'
|
||||
```
|
||||
|
||||
Want to find some new music? Use the `discover` command (only on Qobuz)
|
||||
|
||||
```bash
|
||||
rip discover --list 'best-sellers'
|
||||
rip search tidal album 'fleetwood mac rumours'
|
||||
```
|
||||
|
||||
Download a last.fm playlist using the lastfm command
|
||||
|
|
@ -113,18 +113,16 @@ Download a last.fm playlist using the lastfm command
|
|||
rip lastfm https://www.last.fm/user/nathan3895/playlists/12126195
|
||||
```
|
||||
|
||||
For extreme customization, see the config file
|
||||
For more customization, see the config file
|
||||
|
||||
```
|
||||
rip config --open
|
||||
rip config open
|
||||
```
|
||||
|
||||
|
||||
|
||||
If you're confused about anything, see the help pages. The main help pages can be accessed by typing `rip` by itself in the command line. The help pages for each command can be accessed with the `-h` flag. For example, to see the help page for the `url` command, type
|
||||
If you're confused about anything, see the help pages. The main help pages can be accessed by typing `rip` by itself in the command line. The help pages for each command can be accessed with the `--help` flag. For example, to see the help page for the `url` command, type
|
||||
|
||||
```
|
||||
rip url -h
|
||||
rip url --help
|
||||
```
|
||||
|
||||
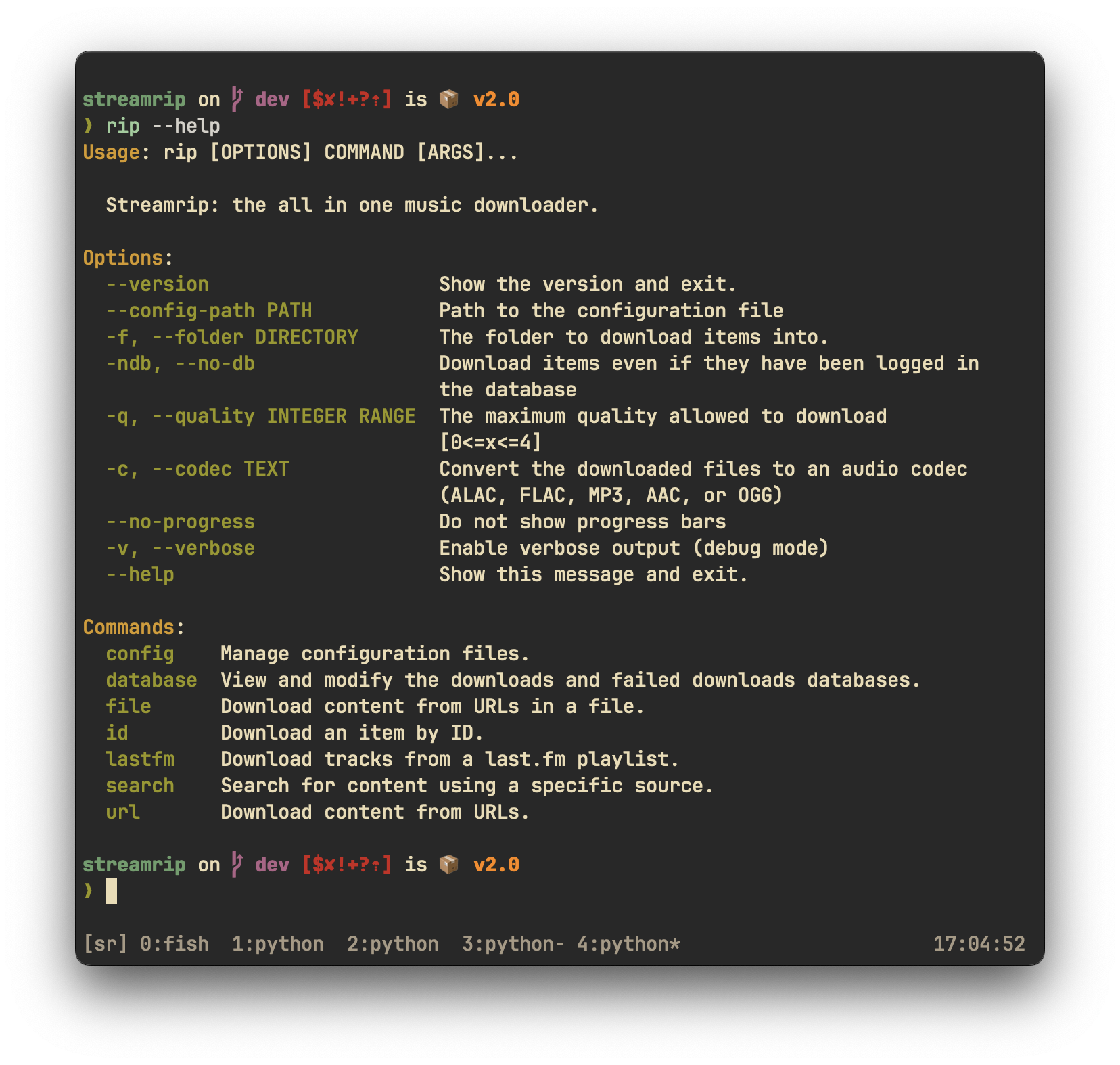
|
||||
|
|
@ -133,7 +131,6 @@ rip url -h
|
|||
|
||||
For more in-depth information about `streamrip`, see the help pages and the [wiki](https://github.com/nathom/streamrip/wiki/).
|
||||
|
||||
|
||||
## Contributions
|
||||
|
||||
All contributions are appreciated! You can help out the project by opening an issue
|
||||
|
|
@ -158,7 +155,7 @@ Please document any functions or obscure lines of code.
|
|||
|
||||
### The Wiki
|
||||
|
||||
To help out `streamrip` users that may be having trouble, consider contributing some information to the wiki.
|
||||
To help out `streamrip` users that may be having trouble, consider contributing some information to the wiki.
|
||||
Nothing is too obvious and everything is appreciated.
|
||||
|
||||
## Acknowledgements
|
||||
|
|
@ -172,17 +169,10 @@ Thanks to Vitiko98, Sorrow446, and DashLt for their contributions to this projec
|
|||
- [Tidal-Media-Downloader](https://github.com/yaronzz/Tidal-Media-Downloader)
|
||||
- [scdl](https://github.com/flyingrub/scdl)
|
||||
|
||||
|
||||
|
||||
## Disclaimer
|
||||
|
||||
I will not be responsible for how **you** use `streamrip`. By using `streamrip`, you agree to the terms and conditions of the Qobuz, Tidal, and Deezer APIs.
|
||||
|
||||
I will not be responsible for how you use `streamrip`. By using `streamrip`, you agree to the terms and conditions of the Qobuz, Tidal, and Deezer APIs.
|
||||
## Sponsorship
|
||||
|
||||
## Donations/Sponsorship
|
||||
|
||||
<a href="https://www.buymeacoffee.com/nathom" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/default-orange.png" alt="Buy Me A Coffee" height="41" width="174"></a>
|
||||
|
||||
|
||||
Consider contributing some funds [here](https://www.buymeacoffee.com/nathom), which will go towards holding
|
||||
the premium subscriptions that I need to debug and improve streamrip. Thanks for your support!
|
||||
Consider becoming a Github sponsor for me if you enjoy my open source software.
|
||||
|
|
|
|||
{kind=link}
|
Before Width: | Height: | Size: 325 KiB |
{kind=link}
|
Before Width: | Height: | Size: 148 KiB |
{kind=link}
|
Before Width: | Height: | Size: 292 KiB After Width: | Height: | Size: 377 KiB |
{kind=link}
|
Before Width: | Height: | Size: 407 KiB After Width: | Height: | Size: 641 KiB |
{kind=link}
|
|
@ -0,0 +1,137 @@
|
|||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<!-- Generator: Adobe Illustrator 27.3.1, SVG Export Plug-In . SVG Version: 6.00 Build 0) -->
|
||||
<svg version="1.1" id="Layer_1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" x="0px" y="0px"
|
||||
viewBox="0 0 768 256" style="enable-background:new 0 0 768 256;" xml:space="preserve">
|
||||
<style type="text/css">
|
||||
.st0{fill:#252525;}
|
||||
.st1{fill:#E9D7B0;}
|
||||
.st2{fill:#FFFFFF;}
|
||||
.st3{fill:url(#SVGID_1_);}
|
||||
.st4{fill:url(#SVGID_00000055683228248778521670000006510520551845247645_);}
|
||||
.st5{fill:url(#SVGID_00000158743434889325090190000000134816785925054387_);}
|
||||
.st6{fill:url(#SVGID_00000076587668925285995460000015083660019040157360_);}
|
||||
.st7{fill:url(#SVGID_00000065791897104437684560000004534853821863457943_);}
|
||||
.st8{fill:url(#SVGID_00000178914817404700868070000017136081737691720877_);}
|
||||
</style>
|
||||
<rect class="st0" width="768" height="256"/>
|
||||
<g id="_x23_e9d7b0ff">
|
||||
<path class="st1" d="M93.39,83.44c13.36-5.43,28.85-5.44,42.21,0c15.49,5.93,28.38,21.3,27.02,38.48
|
||||
c-0.74,14.18-11.01,26.26-23.41,32.34c-2.91,0.98-1.75,4.44-0.87,6.49c0.96,3.43,3.24,7.74,0.33,10.83
|
||||
c-3.16,3.12-8.93,2.28-11.58-1.18c-2.64,4.15-9.77,4.18-12.42,0.06c-3.06,3.86-9.98,4.28-12.78-0.09c-2.8,3.9-9.73,4.44-12.36,0.12
|
||||
c-2.18-5.21,3.39-10.37,1.64-15.39c-5.03-2.9-10.16-5.83-14.16-10.13c-8.48-8.48-12.72-21.27-9.79-33.04
|
||||
C70.22,98.67,81.06,88.37,93.39,83.44 M85.88,106c-0.12,9.66-0.05,19.32-0.04,28.99c-0.29,1.43,1.67,2.49,2.75,1.6
|
||||
c8.39-4.91,16.87-9.71,25.14-14.8c0.07-0.43,0.19-1.28,0.25-1.71c-0.71-1.02-1.95-1.44-2.94-2.11c-7.67-4.44-15.27-9-22.97-13.38
|
||||
l-1-0.02C86.77,104.93,86.18,105.64,85.88,106 M116.47,107.51c-0.11,0.35-0.33,1.03-0.45,1.37c4.97,8.7,9.87,17.49,15.13,26
|
||||
c0.47,0.04,1.39,0.11,1.86,0.15c5.31-8.16,9.87-16.87,14.85-25.26c1.17-1.23-0.24-3.31-1.8-2.9c-9.69,0.07-19.39-0.17-29.06,0.12
|
||||
L116.47,107.51 M108.66,152.02c3.93,0.09,7.87,0.05,11.8,0.02l0.28-0.79c-1.94-3.36-3.83-6.75-5.87-10.05
|
||||
C112.38,144.46,110.11,148.18,108.66,152.02z"/>
|
||||
<path class="st1" d="M576.8,106.02c7.41-0.05,14.82,0,22.23-0.03c5.88,0.13,12.29,2.07,15.81,7.11c5.54,8.26,2.67,21.48-7.11,25.1
|
||||
c4.12,7.54,8.16,15.13,12.08,22.78c-4.18,0.02-8.36,0.07-12.52-0.03c-3.44-6.64-6.72-13.35-10.26-19.94
|
||||
c-2.95-0.02-5.89-0.04-8.82,0.02c-0.01,6.65,0.01,13.3-0.01,19.96c-3.8,0.02-7.6,0.02-11.4-0.01
|
||||
C576.78,142.66,576.78,124.34,576.8,106.02 M588.21,115.03c0,5.65-0.01,11.3,0,16.95c4.55-0.31,9.38,0.89,13.68-0.96
|
||||
c5.29-2.47,5.64-10.71,1.37-14.29C598.83,113.73,593.22,115.42,588.21,115.03z"/>
|
||||
<path class="st1" d="M634.46,106.09c3.8-0.2,7.62-0.06,11.44-0.07c0.01,18.32,0.01,36.64,0,54.96c-3.72,0.04-7.43,0.01-11.13,0.02
|
||||
l-0.31-0.36C634.52,142.46,634.51,124.27,634.46,106.09z"/>
|
||||
<path class="st1" d="M663.8,106.01c8.13-0.03,16.26,0,24.39-0.01c4.97,0.61,10.12,2.42,13.55,6.32c6.42,7.2,5.48,20.24-3.06,25.4
|
||||
c-7.01,4.5-15.6,3.01-23.47,3.3c-0.01,6.66,0.01,13.31-0.01,19.97c-3.8,0.02-7.6,0.02-11.4,0
|
||||
C663.78,142.66,663.78,124.34,663.8,106.01 M675.21,115.02c-0.01,5.65,0,11.3,0,16.95c4.89-0.21,9.96,0.7,14.67-0.71
|
||||
c6.17-2.5,5.84-12.44,0.04-15.21C685.29,114.05,680.1,115.36,675.21,115.02z"/>
|
||||
</g>
|
||||
<g>
|
||||
<g>
|
||||
<path class="st2" d="M222.37,146.41c-0.37-7.72-6.82-9.57-14.47-11.47c-14.79-1.47-26.9-14.31-13.76-26.02
|
||||
c10.72-8.47,34.44-4.24,33.98,12.08h-6.05c0.06-18.2-38.39-11.92-24.28,4.72c9.12,5.92,31.39,4.84,30.63,20.39
|
||||
c-0.31,21.37-41.72,19.73-41.49-1.11h6.05C193.13,159.27,221.37,160.43,222.37,146.41z"/>
|
||||
<path class="st2" d="M262,91v14h12v5h-12v36.83c-0.4,8.19,4.63,10.28,11.94,8.58l0.25,4.96c-9.68,3.27-19.28-1.68-18.21-13.53
|
||||
c0,0,0-36.84,0-36.84H246v-5h10V91H262z"/>
|
||||
<path class="st2" d="M322.64,110.18c-28.51-4.75-17.52,34.44-19.54,49.82H297v-55h6l0.1,8.74c3.48-7.59,11.86-11.46,19.69-9.1
|
||||
L322.64,110.18z"/>
|
||||
<path class="st2" d="M363.41,161.08c-21.91,0.67-29.94-26.47-21.56-43.37c13.58-25.28,45.68-13.11,42.17,15.29h-39.2
|
||||
c-2.08,19.59,21.82,31.69,34.23,15.49l3.81,2.89C378.4,157.85,371.91,161.08,363.41,161.08z M362.3,109.46
|
||||
c-10.12,0.02-16.16,8.52-17.27,18.54h32.96C378.08,118.24,372.38,109.36,362.3,109.46z"/>
|
||||
<path class="st2" d="M441.23,160c-0.61-1.74-1.01-4.31-1.17-7.71c-9.1,13.08-36.59,11.79-36.58-6.95
|
||||
c0.24-17.92,22.23-17.99,36.53-17.47v-6.28c1.4-16.62-28.25-16.84-29.07-1.58l-6.13-0.05c0.21-15.94,25.54-20.87,35.78-11.62
|
||||
c11.18,9.79,1.91,39.18,7.18,51.67H441.23z M422.12,155.83c7.6,0.09,14.88-3.96,17.88-10.82c0,0,0-12.09,0-12.09
|
||||
c-7.25-0.03-19.87-0.62-25.09,3.33C404.85,142.2,410.94,156.83,422.12,155.83z"/>
|
||||
<path class="st2" d="M478.75,105l0.2,8.95c6.5-12.93,29.79-13.88,33.75,0.71c3.8-6.84,10.76-10.71,18.45-10.67
|
||||
c26.44-1.62,15.64,39.94,17.75,56.02H544v-36.21c-0.15-9.53-3.53-14.45-13.15-14.47c-8.1-0.07-15.28,6.23-15.85,14.32
|
||||
c0,0,0,36.36,0,36.36h-7v-36.66c-0.09-9.21-4.06-14-13.25-14.02c-8.11,0.03-13.36,4.99-15.75,13c0,0,0,37.68,0,37.68h-6v-55
|
||||
H478.75z"/>
|
||||
</g>
|
||||
<g>
|
||||
<linearGradient id="SVGID_1_" gradientUnits="userSpaceOnUse" x1="186.9279" y1="133.0317" x2="550.2825" y2="133.0317">
|
||||
<stop offset="0" style="stop-color:#FCAA62"/>
|
||||
<stop offset="0.148" style="stop-color:#EF9589"/>
|
||||
<stop offset="0.2709" style="stop-color:#E588A4"/>
|
||||
<stop offset="0.4218" style="stop-color:#D17AC7"/>
|
||||
<stop offset="0.5335" style="stop-color:#AC83D0"/>
|
||||
<stop offset="0.8547" style="stop-color:#4DBFC8"/>
|
||||
</linearGradient>
|
||||
<path class="st3" d="M222.37,146.41c-0.37-7.72-6.82-9.57-14.47-11.47c-14.79-1.47-26.9-14.31-13.76-26.02
|
||||
c10.72-8.47,34.44-4.24,33.98,12.08h-6.05c0.06-18.2-38.39-11.92-24.28,4.72c9.12,5.92,31.39,4.84,30.63,20.39
|
||||
c-0.31,21.37-41.72,19.73-41.49-1.11h6.05C193.13,159.27,221.37,160.43,222.37,146.41z"/>
|
||||
|
||||
<linearGradient id="SVGID_00000103946862931371191510000000729465072844906368_" gradientUnits="userSpaceOnUse" x1="191.9648" y1="126.1764" x2="544.4528" y2="126.1764">
|
||||
<stop offset="0" style="stop-color:#FCAA62"/>
|
||||
<stop offset="0.148" style="stop-color:#EF9589"/>
|
||||
<stop offset="0.2709" style="stop-color:#E588A4"/>
|
||||
<stop offset="0.4218" style="stop-color:#D17AC7"/>
|
||||
<stop offset="0.5335" style="stop-color:#AC83D0"/>
|
||||
<stop offset="0.8547" style="stop-color:#4DBFC8"/>
|
||||
</linearGradient>
|
||||
<path style="fill:url(#SVGID_00000103946862931371191510000000729465072844906368_);" d="M262,91v14h12v5h-12v36.83
|
||||
c-0.4,8.19,4.63,10.28,11.94,8.58l0.25,4.96c-9.68,3.27-19.28-1.68-18.21-13.53c0,0,0-36.84,0-36.84H246v-5h10V91H262z"/>
|
||||
|
||||
<linearGradient id="SVGID_00000176721575697468656650000009150589237067441335_" gradientUnits="userSpaceOnUse" x1="190.9367" y1="131.9768" x2="549.0467" y2="131.9768">
|
||||
<stop offset="0" style="stop-color:#FCAA62"/>
|
||||
<stop offset="0.148" style="stop-color:#EF9589"/>
|
||||
<stop offset="0.2709" style="stop-color:#E588A4"/>
|
||||
<stop offset="0.4218" style="stop-color:#D17AC7"/>
|
||||
<stop offset="0.5335" style="stop-color:#AC83D0"/>
|
||||
<stop offset="0.8547" style="stop-color:#4DBFC8"/>
|
||||
</linearGradient>
|
||||
<path style="fill:url(#SVGID_00000176721575697468656650000009150589237067441335_);" d="M322.64,110.18
|
||||
c-28.51-4.75-17.52,34.44-19.54,49.82H297v-55h6l0.1,8.74c3.48-7.59,11.86-11.46,19.69-9.1L322.64,110.18z"/>
|
||||
|
||||
<linearGradient id="SVGID_00000079455930380207591750000003505925285802537364_" gradientUnits="userSpaceOnUse" x1="196.2564" y1="132.5227" x2="548.9808" y2="132.5227">
|
||||
<stop offset="0" style="stop-color:#FCAA62"/>
|
||||
<stop offset="0.148" style="stop-color:#EF9589"/>
|
||||
<stop offset="0.2709" style="stop-color:#E588A4"/>
|
||||
<stop offset="0.4218" style="stop-color:#D17AC7"/>
|
||||
<stop offset="0.5335" style="stop-color:#AC83D0"/>
|
||||
<stop offset="0.8547" style="stop-color:#4DBFC8"/>
|
||||
</linearGradient>
|
||||
<path style="fill:url(#SVGID_00000079455930380207591750000003505925285802537364_);" d="M363.41,161.08
|
||||
c-21.91,0.67-29.94-26.47-21.56-43.37c13.58-25.28,45.68-13.11,42.17,15.29h-39.2c-2.08,19.59,21.82,31.69,34.23,15.49l3.81,2.89
|
||||
C378.4,157.85,371.91,161.08,363.41,161.08z M362.3,109.46c-10.12,0.02-16.16,8.52-17.27,18.54h32.96
|
||||
C378.08,118.24,372.38,109.36,362.3,109.46z"/>
|
||||
|
||||
<linearGradient id="SVGID_00000027569275093958031240000016844973093868673714_" gradientUnits="userSpaceOnUse" x1="190.8339" y1="132.3138" x2="549.086" y2="132.3138">
|
||||
<stop offset="0" style="stop-color:#FCAA62"/>
|
||||
<stop offset="0.148" style="stop-color:#EF9589"/>
|
||||
<stop offset="0.2709" style="stop-color:#E588A4"/>
|
||||
<stop offset="0.4218" style="stop-color:#D17AC7"/>
|
||||
<stop offset="0.5335" style="stop-color:#AC83D0"/>
|
||||
<stop offset="0.8547" style="stop-color:#4DBFC8"/>
|
||||
</linearGradient>
|
||||
<path style="fill:url(#SVGID_00000027569275093958031240000016844973093868673714_);" d="M441.23,160
|
||||
c-0.61-1.74-1.01-4.31-1.17-7.71c-9.1,13.08-36.59,11.79-36.58-6.95c0.24-17.92,22.23-17.99,36.53-17.47v-6.28
|
||||
c1.4-16.62-28.25-16.84-29.07-1.58l-6.13-0.05c0.21-15.94,25.54-20.87,35.78-11.62c11.18,9.79,1.91,39.18,7.18,51.67H441.23z
|
||||
M422.12,155.83c7.6,0.09,14.88-3.96,17.88-10.82c0,0,0-12.09,0-12.09c-7.25-0.03-19.87-0.62-25.09,3.33
|
||||
C404.85,142.2,410.94,156.83,422.12,155.83z"/>
|
||||
|
||||
<linearGradient id="SVGID_00000170236692072998314540000006170404067406300812_" gradientUnits="userSpaceOnUse" x1="197.2366" y1="131.9687" x2="549.7985" y2="131.9687">
|
||||
<stop offset="0" style="stop-color:#FCAA62"/>
|
||||
<stop offset="0.148" style="stop-color:#EF9589"/>
|
||||
<stop offset="0.2709" style="stop-color:#E588A4"/>
|
||||
<stop offset="0.4218" style="stop-color:#D17AC7"/>
|
||||
<stop offset="0.5335" style="stop-color:#AC83D0"/>
|
||||
<stop offset="0.8547" style="stop-color:#4DBFC8"/>
|
||||
</linearGradient>
|
||||
<path style="fill:url(#SVGID_00000170236692072998314540000006170404067406300812_);" d="M478.75,105l0.2,8.95
|
||||
c6.5-12.93,29.79-13.88,33.75,0.71c3.8-6.84,10.76-10.71,18.45-10.67c26.44-1.62,15.64,39.94,17.75,56.02H544v-36.21
|
||||
c-0.15-9.53-3.53-14.45-13.15-14.47c-8.1-0.07-15.28,6.23-15.85,14.32c0,0,0,36.36,0,36.36h-7v-36.66
|
||||
c-0.09-9.21-4.06-14-13.25-14.02c-8.11,0.03-13.36,4.99-15.75,13c0,0,0,37.68,0,37.68h-6v-55H478.75z"/>
|
||||
</g>
|
||||
</g>
|
||||
</svg>
|
||||
|
After Width: | Height: | Size: 9.9 KiB |
{kind=link}
|
After Width: | Height: | Size: 475 KiB |
|
|
@ -1,62 +1,91 @@
|
|||
[tool.poetry]
|
||||
name = "streamrip"
|
||||
version = "1.9.5"
|
||||
version = "2.0.5"
|
||||
description = "A fast, all-in-one music ripper for Qobuz, Deezer, Tidal, and SoundCloud"
|
||||
authors = ["nathom <nathanthomas707@gmail.com>"]
|
||||
license = "GPL-3.0-only"
|
||||
readme = "README.md"
|
||||
homepage = "https://github.com/nathom/streamrip"
|
||||
repository = "https://github.com/nathom/streamrip"
|
||||
include = ["streamrip/config.toml"]
|
||||
packages = [
|
||||
{ include = "streamrip" },
|
||||
{ include = "rip" },
|
||||
]
|
||||
include = ["src/config.toml"]
|
||||
keywords = ["hi-res", "free", "music", "download"]
|
||||
classifiers = [
|
||||
"License :: OSI Approved :: GNU General Public License (GPL)",
|
||||
"Operating System :: OS Independent",
|
||||
"License :: OSI Approved :: GNU General Public License (GPL)",
|
||||
"Operating System :: OS Independent",
|
||||
]
|
||||
packages = [{ include = "streamrip" }]
|
||||
|
||||
[tool.poetry.scripts]
|
||||
rip = "rip.cli:main"
|
||||
rip = "streamrip.rip:rip"
|
||||
|
||||
[tool.poetry.dependencies]
|
||||
python = ">=3.8 <4.0"
|
||||
requests = "^2.25.1"
|
||||
python = ">=3.10 <4.0"
|
||||
mutagen = "^1.45.1"
|
||||
click = "^8.0.1"
|
||||
tqdm = "^4.61.1"
|
||||
tomlkit = "^0.7.2"
|
||||
pathvalidate = "^2.4.1"
|
||||
simple-term-menu = {version = "^1.2.1", platform = 'darwin|linux'}
|
||||
pick = {version = "^1.0.0", platform = 'win32 or cygwin'}
|
||||
windows-curses = {version = "^2.2.0", platform = 'win32|cygwin'}
|
||||
Pillow = "^9.0.0"
|
||||
simple-term-menu = { version = "^1.2.1", platform = 'darwin|linux' }
|
||||
pick = { version = "^2", platform = 'win32|cygwin' }
|
||||
windows-curses = { version = "^2.2.0", platform = 'win32|cygwin' }
|
||||
Pillow = ">=9,<11"
|
||||
deezer-py = "1.3.6"
|
||||
pycryptodomex = "^3.10.1"
|
||||
cleo = {version = "1.0.0a4", allow-prereleases = true}
|
||||
appdirs = "^1.4.4"
|
||||
m3u8 = "^0.9.0"
|
||||
aiofiles = "^0.7.0"
|
||||
aiohttp = "^3.7.4"
|
||||
cchardet = "^2.1.7"
|
||||
aiofiles = "^0.7"
|
||||
aiohttp = "^3.9"
|
||||
aiodns = "^3.0.0"
|
||||
aiolimiter = "^1.1.0"
|
||||
pytest-mock = "^3.11.1"
|
||||
pytest-asyncio = "^0.21.1"
|
||||
rich = "^13.6.0"
|
||||
click-help-colors = "^0.9.2"
|
||||
|
||||
[tool.poetry.urls]
|
||||
"Bug Reports" = "https://github.com/nathom/streamrip/issues"
|
||||
|
||||
[tool.poetry.dev-dependencies]
|
||||
Sphinx = "^4.1.1"
|
||||
autodoc = "^0.5.0"
|
||||
types-click = "^7.1.2"
|
||||
types-Pillow = "^8.3.1"
|
||||
black = "^21.7b0"
|
||||
ruff = "^0.1"
|
||||
black = "^24"
|
||||
isort = "^5.9.3"
|
||||
flake8 = "^3.9.2"
|
||||
setuptools = "^58.0.4"
|
||||
pytest = "^6.2.5"
|
||||
setuptools = "^67.4.0"
|
||||
pytest = "^7.4"
|
||||
|
||||
[tool.pytest.ini_options]
|
||||
minversion = "6.0"
|
||||
addopts = "-ra -q"
|
||||
testpaths = ["tests"]
|
||||
log_level = "DEBUG"
|
||||
asyncio_mode = 'auto'
|
||||
log_cli = true
|
||||
|
||||
[build-system]
|
||||
requires = ["poetry-core>=1.0.0"]
|
||||
build-backend = "poetry.core.masonry.api"
|
||||
|
||||
[tool.ruff.lint]
|
||||
# Enable Pyflakes (`F`) and a subset of the pycodestyle (`E`) codes by default.
|
||||
select = ["E4", "E7", "E9", "F", "I", "ASYNC", "N", "RUF", "ERA001"]
|
||||
ignore = []
|
||||
|
||||
# Allow fix for all enabled rules (when `--fix`) is provided.
|
||||
fixable = ["ALL"]
|
||||
unfixable = []
|
||||
|
||||
# Allow unused variables when underscore-prefixed.
|
||||
dummy-variable-rgx = "^(_+|(_+[a-zA-Z0-9_]*[a-zA-Z0-9]+?))$"
|
||||
|
||||
[tool.ruff.format]
|
||||
# Like Black, use double quotes for strings.
|
||||
quote-style = "double"
|
||||
|
||||
# Like Black, indent with spaces, rather than tabs.
|
||||
indent-style = "space"
|
||||
|
||||
# Like Black, respect magic trailing commas.
|
||||
skip-magic-trailing-comma = false
|
||||
|
||||
# Like Black, automatically detect the appropriate line ending.
|
||||
line-ending = "auto"
|
||||
|
|
|
|||
|
|
@ -1 +0,0 @@
|
|||
"""Rip: an easy to use command line utility for downloading audio streams."""
|
||||
|
|
@ -1,4 +0,0 @@
|
|||
"""Run the rip program."""
|
||||
from .cli import main
|
||||
|
||||
main()
|
||||
834
rip/cli.py
|
|
@ -1,834 +0,0 @@
|
|||
import concurrent.futures
|
||||
import logging
|
||||
import os
|
||||
import threading
|
||||
from typing import Optional
|
||||
|
||||
import requests
|
||||
from cleo.application import Application as BaseApplication
|
||||
from cleo.commands.command import Command
|
||||
from cleo.formatters.style import Style
|
||||
from cleo.helpers import argument, option
|
||||
from click import launch
|
||||
|
||||
from streamrip import __version__
|
||||
|
||||
from .config import Config
|
||||
from .core import RipCore
|
||||
|
||||
logging.basicConfig(level="WARNING")
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
outdated = False
|
||||
newest_version = __version__
|
||||
|
||||
|
||||
class DownloadCommand(Command):
|
||||
name = "url"
|
||||
description = "Download items using urls."
|
||||
|
||||
arguments = [
|
||||
argument(
|
||||
"urls",
|
||||
"One or more Qobuz, Tidal, Deezer, or SoundCloud urls",
|
||||
optional=True,
|
||||
multiple=True,
|
||||
)
|
||||
]
|
||||
options = [
|
||||
option(
|
||||
"file",
|
||||
"-f",
|
||||
"Path to a text file containing urls",
|
||||
flag=False,
|
||||
default="None",
|
||||
),
|
||||
option(
|
||||
"codec",
|
||||
"-c",
|
||||
"Convert the downloaded files to <cmd>ALAC</cmd>, <cmd>FLAC</cmd>, <cmd>MP3</cmd>, <cmd>AAC</cmd>, or <cmd>OGG</cmd>",
|
||||
flag=False,
|
||||
default="None",
|
||||
),
|
||||
option(
|
||||
"max-quality",
|
||||
"m",
|
||||
"The maximum quality to download. Can be <cmd>0</cmd>, <cmd>1</cmd>, <cmd>2</cmd>, <cmd>3 </cmd>or <cmd>4</cmd>",
|
||||
flag=False,
|
||||
default="None",
|
||||
),
|
||||
option(
|
||||
"ignore-db",
|
||||
"-i",
|
||||
description="Download items even if they have been logged in the database.",
|
||||
),
|
||||
option("config", description="Path to config file.", flag=False),
|
||||
option("directory", "-d", "Directory to download items into.", flag=False),
|
||||
]
|
||||
|
||||
help = (
|
||||
"\nDownload <title>Dreams</title> by <title>Fleetwood Mac</title>:\n"
|
||||
"$ <cmd>rip url https://www.deezer.com/us/track/67549262</cmd>\n\n"
|
||||
"Batch download urls from a text file named <path>urls.txt</path>:\n"
|
||||
"$ <cmd>rip url --file urls.txt</cmd>\n\n"
|
||||
"For more information on Quality IDs, see\n"
|
||||
"<url>https://github.com/nathom/streamrip/wiki/Quality-IDs</url>\n"
|
||||
)
|
||||
|
||||
def handle(self):
|
||||
global outdated
|
||||
global newest_version
|
||||
|
||||
# Use a thread so that it doesn't slow down startup
|
||||
update_check = threading.Thread(target=is_outdated, daemon=True)
|
||||
update_check.start()
|
||||
|
||||
path, codec, quality, no_db, directory, config = clean_options(
|
||||
self.option("file"),
|
||||
self.option("codec"),
|
||||
self.option("max-quality"),
|
||||
self.option("ignore-db"),
|
||||
self.option("directory"),
|
||||
self.option("config"),
|
||||
)
|
||||
|
||||
config = Config(config)
|
||||
|
||||
if directory is not None:
|
||||
config.session["downloads"]["folder"] = directory
|
||||
|
||||
if no_db:
|
||||
config.session["database"]["enabled"] = False
|
||||
|
||||
if quality is not None:
|
||||
for source in ("qobuz", "tidal", "deezer"):
|
||||
config.session[source]["quality"] = quality
|
||||
|
||||
core = RipCore(config)
|
||||
|
||||
urls = self.argument("urls")
|
||||
|
||||
if path is not None:
|
||||
if os.path.isfile(path):
|
||||
core.handle_txt(path)
|
||||
else:
|
||||
self.line(
|
||||
f"<error>File <comment>{path}</comment> does not exist.</error>"
|
||||
)
|
||||
return 1
|
||||
|
||||
if urls:
|
||||
core.handle_urls(";".join(urls))
|
||||
|
||||
if len(core) > 0:
|
||||
core.download()
|
||||
elif not urls and path is None:
|
||||
self.line("<error>Must pass arguments. See </><cmd>rip url -h</cmd>.")
|
||||
|
||||
update_check.join()
|
||||
if outdated:
|
||||
import re
|
||||
import subprocess
|
||||
|
||||
self.line(
|
||||
f"\n<info>A new version of streamrip <title>v{newest_version}</title>"
|
||||
" is available! Run <cmd>pip3 install streamrip --upgrade</cmd>"
|
||||
" to update.</info>\n"
|
||||
)
|
||||
|
||||
md_header = re.compile(r"#\s+(.+)")
|
||||
bullet_point = re.compile(r"-\s+(.+)")
|
||||
code = re.compile(r"`([^`]+)`")
|
||||
issue_reference = re.compile(r"(#\d+)")
|
||||
|
||||
release_notes = requests.get(
|
||||
"https://api.github.com/repos/nathom/streamrip/releases/latest"
|
||||
).json()["body"]
|
||||
|
||||
release_notes = md_header.sub(r"<header>\1</header>", release_notes)
|
||||
release_notes = bullet_point.sub(r"<options=bold>•</> \1", release_notes)
|
||||
release_notes = code.sub(r"<cmd>\1</cmd>", release_notes)
|
||||
release_notes = issue_reference.sub(r"<options=bold>\1</>", release_notes)
|
||||
|
||||
self.line(release_notes)
|
||||
|
||||
return 0
|
||||
|
||||
|
||||
class SearchCommand(Command):
|
||||
name = "search"
|
||||
description = "Search for an item"
|
||||
arguments = [
|
||||
argument(
|
||||
"query",
|
||||
"The name to search for",
|
||||
optional=False,
|
||||
multiple=False,
|
||||
)
|
||||
]
|
||||
options = [
|
||||
option(
|
||||
"source",
|
||||
"-s",
|
||||
"Qobuz, Tidal, Soundcloud, Deezer, or Deezloader",
|
||||
flag=False,
|
||||
default="qobuz",
|
||||
),
|
||||
option(
|
||||
"type",
|
||||
"-t",
|
||||
"Album, Playlist, Track, or Artist",
|
||||
flag=False,
|
||||
default="album",
|
||||
),
|
||||
]
|
||||
|
||||
help = (
|
||||
"\nSearch for <title>Rumours</title> by <title>Fleetwood Mac</title>\n"
|
||||
"$ <cmd>rip search 'rumours fleetwood mac'</cmd>\n\n"
|
||||
"Search for <title>444</title> by <title>Jay-Z</title> on TIDAL\n"
|
||||
"$ <cmd>rip search --source tidal '444'</cmd>\n\n"
|
||||
"Search for <title>Bob Dylan</title> on Deezer\n"
|
||||
"$ <cmd>rip search --type artist --source deezer 'bob dylan'</cmd>\n"
|
||||
)
|
||||
|
||||
def handle(self):
|
||||
query = self.argument("query")
|
||||
source, type = clean_options(self.option("source"), self.option("type"))
|
||||
|
||||
config = Config()
|
||||
core = RipCore(config)
|
||||
|
||||
if core.interactive_search(query, source, type):
|
||||
core.download()
|
||||
else:
|
||||
self.line("<error>No items chosen, exiting.</error>")
|
||||
|
||||
|
||||
class DiscoverCommand(Command):
|
||||
name = "discover"
|
||||
description = "Download items from the charts or a curated playlist"
|
||||
arguments = [
|
||||
argument(
|
||||
"list",
|
||||
"The list to fetch",
|
||||
optional=True,
|
||||
multiple=False,
|
||||
default="ideal-discography",
|
||||
)
|
||||
]
|
||||
options = [
|
||||
option(
|
||||
"scrape",
|
||||
description="Download all of the items in the list",
|
||||
),
|
||||
option(
|
||||
"max-items",
|
||||
"-m",
|
||||
description="The number of items to fetch",
|
||||
flag=False,
|
||||
default=50,
|
||||
),
|
||||
option(
|
||||
"source",
|
||||
"-s",
|
||||
description="The source to download from (<cmd>qobuz</cmd> or <cmd>deezer</cmd>)",
|
||||
flag=False,
|
||||
default="qobuz",
|
||||
),
|
||||
]
|
||||
help = (
|
||||
"\nBrowse the Qobuz ideal-discography list\n"
|
||||
"$ <cmd>rip discover</cmd>\n\n"
|
||||
"Browse the best-sellers list\n"
|
||||
"$ <cmd>rip discover best-sellers</cmd>\n\n"
|
||||
"Available options for Qobuz <cmd>list</cmd>:\n\n"
|
||||
" • most-streamed\n"
|
||||
" • recent-releases\n"
|
||||
" • best-sellers\n"
|
||||
" • press-awards\n"
|
||||
" • ideal-discography\n"
|
||||
" • editor-picks\n"
|
||||
" • most-featured\n"
|
||||
" • qobuzissims\n"
|
||||
" • new-releases\n"
|
||||
" • new-releases-full\n"
|
||||
" • harmonia-mundi\n"
|
||||
" • universal-classic\n"
|
||||
" • universal-jazz\n"
|
||||
" • universal-jeunesse\n"
|
||||
" • universal-chanson\n\n"
|
||||
"Browse the Deezer editorial releases list\n"
|
||||
"$ <cmd>rip discover --source deezer</cmd>\n\n"
|
||||
"Browse the Deezer charts\n"
|
||||
"$ <cmd>rip discover --source deezer charts</cmd>\n\n"
|
||||
"Available options for Deezer <cmd>list</cmd>:\n\n"
|
||||
" • releases\n"
|
||||
" • charts\n"
|
||||
" • selection\n"
|
||||
)
|
||||
|
||||
def handle(self):
|
||||
source = self.option("source")
|
||||
scrape = self.option("scrape")
|
||||
chosen_list = self.argument("list")
|
||||
max_items = self.option("max-items")
|
||||
|
||||
if source == "qobuz":
|
||||
from streamrip.constants import QOBUZ_FEATURED_KEYS
|
||||
|
||||
if chosen_list not in QOBUZ_FEATURED_KEYS:
|
||||
self.line(f'<error>Error: list "{chosen_list}" not available</error>')
|
||||
self.line(self.help)
|
||||
return 1
|
||||
elif source == "deezer":
|
||||
from streamrip.constants import DEEZER_FEATURED_KEYS
|
||||
|
||||
if chosen_list not in DEEZER_FEATURED_KEYS:
|
||||
self.line(f'<error>Error: list "{chosen_list}" not available</error>')
|
||||
self.line(self.help)
|
||||
return 1
|
||||
|
||||
else:
|
||||
self.line(
|
||||
"<error>Invalid source. Choose either <cmd>qobuz</cmd> or <cmd>deezer</cmd></error>"
|
||||
)
|
||||
return 1
|
||||
|
||||
config = Config()
|
||||
core = RipCore(config)
|
||||
|
||||
if scrape:
|
||||
core.scrape(chosen_list, max_items)
|
||||
core.download()
|
||||
return 0
|
||||
|
||||
if core.interactive_search(
|
||||
chosen_list, source, "featured", limit=int(max_items)
|
||||
):
|
||||
core.download()
|
||||
else:
|
||||
self.line("<error>No items chosen, exiting.</error>")
|
||||
|
||||
return 0
|
||||
|
||||
|
||||
class LastfmCommand(Command):
|
||||
name = "lastfm"
|
||||
description = "Search for tracks from a last.fm playlist and download them."
|
||||
|
||||
arguments = [
|
||||
argument(
|
||||
"urls",
|
||||
"Last.fm playlist urls",
|
||||
optional=False,
|
||||
multiple=True,
|
||||
)
|
||||
]
|
||||
options = [
|
||||
option(
|
||||
"source",
|
||||
"-s",
|
||||
description="The source to search for items on",
|
||||
flag=False,
|
||||
default="qobuz",
|
||||
),
|
||||
]
|
||||
help = (
|
||||
"You can use this command to download Spotify, Apple Music, and YouTube "
|
||||
"playlists.\nTo get started, create an account at "
|
||||
"<url>https://www.last.fm</url>. Once you have\nreached the home page, "
|
||||
"go to <path>Profile Icon</path> => <path>View profile</path> => "
|
||||
"<path>Playlists</path> => <path>IMPORT</path>\nand paste your url.\n\n"
|
||||
"Download the <info>young & free</info> Apple Music playlist (already imported)\n"
|
||||
"$ <cmd>rip lastfm https://www.last.fm/user/nathan3895/playlists/12089888</cmd>\n"
|
||||
)
|
||||
|
||||
def handle(self):
|
||||
source = self.option("source")
|
||||
urls = self.argument("urls")
|
||||
|
||||
config = Config()
|
||||
core = RipCore(config)
|
||||
config.session["lastfm"]["source"] = source
|
||||
core.handle_lastfm_urls(";".join(urls))
|
||||
core.download()
|
||||
|
||||
|
||||
class ConfigCommand(Command):
|
||||
name = "config"
|
||||
description = "Manage the configuration file."
|
||||
|
||||
options = [
|
||||
option(
|
||||
"open",
|
||||
"-o",
|
||||
description="Open the config file in the default application",
|
||||
flag=True,
|
||||
),
|
||||
option(
|
||||
"open-vim",
|
||||
"-O",
|
||||
description="Open the config file in (neo)vim",
|
||||
flag=True,
|
||||
),
|
||||
option(
|
||||
"directory",
|
||||
"-d",
|
||||
description="Open the directory that the config file is located in",
|
||||
flag=True,
|
||||
),
|
||||
option("path", "-p", description="Show the config file's path", flag=True),
|
||||
option("qobuz", description="Set the credentials for Qobuz", flag=True),
|
||||
option("tidal", description="Log into Tidal", flag=True),
|
||||
option("deezer", description="Set the Deezer ARL", flag=True),
|
||||
option(
|
||||
"music-app",
|
||||
description="Configure the config file for usage with the macOS Music App",
|
||||
flag=True,
|
||||
),
|
||||
option("reset", description="Reset the config file", flag=True),
|
||||
option(
|
||||
"--update",
|
||||
description="Reset the config file, keeping the credentials",
|
||||
flag=True,
|
||||
),
|
||||
]
|
||||
"""
|
||||
Manage the configuration file.
|
||||
|
||||
config
|
||||
{--o|open : Open the config file in the default application}
|
||||
{--O|open-vim : Open the config file in (neo)vim}
|
||||
{--d|directory : Open the directory that the config file is located in}
|
||||
{--p|path : Show the config file's path}
|
||||
{--qobuz : Set the credentials for Qobuz}
|
||||
{--tidal : Log into Tidal}
|
||||
{--deezer : Set the Deezer ARL}
|
||||
{--music-app : Configure the config file for usage with the macOS Music App}
|
||||
{--reset : Reset the config file}
|
||||
{--update : Reset the config file, keeping the credentials}
|
||||
"""
|
||||
|
||||
_config: Optional[Config]
|
||||
|
||||
def handle(self):
|
||||
import shutil
|
||||
|
||||
from .constants import CONFIG_DIR, CONFIG_PATH
|
||||
|
||||
self._config = Config()
|
||||
|
||||
if self.option("path"):
|
||||
self.line(f"<info>{CONFIG_PATH}</info>")
|
||||
|
||||
if self.option("open"):
|
||||
self.line(f"Opening <url>{CONFIG_PATH}</url> in default application")
|
||||
launch(CONFIG_PATH)
|
||||
|
||||
if self.option("reset"):
|
||||
self._config.reset()
|
||||
|
||||
if self.option("update"):
|
||||
self._config.update()
|
||||
|
||||
if self.option("open-vim"):
|
||||
if shutil.which("nvim") is not None:
|
||||
os.system(f"nvim '{CONFIG_PATH}'")
|
||||
else:
|
||||
os.system(f"vim '{CONFIG_PATH}'")
|
||||
|
||||
if self.option("directory"):
|
||||
self.line(f"Opening <url>{CONFIG_DIR}</url>")
|
||||
launch(CONFIG_DIR)
|
||||
|
||||
if self.option("tidal"):
|
||||
from streamrip.clients import TidalClient
|
||||
|
||||
client = TidalClient()
|
||||
client.login()
|
||||
self._config.file["tidal"].update(client.get_tokens())
|
||||
self._config.save()
|
||||
self.line("<info>Credentials saved to config.</info>")
|
||||
|
||||
if self.option("deezer"):
|
||||
from streamrip.clients import DeezerClient
|
||||
from streamrip.exceptions import AuthenticationError
|
||||
|
||||
self.line(
|
||||
"Follow the instructions at <url>https://github.com"
|
||||
"/nathom/streamrip/wiki/Finding-your-Deezer-ARL-Cookie</url>"
|
||||
)
|
||||
|
||||
given_arl = self.ask("Paste your ARL here: ").strip()
|
||||
self.line("<comment>Validating arl...</comment>")
|
||||
|
||||
try:
|
||||
DeezerClient().login(arl=given_arl)
|
||||
self._config.file["deezer"]["arl"] = given_arl
|
||||
self._config.save()
|
||||
self.line("<b>Sucessfully logged in!</b>")
|
||||
|
||||
except AuthenticationError:
|
||||
self.line("<error>Could not log in. Double check your ARL</error>")
|
||||
|
||||
if self.option("qobuz"):
|
||||
import getpass
|
||||
import hashlib
|
||||
|
||||
self._config.file["qobuz"]["email"] = self.ask("Qobuz email:")
|
||||
self._config.file["qobuz"]["password"] = hashlib.md5(
|
||||
getpass.getpass("Qobuz password (won't show on screen): ").encode()
|
||||
).hexdigest()
|
||||
self._config.save()
|
||||
|
||||
if self.option("music-app"):
|
||||
self._conf_music_app()
|
||||
|
||||
def _conf_music_app(self):
|
||||
import subprocess
|
||||
import xml.etree.ElementTree as ET
|
||||
from pathlib import Path
|
||||
from tempfile import mktemp
|
||||
|
||||
# Find the Music library folder
|
||||
temp_file = mktemp()
|
||||
music_pref_plist = Path(Path.home()) / Path(
|
||||
"Library/Preferences/com.apple.Music.plist"
|
||||
)
|
||||
# copy preferences to tempdir
|
||||
subprocess.run(["cp", music_pref_plist, temp_file])
|
||||
# convert binary to xml for parsing
|
||||
subprocess.run(["plutil", "-convert", "xml1", temp_file])
|
||||
items = iter(ET.parse(temp_file).getroot()[0])
|
||||
|
||||
for item in items:
|
||||
if item.text == "NSNavLastRootDirectory":
|
||||
break
|
||||
|
||||
library_folder = Path(next(items).text)
|
||||
os.remove(temp_file)
|
||||
|
||||
# cp ~/library/preferences/com.apple.music.plist music.plist
|
||||
# plutil -convert xml1 music.plist
|
||||
# cat music.plist | pbcopy
|
||||
|
||||
self._config.file["downloads"]["folder"] = os.path.join(
|
||||
library_folder, "Automatically Add to Music.localized"
|
||||
)
|
||||
|
||||
conversion_config = self._config.file["conversion"]
|
||||
conversion_config["enabled"] = True
|
||||
conversion_config["codec"] = "ALAC"
|
||||
conversion_config["sampling_rate"] = 48000
|
||||
conversion_config["bit_depth"] = 24
|
||||
|
||||
self._config.file["filepaths"]["folder_format"] = ""
|
||||
self._config.file["artwork"]["keep_hires_cover"] = False
|
||||
self._config.save()
|
||||
|
||||
|
||||
class ConvertCommand(Command):
|
||||
name = "convert"
|
||||
description = (
|
||||
"A standalone tool that converts audio files to other codecs en masse."
|
||||
)
|
||||
arguments = [
|
||||
argument(
|
||||
"codec",
|
||||
description="<cmd>FLAC</cmd>, <cmd>ALAC</cmd>, <cmd>OPUS</cmd>, <cmd>MP3</cmd>, or <cmd>AAC</cmd>.",
|
||||
),
|
||||
argument(
|
||||
"path",
|
||||
description="The path to the audio file or a directory that contains audio files.",
|
||||
),
|
||||
]
|
||||
options = [
|
||||
option(
|
||||
"sampling-rate",
|
||||
"-s",
|
||||
description="Downsample the tracks to this rate, in Hz.",
|
||||
default=192000,
|
||||
flag=False,
|
||||
),
|
||||
option(
|
||||
"bit-depth",
|
||||
"-b",
|
||||
description="Downsample the tracks to this bit depth.",
|
||||
default=24,
|
||||
flag=False,
|
||||
),
|
||||
option(
|
||||
"keep-source", "-k", description="Keep the original file after conversion."
|
||||
),
|
||||
]
|
||||
|
||||
help = (
|
||||
"\nConvert all of the audio files in <path>/my/music</path> to MP3s\n"
|
||||
"$ <cmd>rip convert MP3 /my/music</cmd>\n\n"
|
||||
"Downsample the audio to 48kHz after converting them to ALAC\n"
|
||||
"$ <cmd>rip convert --sampling-rate 48000 ALAC /my/music\n"
|
||||
)
|
||||
|
||||
def handle(self):
|
||||
from streamrip import converter
|
||||
|
||||
CODEC_MAP = {
|
||||
"FLAC": converter.FLAC,
|
||||
"ALAC": converter.ALAC,
|
||||
"OPUS": converter.OPUS,
|
||||
"MP3": converter.LAME,
|
||||
"AAC": converter.AAC,
|
||||
}
|
||||
|
||||
codec = self.argument("codec")
|
||||
path = self.argument("path")
|
||||
|
||||
ConverterCls = CODEC_MAP.get(codec.upper())
|
||||
if ConverterCls is None:
|
||||
self.line(
|
||||
f'<error>Invalid codec "{codec}". See </error><cmd>rip convert'
|
||||
" -h</cmd>."
|
||||
)
|
||||
return 1
|
||||
|
||||
sampling_rate, bit_depth, keep_source = clean_options(
|
||||
self.option("sampling-rate"),
|
||||
self.option("bit-depth"),
|
||||
self.option("keep-source"),
|
||||
)
|
||||
|
||||
converter_args = {
|
||||
"sampling_rate": sampling_rate,
|
||||
"bit_depth": bit_depth,
|
||||
"remove_source": not keep_source,
|
||||
}
|
||||
|
||||
if os.path.isdir(path):
|
||||
import itertools
|
||||
from pathlib import Path
|
||||
|
||||
from tqdm import tqdm
|
||||
|
||||
dirname = path
|
||||
audio_extensions = ("flac", "m4a", "aac", "opus", "mp3", "ogg")
|
||||
path_obj = Path(dirname)
|
||||
audio_files = (
|
||||
path.as_posix()
|
||||
for path in itertools.chain.from_iterable(
|
||||
(path_obj.rglob(f"*.{ext}") for ext in audio_extensions)
|
||||
)
|
||||
)
|
||||
|
||||
with concurrent.futures.ThreadPoolExecutor() as executor:
|
||||
futures = []
|
||||
for file in audio_files:
|
||||
futures.append(
|
||||
executor.submit(
|
||||
ConverterCls(
|
||||
filename=os.path.join(dirname, file),
|
||||
**converter_args,
|
||||
).convert
|
||||
)
|
||||
)
|
||||
from streamrip.utils import TQDM_BAR_FORMAT
|
||||
|
||||
for future in tqdm(
|
||||
concurrent.futures.as_completed(futures),
|
||||
total=len(futures),
|
||||
desc="Converting",
|
||||
unit="track",
|
||||
bar_format=TQDM_BAR_FORMAT,
|
||||
):
|
||||
# Only show loading bar
|
||||
future.result()
|
||||
|
||||
elif os.path.isfile(path):
|
||||
ConverterCls(filename=path, **converter_args).convert()
|
||||
else:
|
||||
self.line(
|
||||
f'<error>Path <path>"{path}"</path> does not exist.</error>',
|
||||
fg="red",
|
||||
)
|
||||
|
||||
|
||||
class RepairCommand(Command):
|
||||
name = "repair"
|
||||
description = "Retry failed downloads."
|
||||
|
||||
options = [
|
||||
option(
|
||||
"max-items",
|
||||
"-m",
|
||||
flag=False,
|
||||
description="The maximum number of tracks to download}",
|
||||
default="None",
|
||||
)
|
||||
]
|
||||
|
||||
help = "\nRetry up to 20 failed downloads\n$ <cmd>rip repair --max-items 20</cmd>\n"
|
||||
|
||||
def handle(self):
|
||||
max_items = next(clean_options(self.option("max-items")))
|
||||
config = Config()
|
||||
RipCore(config).repair(max_items=max_items)
|
||||
|
||||
|
||||
class DatabaseCommand(Command):
|
||||
name = "db"
|
||||
description = "View and manage rip's databases."
|
||||
|
||||
arguments = [
|
||||
argument(
|
||||
"name", description="<cmd>downloads</cmd> or <cmd>failed-downloads</cmd>."
|
||||
)
|
||||
]
|
||||
options = [
|
||||
option("list", "-l", description="Display the contents of the database."),
|
||||
option("reset", description="Reset the database."),
|
||||
]
|
||||
|
||||
_table_style = "box-double"
|
||||
|
||||
def handle(self) -> None:
|
||||
from . import db
|
||||
from .config import Config
|
||||
|
||||
config = Config()
|
||||
db_name = self.argument("name").replace("-", "_")
|
||||
|
||||
self._path = config.file["database"][db_name]["path"]
|
||||
self._db = db.CLASS_MAP[db_name](self._path)
|
||||
|
||||
if self.option("list"):
|
||||
getattr(self, f"_render_{db_name}")()
|
||||
|
||||
if self.option("reset"):
|
||||
os.remove(self._path)
|
||||
|
||||
def _render_downloads(self):
|
||||
from cleo.ui.table import Table
|
||||
|
||||
id_table = Table(self._io)
|
||||
id_table.set_style(self._table_style)
|
||||
id_table.set_header_title("IDs")
|
||||
id_table.set_headers(list(self._db.structure.keys()))
|
||||
id_table.add_rows(id for id in iter(self._db) if id[0].isalnum())
|
||||
if id_table._rows:
|
||||
id_table.render()
|
||||
|
||||
url_table = Table(self._io)
|
||||
url_table.set_style(self._table_style)
|
||||
url_table.set_header_title("URLs")
|
||||
url_table.set_headers(list(self._db.structure.keys()))
|
||||
url_table.add_rows(id for id in iter(self._db) if not id[0].isalnum())
|
||||
# prevent wierd formatting
|
||||
if url_table._rows:
|
||||
url_table.render()
|
||||
|
||||
def _render_failed_downloads(self):
|
||||
from cleo.ui.table import Table
|
||||
|
||||
id_table = Table(self._io)
|
||||
id_table.set_style(self._table_style)
|
||||
id_table.set_header_title("Failed Downloads")
|
||||
id_table.set_headers(["Source", "Media Type", "ID"])
|
||||
id_table.add_rows(iter(self._db))
|
||||
id_table.render()
|
||||
|
||||
|
||||
STRING_TO_PRIMITIVE = {
|
||||
"None": None,
|
||||
"True": True,
|
||||
"False": False,
|
||||
}
|
||||
|
||||
|
||||
class Application(BaseApplication):
|
||||
def __init__(self):
|
||||
super().__init__("rip", __version__)
|
||||
|
||||
def _run(self, io):
|
||||
if io.is_debug():
|
||||
from .constants import CONFIG_DIR
|
||||
|
||||
logger.setLevel(logging.DEBUG)
|
||||
fh = logging.FileHandler(os.path.join(CONFIG_DIR, "streamrip.log"))
|
||||
fh.setLevel(logging.DEBUG)
|
||||
logger.addHandler(fh)
|
||||
|
||||
super()._run(io)
|
||||
|
||||
def create_io(self, input=None, output=None, error_output=None):
|
||||
io = super().create_io(input, output, error_output)
|
||||
# Set our own CLI styles
|
||||
formatter = io.output.formatter
|
||||
formatter.set_style("url", Style("blue", options=["underline"]))
|
||||
formatter.set_style("path", Style("green", options=["bold"]))
|
||||
formatter.set_style("cmd", Style("magenta"))
|
||||
formatter.set_style("title", Style("yellow", options=["bold"]))
|
||||
formatter.set_style("header", Style("yellow", options=["bold", "underline"]))
|
||||
io.output.set_formatter(formatter)
|
||||
io.error_output.set_formatter(formatter)
|
||||
|
||||
self._io = io
|
||||
|
||||
return io
|
||||
|
||||
@property
|
||||
def _default_definition(self):
|
||||
default_globals = super()._default_definition
|
||||
# as of 1.0.0a3, the descriptions don't wrap properly
|
||||
# so I'm truncating the description for help as a hack
|
||||
default_globals._options["help"]._description = (
|
||||
default_globals._options["help"]._description.split(".")[0] + "."
|
||||
)
|
||||
|
||||
return default_globals
|
||||
|
||||
def render_error(self, error, io):
|
||||
super().render_error(error, io)
|
||||
io.write_line(
|
||||
"\n<error>If this was unexpected, please open a <path>Bug Report</path> at </error>"
|
||||
"<url>https://github.com/nathom/streamrip/issues/new/choose</url>"
|
||||
)
|
||||
|
||||
|
||||
def clean_options(*opts):
|
||||
for opt in opts:
|
||||
if isinstance(opt, str):
|
||||
if opt.startswith("="):
|
||||
opt = opt[1:]
|
||||
|
||||
opt = opt.strip()
|
||||
if opt.isdigit():
|
||||
opt = int(opt)
|
||||
else:
|
||||
opt = STRING_TO_PRIMITIVE.get(opt, opt)
|
||||
|
||||
yield opt
|
||||
|
||||
|
||||
def is_outdated():
|
||||
global outdated
|
||||
global newest_version
|
||||
r = requests.get("https://pypi.org/pypi/streamrip/json").json()
|
||||
newest_version = r["info"]["version"]
|
||||
outdated = newest_version != __version__
|
||||
|
||||
|
||||
def main():
|
||||
application = Application()
|
||||
application.add(DownloadCommand())
|
||||
application.add(SearchCommand())
|
||||
application.add(DiscoverCommand())
|
||||
application.add(LastfmCommand())
|
||||
application.add(ConfigCommand())
|
||||
application.add(ConvertCommand())
|
||||
application.add(RepairCommand())
|
||||
application.add(DatabaseCommand())
|
||||
application.run()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
196
rip/config.py
|
|
@ -1,196 +0,0 @@
|
|||
"""A config class that manages arguments between the config file and CLI."""
|
||||
|
||||
import copy
|
||||
import logging
|
||||
import os
|
||||
import shutil
|
||||
from pprint import pformat
|
||||
from typing import Any, Dict, List, Union
|
||||
|
||||
import tomlkit
|
||||
from click import secho
|
||||
|
||||
from streamrip.exceptions import InvalidSourceError
|
||||
|
||||
from .constants import CONFIG_DIR, CONFIG_PATH, DOWNLOADS_DIR
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
|
||||
class Config:
|
||||
"""Config class that handles command line args and config files.
|
||||
|
||||
Usage:
|
||||
|
||||
>>> config = Config('test_config.toml')
|
||||
>>> config.defaults['qobuz']['quality']
|
||||
3
|
||||
|
||||
If test_config was already initialized with values, this will load them
|
||||
into `config`. Otherwise, a new config file is created with the default
|
||||
values.
|
||||
"""
|
||||
|
||||
default_config_path = os.path.join(os.path.dirname(__file__), "config.toml")
|
||||
|
||||
with open(default_config_path) as cfg:
|
||||
defaults: Dict[str, Any] = tomlkit.parse(cfg.read().strip())
|
||||
|
||||
def __init__(self, path: str = None):
|
||||
"""Create a Config object with state.
|
||||
|
||||
A TOML file is created at `path` if there is none.
|
||||
|
||||
:param path:
|
||||
:type path: str
|
||||
"""
|
||||
# to access settings loaded from toml file
|
||||
self.file: Dict[str, Any] = copy.deepcopy(self.defaults)
|
||||
self.session: Dict[str, Any] = copy.deepcopy(self.defaults)
|
||||
|
||||
if path is None:
|
||||
self._path = CONFIG_PATH
|
||||
else:
|
||||
self._path = path
|
||||
|
||||
if os.path.isfile(self._path):
|
||||
self.load()
|
||||
if self.file["misc"]["version"] != self.defaults["misc"]["version"]:
|
||||
secho(
|
||||
"Updating config file to new version. Some settings may be lost.",
|
||||
fg="yellow",
|
||||
)
|
||||
self.update()
|
||||
self.load()
|
||||
else:
|
||||
logger.debug("Creating toml config file at '%s'", self._path)
|
||||
os.makedirs(os.path.dirname(self._path), exist_ok=True)
|
||||
shutil.copy(self.default_config_path, self._path)
|
||||
self.load()
|
||||
self.file["downloads"]["folder"] = DOWNLOADS_DIR
|
||||
|
||||
def update(self):
|
||||
"""Reset the config file except for credentials."""
|
||||
# Save original credentials
|
||||
cached_info = self._cache_info(
|
||||
[
|
||||
"qobuz",
|
||||
"tidal",
|
||||
"deezer",
|
||||
"downloads.folder",
|
||||
"filepaths.folder_format",
|
||||
"filepaths.track_format",
|
||||
]
|
||||
)
|
||||
|
||||
# Reset and load config file
|
||||
shutil.copy(self.default_config_path, self._path)
|
||||
self.load()
|
||||
|
||||
self._dump_cached(cached_info)
|
||||
|
||||
self.save()
|
||||
|
||||
def _dot_get(self, dot_key: str) -> Union[dict, str]:
|
||||
"""Get a key from a toml file using section.key format."""
|
||||
item = self.file
|
||||
for key in dot_key.split("."):
|
||||
item = item[key]
|
||||
return item
|
||||
|
||||
def _dot_set(self, dot_key, val):
|
||||
"""Set a key in the toml file using the section.key format."""
|
||||
keys = dot_key.split(".")
|
||||
item = self.file
|
||||
for key in keys[:-1]: # stop at the last one in case it's an immutable
|
||||
item = item[key]
|
||||
|
||||
item[keys[-1]] = val
|
||||
|
||||
def _cache_info(self, keys: List[str]):
|
||||
"""Return a deepcopy of the values from the config to be saved."""
|
||||
return {key: copy.deepcopy(self._dot_get(key)) for key in keys}
|
||||
|
||||
def _dump_cached(self, cached_values):
|
||||
"""Set cached values into the current config file."""
|
||||
for k, v in cached_values.items():
|
||||
self._dot_set(k, v)
|
||||
|
||||
def save(self):
|
||||
"""Save the config state to file."""
|
||||
self.dump(self.file)
|
||||
|
||||
def reset(self):
|
||||
"""Reset the config file."""
|
||||
if not os.path.isdir(CONFIG_DIR):
|
||||
os.makedirs(CONFIG_DIR, exist_ok=True)
|
||||
|
||||
shutil.copy(self.default_config_path, self._path)
|
||||
self.load()
|
||||
self.file["downloads"]["folder"] = DOWNLOADS_DIR
|
||||
self.save()
|
||||
|
||||
def load(self):
|
||||
"""Load infomation from the config files, making a deepcopy."""
|
||||
with open(self._path) as cfg:
|
||||
for k, v in tomlkit.loads(cfg.read().strip()).items():
|
||||
self.file[k] = v
|
||||
if hasattr(v, "copy"):
|
||||
self.session[k] = v.copy()
|
||||
else:
|
||||
self.session[k] = v
|
||||
|
||||
logger.debug("Config loaded")
|
||||
|
||||
def dump(self, info):
|
||||
"""Given a state of the config, save it to the file.
|
||||
|
||||
:param info:
|
||||
"""
|
||||
with open(self._path, "w") as cfg:
|
||||
logger.debug("Config saved: %s", self._path)
|
||||
cfg.write(tomlkit.dumps(info))
|
||||
|
||||
@property
|
||||
def tidal_creds(self):
|
||||
"""Return a TidalClient compatible dict of credentials."""
|
||||
creds = dict(self.file["tidal"])
|
||||
logger.debug(creds)
|
||||
del creds["quality"] # should not be included in creds
|
||||
del creds["download_videos"]
|
||||
return creds
|
||||
|
||||
@property
|
||||
def qobuz_creds(self):
|
||||
"""Return a QobuzClient compatible dict of credentials."""
|
||||
return {
|
||||
"email": self.file["qobuz"]["email"],
|
||||
"pwd": self.file["qobuz"]["password"],
|
||||
"app_id": self.file["qobuz"]["app_id"],
|
||||
"secrets": self.file["qobuz"]["secrets"],
|
||||
}
|
||||
|
||||
def creds(self, source: str):
|
||||
"""Return a Client compatible dict of credentials.
|
||||
|
||||
:param source:
|
||||
:type source: str
|
||||
"""
|
||||
if source == "qobuz":
|
||||
return self.qobuz_creds
|
||||
if source == "tidal":
|
||||
return self.tidal_creds
|
||||
if source == "deezer":
|
||||
return {"arl": self.file["deezer"]["arl"]}
|
||||
if source == "soundcloud":
|
||||
soundcloud = self.file["soundcloud"]
|
||||
return {
|
||||
"client_id": soundcloud["client_id"],
|
||||
"app_version": soundcloud["app_version"],
|
||||
}
|
||||
|
||||
raise InvalidSourceError(source)
|
||||
|
||||
def __repr__(self) -> str:
|
||||
"""Return a string representation of the config."""
|
||||
return f"Config({pformat(self.session)})"
|
||||
|
|
@ -1,30 +0,0 @@
|
|||
"""Various constant values that are used by RipCore."""
|
||||
|
||||
import os
|
||||
import re
|
||||
from pathlib import Path
|
||||
|
||||
from appdirs import user_config_dir
|
||||
|
||||
APPNAME = "streamrip"
|
||||
APP_DIR = user_config_dir(APPNAME)
|
||||
HOME = Path.home()
|
||||
|
||||
LOG_DIR = CACHE_DIR = CONFIG_DIR = APP_DIR
|
||||
|
||||
CONFIG_PATH = os.path.join(CONFIG_DIR, "config.toml")
|
||||
DB_PATH = os.path.join(LOG_DIR, "downloads.db")
|
||||
FAILED_DB_PATH = os.path.join(LOG_DIR, "failed_downloads.db")
|
||||
|
||||
DOWNLOADS_DIR = os.path.join(HOME, "StreamripDownloads")
|
||||
|
||||
URL_REGEX = re.compile(
|
||||
r"https?://(?:www|open|play|listen)?\.?(qobuz|tidal|deezer)\.com(?:(?:/(album|artist|track|playlist|video|label))|(?:\/[-\w]+?))+\/([-\w]+)"
|
||||
)
|
||||
SOUNDCLOUD_URL_REGEX = re.compile(r"https://soundcloud.com/[-\w:/]+")
|
||||
LASTFM_URL_REGEX = re.compile(r"https://www.last.fm/user/\w+/playlists/\w+")
|
||||
QOBUZ_INTERPRETER_URL_REGEX = re.compile(
|
||||
r"https?://www\.qobuz\.com/\w\w-\w\w/interpreter/[-\w]+/[-\w]+"
|
||||
)
|
||||
DEEZER_DYNAMIC_LINK_REGEX = re.compile(r"https://deezer\.page\.link/\w+")
|
||||
YOUTUBE_URL_REGEX = re.compile(r"https://www\.youtube\.com/watch\?v=[-\w]+")
|
||||
932
rip/core.py
|
|
@ -1,932 +0,0 @@
|
|||
"""The stuff that ties everything together for the CLI to use."""
|
||||
|
||||
import concurrent.futures
|
||||
import html
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
import threading
|
||||
from getpass import getpass
|
||||
from hashlib import md5
|
||||
from string import Formatter
|
||||
from typing import Dict, Generator, List, Optional, Tuple, Type, Union
|
||||
|
||||
import requests
|
||||
from click import secho, style
|
||||
from tqdm import tqdm
|
||||
|
||||
from streamrip.clients import (
|
||||
Client,
|
||||
DeezerClient,
|
||||
DeezloaderClient,
|
||||
QobuzClient,
|
||||
SoundCloudClient,
|
||||
TidalClient,
|
||||
)
|
||||
from streamrip.constants import MEDIA_TYPES
|
||||
from streamrip.exceptions import (
|
||||
AuthenticationError,
|
||||
IneligibleError,
|
||||
ItemExists,
|
||||
MissingCredentials,
|
||||
NonStreamable,
|
||||
NoResultsFound,
|
||||
ParsingError,
|
||||
PartialFailure,
|
||||
)
|
||||
from streamrip.media import (
|
||||
Album,
|
||||
Artist,
|
||||
Label,
|
||||
Playlist,
|
||||
Track,
|
||||
Tracklist,
|
||||
Video,
|
||||
YoutubeVideo,
|
||||
)
|
||||
from streamrip.utils import TQDM_DEFAULT_THEME, set_progress_bar_theme
|
||||
|
||||
from . import db
|
||||
from .config import Config
|
||||
from .constants import (
|
||||
CONFIG_PATH,
|
||||
DB_PATH,
|
||||
DEEZER_DYNAMIC_LINK_REGEX,
|
||||
FAILED_DB_PATH,
|
||||
LASTFM_URL_REGEX,
|
||||
QOBUZ_INTERPRETER_URL_REGEX,
|
||||
SOUNDCLOUD_URL_REGEX,
|
||||
URL_REGEX,
|
||||
YOUTUBE_URL_REGEX,
|
||||
)
|
||||
from .exceptions import DeezloaderFallback
|
||||
from .utils import extract_deezer_dynamic_link, extract_interpreter_url
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
# ---------------- Constants ------------------ #
|
||||
Media = Union[
|
||||
Type[Album],
|
||||
Type[Playlist],
|
||||
Type[Artist],
|
||||
Type[Track],
|
||||
Type[Label],
|
||||
Type[Video],
|
||||
]
|
||||
MEDIA_CLASS: Dict[str, Media] = {
|
||||
"album": Album,
|
||||
"playlist": Playlist,
|
||||
"artist": Artist,
|
||||
"track": Track,
|
||||
"label": Label,
|
||||
"video": Video,
|
||||
}
|
||||
|
||||
DB_PATH_MAP = {"downloads": DB_PATH, "failed_downloads": FAILED_DB_PATH}
|
||||
# ---------------------------------------------- #
|
||||
|
||||
|
||||
class RipCore(list):
|
||||
"""RipCore."""
|
||||
|
||||
clients = {
|
||||
"qobuz": QobuzClient(),
|
||||
"tidal": TidalClient(),
|
||||
"deezer": DeezerClient(),
|
||||
"soundcloud": SoundCloudClient(),
|
||||
"deezloader": DeezloaderClient(),
|
||||
}
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
config: Optional[Config] = None,
|
||||
):
|
||||
"""Create a RipCore object.
|
||||
|
||||
:param config:
|
||||
:type config: Optional[Config]
|
||||
"""
|
||||
self.config: Config
|
||||
if config is None:
|
||||
self.config = Config(CONFIG_PATH)
|
||||
else:
|
||||
self.config = config
|
||||
|
||||
if (theme := self.config.file["theme"]["progress_bar"]) != TQDM_DEFAULT_THEME:
|
||||
set_progress_bar_theme(theme.lower())
|
||||
|
||||
def get_db(db_type: str) -> db.Database:
|
||||
db_settings = self.config.session["database"]
|
||||
db_class = db.CLASS_MAP[db_type]
|
||||
|
||||
if db_settings[db_type]["enabled"] and db_settings.get("enabled", True):
|
||||
default_db_path = DB_PATH_MAP[db_type]
|
||||
path = db_settings[db_type]["path"]
|
||||
|
||||
if path:
|
||||
database = db_class(path)
|
||||
else:
|
||||
database = db_class(default_db_path)
|
||||
|
||||
assert config is not None
|
||||
config.file["database"][db_type]["path"] = default_db_path
|
||||
config.save()
|
||||
else:
|
||||
database = db_class(None, dummy=True)
|
||||
|
||||
return database
|
||||
|
||||
self.db = get_db("downloads")
|
||||
self.failed_db = get_db("failed_downloads")
|
||||
|
||||
def handle_urls(self, urls):
|
||||
"""Download a url.
|
||||
|
||||
:param url:
|
||||
:type url: str
|
||||
:raises InvalidSourceError
|
||||
:raises ParsingError
|
||||
"""
|
||||
if isinstance(urls, str):
|
||||
url = urls
|
||||
elif isinstance(urls, tuple):
|
||||
url = " ".join(urls)
|
||||
else:
|
||||
raise Exception(f"Urls has invalid type {type(urls)}")
|
||||
|
||||
# youtube is handled by youtube-dl, so much of the
|
||||
# processing is not necessary
|
||||
youtube_urls = YOUTUBE_URL_REGEX.findall(url)
|
||||
if youtube_urls != []:
|
||||
self.extend(YoutubeVideo(u) for u in youtube_urls)
|
||||
|
||||
parsed = self.parse_urls(url)
|
||||
if not parsed and len(self) == 0:
|
||||
if "last.fm" in url:
|
||||
message = (
|
||||
f"For last.fm urls, use the {style('lastfm', fg='yellow')} "
|
||||
f"command. See {style('rip lastfm --help', fg='yellow')}."
|
||||
)
|
||||
else:
|
||||
message = f"Cannot find urls in text: {url}"
|
||||
|
||||
raise ParsingError(message)
|
||||
|
||||
for source, url_type, item_id in parsed:
|
||||
if item_id in self.db:
|
||||
secho(
|
||||
f"ID {item_id} already downloaded, use --ignore-db to override.",
|
||||
fg="magenta",
|
||||
)
|
||||
continue
|
||||
|
||||
self.handle_item(source, url_type, item_id)
|
||||
|
||||
def handle_item(self, source: str, media_type: str, item_id: str):
|
||||
"""Get info and parse into a Media object.
|
||||
|
||||
:param source:
|
||||
:type source: str
|
||||
:param media_type:
|
||||
:type media_type: str
|
||||
:param item_id:
|
||||
:type item_id: str
|
||||
"""
|
||||
client = self.get_client(source)
|
||||
|
||||
if media_type not in MEDIA_TYPES:
|
||||
if "playlist" in media_type: # for SoundCloud
|
||||
media_type = "playlist"
|
||||
|
||||
assert media_type in MEDIA_TYPES, media_type
|
||||
item = MEDIA_CLASS[media_type](client=client, id=item_id)
|
||||
self.append(item)
|
||||
|
||||
def _get_download_args(self) -> dict:
|
||||
"""Get the arguments to pass to Media.download.
|
||||
|
||||
:rtype: dict
|
||||
"""
|
||||
session = self.config.session
|
||||
logger.debug(session)
|
||||
# So that the dictionary isn't searched for the same keys multiple times
|
||||
artwork, conversion, filepaths, metadata = (
|
||||
session[key] for key in ("artwork", "conversion", "filepaths", "metadata")
|
||||
)
|
||||
concurrency = session["downloads"]["concurrency"]
|
||||
return {
|
||||
"restrict_filenames": filepaths["restrict_characters"],
|
||||
"parent_folder": session["downloads"]["folder"],
|
||||
"folder_format": filepaths["folder_format"],
|
||||
"track_format": filepaths["track_format"],
|
||||
"embed_cover": artwork["embed"],
|
||||
"embed_cover_size": artwork["size"],
|
||||
"keep_hires_cover": artwork["keep_hires_cover"],
|
||||
"set_playlist_to_album": metadata["set_playlist_to_album"],
|
||||
"stay_temp": conversion["enabled"],
|
||||
"conversion": conversion,
|
||||
"concurrent_downloads": concurrency["enabled"],
|
||||
"max_connections": concurrency["max_connections"],
|
||||
"new_tracknumbers": metadata["new_playlist_tracknumbers"],
|
||||
"download_videos": session["tidal"]["download_videos"],
|
||||
"download_booklets": session["qobuz"]["download_booklets"],
|
||||
"download_youtube_videos": session["youtube"]["download_videos"],
|
||||
"youtube_video_downloads_folder": session["youtube"][
|
||||
"video_downloads_folder"
|
||||
],
|
||||
"add_singles_to_folder": filepaths["add_singles_to_folder"],
|
||||
"max_artwork_width": int(artwork["max_width"]),
|
||||
"max_artwork_height": int(artwork["max_height"]),
|
||||
"exclude_tags": metadata["exclude"],
|
||||
}
|
||||
|
||||
def repair(self, max_items=None):
|
||||
"""Iterate through the failed_downloads database and retry them.
|
||||
|
||||
:param max_items: The maximum number of items to download.
|
||||
"""
|
||||
if max_items is None:
|
||||
max_items = float("inf")
|
||||
|
||||
self.db = db.Downloads(None, dummy=True)
|
||||
if self.failed_db.is_dummy:
|
||||
secho(
|
||||
"Failed downloads database must be enabled in the config file "
|
||||
"to repair!",
|
||||
fg="red",
|
||||
)
|
||||
exit()
|
||||
|
||||
for counter, (source, media_type, item_id) in enumerate(self.failed_db):
|
||||
if counter >= max_items:
|
||||
break
|
||||
|
||||
self.handle_item(source, media_type, item_id)
|
||||
|
||||
self.download()
|
||||
|
||||
def download(self):
|
||||
"""Download all the items in self."""
|
||||
try:
|
||||
arguments = self._get_download_args()
|
||||
except KeyError as e:
|
||||
self._config_updating_message()
|
||||
self.config.update()
|
||||
logger.debug("Config update error: %s", e)
|
||||
exit()
|
||||
except Exception as err:
|
||||
self._config_corrupted_message(err)
|
||||
exit()
|
||||
|
||||
logger.debug("Arguments from config: %s", arguments)
|
||||
|
||||
source_subdirs = self.config.session["downloads"]["source_subdirectories"]
|
||||
for item in self:
|
||||
# Item already checked in database in handle_urls
|
||||
if source_subdirs:
|
||||
arguments["parent_folder"] = self.__get_source_subdir(
|
||||
item.client.source
|
||||
)
|
||||
|
||||
if item is YoutubeVideo:
|
||||
item.download(**arguments)
|
||||
continue
|
||||
|
||||
arguments["quality"] = self.config.session[item.client.source]["quality"]
|
||||
if isinstance(item, Artist):
|
||||
filters_ = tuple(
|
||||
k for k, v in self.config.session["filters"].items() if v
|
||||
)
|
||||
arguments["filters"] = filters_
|
||||
logger.debug("Added filter argument for artist/label: %s", filters_)
|
||||
|
||||
if not isinstance(item, Tracklist) or not item.loaded:
|
||||
logger.debug("Loading metadata")
|
||||
try:
|
||||
item.load_meta(**arguments)
|
||||
except NonStreamable:
|
||||
self.failed_db.add((item.client.source, item.type, item.id))
|
||||
secho(f"{item!s} is not available, skipping.", fg="red")
|
||||
continue
|
||||
|
||||
try:
|
||||
item.download(**arguments)
|
||||
for item_id in item.downloaded_ids:
|
||||
self.db.add([item_id])
|
||||
except NonStreamable as e:
|
||||
e.print(item)
|
||||
self.failed_db.add((item.client.source, item.type, item.id))
|
||||
continue
|
||||
except PartialFailure as e:
|
||||
# add successful downloads to database?
|
||||
for failed_item_info in e.failed_items:
|
||||
self.failed_db.add(failed_item_info)
|
||||
continue
|
||||
except ItemExists as e:
|
||||
secho(f'"{e!s}" already exists. Skipping.', fg="yellow")
|
||||
continue
|
||||
|
||||
if hasattr(item, "id"):
|
||||
self.db.add(str(item.id))
|
||||
for item_id in item.downloaded_ids:
|
||||
self.db.add(str(item_id))
|
||||
|
||||
if isinstance(item, Track):
|
||||
item.tag(exclude_tags=arguments["exclude_tags"])
|
||||
if arguments["conversion"]["enabled"]:
|
||||
item.convert(**arguments["conversion"])
|
||||
|
||||
def scrape(self, featured_list: str, max_items: int = 500):
|
||||
"""Download all of the items in a Qobuz featured list.
|
||||
|
||||
:param featured_list: The name of the list. See `rip discover --help`.
|
||||
:type featured_list: str
|
||||
"""
|
||||
self.extend(self.search("qobuz", featured_list, "featured", limit=max_items))
|
||||
|
||||
def get_client(self, source: str) -> Client:
|
||||
"""Get a client given the source and log in.
|
||||
|
||||
:param source:
|
||||
:type source: str
|
||||
:rtype: Client
|
||||
"""
|
||||
client = self.clients[source]
|
||||
if not client.logged_in:
|
||||
try:
|
||||
self.login(client)
|
||||
except DeezloaderFallback:
|
||||
client = self.clients["deezloader"]
|
||||
|
||||
return client
|
||||
|
||||
def login(self, client):
|
||||
"""Log into a client, if applicable.
|
||||
|
||||
:param client:
|
||||
"""
|
||||
creds = self.config.creds(client.source)
|
||||
if client.source == "deezer" and creds["arl"] == "":
|
||||
if self.config.session["deezer"]["deezloader_warnings"]:
|
||||
secho(
|
||||
"Falling back to Deezloader (unstable). If you have a subscription, run ",
|
||||
nl=False,
|
||||
fg="yellow",
|
||||
)
|
||||
secho("rip config --deezer ", nl=False, bold=True)
|
||||
secho("to log in.", fg="yellow")
|
||||
raise DeezloaderFallback
|
||||
|
||||
while True:
|
||||
try:
|
||||
client.login(**creds)
|
||||
break
|
||||
except AuthenticationError:
|
||||
secho("Invalid credentials, try again.", fg="yellow")
|
||||
self.prompt_creds(client.source)
|
||||
creds = self.config.creds(client.source)
|
||||
except MissingCredentials:
|
||||
logger.debug("Credentials are missing. Prompting..")
|
||||
get_tokens = threading.Thread(
|
||||
target=client._get_app_id_and_secrets, daemon=True
|
||||
)
|
||||
get_tokens.start()
|
||||
|
||||
self.prompt_creds(client.source)
|
||||
creds = self.config.creds(client.source)
|
||||
|
||||
get_tokens.join()
|
||||
|
||||
if (
|
||||
client.source == "qobuz"
|
||||
and not creds.get("secrets")
|
||||
and not creds.get("app_id")
|
||||
):
|
||||
(
|
||||
self.config.file["qobuz"]["app_id"],
|
||||
self.config.file["qobuz"]["secrets"],
|
||||
) = client.get_tokens()
|
||||
self.config.save()
|
||||
elif (
|
||||
client.source == "soundcloud"
|
||||
and not creds.get("client_id")
|
||||
and not creds.get("app_version")
|
||||
):
|
||||
(
|
||||
self.config.file["soundcloud"]["client_id"],
|
||||
self.config.file["soundcloud"]["app_version"],
|
||||
) = client.get_tokens()
|
||||
self.config.save()
|
||||
|
||||
elif client.source == "tidal":
|
||||
self.config.file["tidal"].update(client.get_tokens())
|
||||
self.config.save() # only for the expiry stamp
|
||||
|
||||
def parse_urls(self, url: str) -> List[Tuple[str, str, str]]:
|
||||
"""Return the type of the url and the id.
|
||||
|
||||
Compatible with urls of the form:
|
||||
https://www.qobuz.com/us-en/type/name/id
|
||||
https://open.qobuz.com/type/id
|
||||
https://play.qobuz.com/type/id
|
||||
|
||||
https://www.deezer.com/us/type/id
|
||||
https://tidal.com/browse/type/id
|
||||
|
||||
:raises exceptions.ParsingError:
|
||||
"""
|
||||
parsed: List[Tuple[str, str, str]] = []
|
||||
|
||||
interpreter_urls = QOBUZ_INTERPRETER_URL_REGEX.findall(url)
|
||||
if interpreter_urls:
|
||||
secho(
|
||||
"Extracting IDs from Qobuz interpreter urls. Use urls "
|
||||
"that include the artist ID for faster preprocessing.",
|
||||
fg="yellow",
|
||||
)
|
||||
parsed.extend(
|
||||
("qobuz", "artist", extract_interpreter_url(u))
|
||||
for u in interpreter_urls
|
||||
)
|
||||
url = QOBUZ_INTERPRETER_URL_REGEX.sub("", url)
|
||||
|
||||
dynamic_urls = DEEZER_DYNAMIC_LINK_REGEX.findall(url)
|
||||
if dynamic_urls:
|
||||
secho(
|
||||
"Extracting IDs from Deezer dynamic link. Use urls "
|
||||
"of the form https://www.deezer.com/{country}/{type}/{id} for "
|
||||
"faster processing.",
|
||||
fg="yellow",
|
||||
)
|
||||
parsed.extend(
|
||||
("deezer", *extract_deezer_dynamic_link(url)) for url in dynamic_urls
|
||||
)
|
||||
|
||||
parsed.extend(URL_REGEX.findall(url)) # Qobuz, Tidal, Deezer
|
||||
soundcloud_urls = SOUNDCLOUD_URL_REGEX.findall(url)
|
||||
|
||||
if soundcloud_urls:
|
||||
soundcloud_client = self.get_client("soundcloud")
|
||||
assert isinstance(soundcloud_client, SoundCloudClient) # for typing
|
||||
|
||||
# TODO: Make this async
|
||||
soundcloud_items = (
|
||||
soundcloud_client.resolve_url(u) for u in soundcloud_urls
|
||||
)
|
||||
|
||||
parsed.extend(
|
||||
("soundcloud", item["kind"], str(item["id"]))
|
||||
for item in soundcloud_items
|
||||
)
|
||||
|
||||
logger.debug("Parsed urls: %s", parsed)
|
||||
|
||||
return parsed
|
||||
|
||||
def handle_lastfm_urls(self, urls: str):
|
||||
"""Get info from lastfm url, and parse into Media objects.
|
||||
|
||||
This works by scraping the last.fm page and using a regex to
|
||||
find the track titles and artists. The information is queried
|
||||
in a Client.search(query, 'track') call and the first result is
|
||||
used.
|
||||
|
||||
:param urls:
|
||||
"""
|
||||
# Available keys: ['artist', 'title']
|
||||
QUERY_FORMAT: Dict[str, str] = {
|
||||
"tidal": "{title}",
|
||||
"qobuz": "{title} {artist}",
|
||||
"deezer": "{title} {artist}",
|
||||
"soundcloud": "{title} {artist}",
|
||||
}
|
||||
|
||||
# For testing:
|
||||
# https://www.last.fm/user/nathan3895/playlists/12058911
|
||||
user_regex = re.compile(r"https://www\.last\.fm/user/([^/]+)/playlists/\d+")
|
||||
lastfm_urls = LASTFM_URL_REGEX.findall(urls)
|
||||
try:
|
||||
lastfm_source = self.config.session["lastfm"]["source"]
|
||||
lastfm_fallback_source = self.config.session["lastfm"]["fallback_source"]
|
||||
except KeyError:
|
||||
self._config_updating_message()
|
||||
self.config.update()
|
||||
exit()
|
||||
except Exception as err:
|
||||
self._config_corrupted_message(err)
|
||||
exit()
|
||||
|
||||
# Do not include tracks that have (re)mix, live, karaoke in their titles
|
||||
# within parentheses or brackets
|
||||
# This will match somthing like "Test (Person Remix]" though, so its not perfect
|
||||
banned_words_plain = re.compile(r"(?i)(?:(?:re)?mix|live|karaoke)")
|
||||
banned_words = re.compile(
|
||||
r"(?i)[\(\[][^\)\]]*?(?:(?:re)?mix|live|karaoke)[^\)\]]*[\]\)]"
|
||||
)
|
||||
|
||||
def search_query(title, artist, playlist) -> bool:
|
||||
"""Search for a query and add the first result to playlist.
|
||||
|
||||
:param query:
|
||||
:type query: str
|
||||
:param playlist:
|
||||
:type playlist: Playlist
|
||||
:rtype: bool
|
||||
"""
|
||||
|
||||
def try_search(source) -> Optional[Track]:
|
||||
try:
|
||||
query = QUERY_FORMAT[lastfm_source].format(
|
||||
title=title, artist=artist
|
||||
)
|
||||
query_is_clean = banned_words_plain.search(query) is None
|
||||
|
||||
search_results = self.search(source, query, media_type="track")
|
||||
track = next(search_results)
|
||||
|
||||
if query_is_clean:
|
||||
while banned_words.search(track["title"]) is not None:
|
||||
logger.debug("Track title banned for query=%s", query)
|
||||
track = next(search_results)
|
||||
|
||||
# Because the track is searched as a single we need to set
|
||||
# this manually
|
||||
track.part_of_tracklist = True
|
||||
return track
|
||||
except (NoResultsFound, StopIteration):
|
||||
return None
|
||||
|
||||
track = try_search(lastfm_source) or try_search(lastfm_fallback_source)
|
||||
if track is None:
|
||||
return False
|
||||
|
||||
if self.config.session["metadata"]["set_playlist_to_album"]:
|
||||
# so that the playlist name (actually the album) isn't
|
||||
# amended to include version and work tags from individual tracks
|
||||
track.meta.version = track.meta.work = None
|
||||
|
||||
playlist.append(track)
|
||||
return True
|
||||
|
||||
from streamrip.utils import TQDM_BAR_FORMAT
|
||||
|
||||
for purl in lastfm_urls:
|
||||
secho(f"Fetching playlist at {purl}", fg="blue")
|
||||
title, queries = self.get_lastfm_playlist(purl)
|
||||
|
||||
pl = Playlist(client=self.get_client(lastfm_source), name=title)
|
||||
creator_match = user_regex.search(purl)
|
||||
if creator_match is not None:
|
||||
pl.creator = creator_match.group(1)
|
||||
|
||||
tracks_not_found = 0
|
||||
with concurrent.futures.ThreadPoolExecutor(max_workers=15) as executor:
|
||||
futures = [
|
||||
executor.submit(search_query, title, artist, pl)
|
||||
for title, artist in queries
|
||||
]
|
||||
# only for the progress bar
|
||||
for search_attempt in tqdm(
|
||||
concurrent.futures.as_completed(futures),
|
||||
unit="Tracks",
|
||||
dynamic_ncols=True,
|
||||
total=len(futures),
|
||||
desc="Searching...",
|
||||
bar_format=TQDM_BAR_FORMAT,
|
||||
):
|
||||
if not search_attempt.result():
|
||||
tracks_not_found += 1
|
||||
|
||||
pl.loaded = True
|
||||
|
||||
if tracks_not_found > 0:
|
||||
secho(f"{tracks_not_found} tracks not found.", fg="yellow")
|
||||
|
||||
self.append(pl)
|
||||
|
||||
def handle_txt(self, filepath: Union[str, os.PathLike]):
|
||||
"""
|
||||
Handle a text file containing URLs. Lines starting with `#` are ignored.
|
||||
|
||||
:param filepath:
|
||||
:type filepath: Union[str, os.PathLike]
|
||||
:raises OSError
|
||||
:raises exceptions.ParsingError
|
||||
"""
|
||||
with open(filepath) as txt:
|
||||
self.handle_urls(txt.read())
|
||||
|
||||
def search(
|
||||
self,
|
||||
source: str,
|
||||
query: str,
|
||||
media_type: str = "album",
|
||||
check_db: bool = False,
|
||||
limit: int = 200,
|
||||
) -> Generator:
|
||||
"""Universal search.
|
||||
|
||||
:param source:
|
||||
:type source: str
|
||||
:param query:
|
||||
:type query: str
|
||||
:param media_type:
|
||||
:type media_type: str
|
||||
:param limit: Not Implemented
|
||||
:type limit: int
|
||||
:rtype: Generator
|
||||
"""
|
||||
logger.debug("searching for %s", query)
|
||||
|
||||
client = self.get_client(source)
|
||||
|
||||
if isinstance(client, DeezloaderClient) and media_type == "featured":
|
||||
raise IneligibleError(
|
||||
"Must have premium Deezer account to access editorial lists."
|
||||
)
|
||||
|
||||
results = client.search(query, media_type)
|
||||
|
||||
if media_type == "featured":
|
||||
media_type = "album"
|
||||
|
||||
if isinstance(results, Generator): # QobuzClient
|
||||
for page in results:
|
||||
tracklist = (
|
||||
page[f"{media_type}s"]["items"]
|
||||
if media_type != "featured"
|
||||
else page["albums"]["items"]
|
||||
)
|
||||
for i, item in enumerate(tracklist):
|
||||
yield MEDIA_CLASS[ # type: ignore
|
||||
media_type if media_type != "featured" else "album"
|
||||
].from_api(item, client)
|
||||
|
||||
if i >= limit - 1:
|
||||
return
|
||||
else:
|
||||
items = (
|
||||
results.get("data")
|
||||
or results.get("items")
|
||||
or results.get("collection")
|
||||
or results.get("albums", {}).get("data", False)
|
||||
)
|
||||
|
||||
if not items:
|
||||
raise NoResultsFound(query)
|
||||
|
||||
logger.debug("Number of results: %d", len(items))
|
||||
|
||||
for i, item in enumerate(items):
|
||||
logger.debug(item)
|
||||
yield MEDIA_CLASS[media_type].from_api(item, client) # type: ignore
|
||||
if i >= limit - 1:
|
||||
return
|
||||
|
||||
def preview_media(self, media) -> str:
|
||||
"""Return a preview string of a Media object.
|
||||
|
||||
:param media:
|
||||
"""
|
||||
if isinstance(media, Album):
|
||||
fmt = (
|
||||
"{albumartist} - {album}\n"
|
||||
"Released on {year}\n{tracktotal} tracks\n"
|
||||
"{bit_depth} bit / {sampling_rate} Hz\n"
|
||||
"Version: {version}\n"
|
||||
"Genre: {genre}"
|
||||
)
|
||||
elif isinstance(media, Artist):
|
||||
fmt = "{name}"
|
||||
elif isinstance(media, Track):
|
||||
fmt = "{artist} - {title}\nReleased on {year}"
|
||||
elif isinstance(media, Playlist):
|
||||
fmt = (
|
||||
"{title}\n"
|
||||
"{tracktotal} tracks\n"
|
||||
"{popularity}\n"
|
||||
"Description: {description}"
|
||||
)
|
||||
else:
|
||||
raise NotImplementedError
|
||||
|
||||
fields = (fname for _, fname, _, _ in Formatter().parse(fmt) if fname)
|
||||
ret = fmt.format(**{k: media.get(k, default="Unknown") for k in fields})
|
||||
return ret
|
||||
|
||||
def interactive_search(
|
||||
self,
|
||||
query: str,
|
||||
source: str = "qobuz",
|
||||
media_type: str = "album",
|
||||
limit: int = 50,
|
||||
):
|
||||
"""Show an interactive menu that contains search results.
|
||||
|
||||
:param query:
|
||||
:type query: str
|
||||
:param source:
|
||||
:type source: str
|
||||
:param media_type:
|
||||
:type media_type: str
|
||||
"""
|
||||
results = tuple(self.search(source, query, media_type, limit=limit))
|
||||
|
||||
def title(res):
|
||||
index, item = res
|
||||
item_no = index + 1
|
||||
if isinstance(item, Album):
|
||||
return f"{item_no}. {item.album}"
|
||||
elif isinstance(item, Track):
|
||||
return f"{item_no}. {item.meta.title}"
|
||||
elif isinstance(item, Playlist):
|
||||
return f"{item_no}. {item.name}"
|
||||
elif isinstance(item, Artist):
|
||||
return f"{item_no}. {item.name}"
|
||||
else:
|
||||
raise NotImplementedError(item.type)
|
||||
|
||||
def from_title(s):
|
||||
num = []
|
||||
for char in s:
|
||||
if char != ".":
|
||||
num.append(char)
|
||||
else:
|
||||
break
|
||||
return self.preview_media(results[int("".join(num)) - 1])
|
||||
|
||||
if os.name == "nt":
|
||||
from pick import pick
|
||||
|
||||
choice = pick(
|
||||
tuple(enumerate(results)),
|
||||
title=(
|
||||
f"{source.capitalize()} {media_type} search.\n"
|
||||
"Press SPACE to select, RETURN to download, ctrl-C to exit."
|
||||
),
|
||||
options_map_func=title,
|
||||
multiselect=True,
|
||||
)
|
||||
|
||||
if isinstance(choice, list):
|
||||
for item in choice:
|
||||
self.append(item[0][1])
|
||||
elif isinstance(choice, tuple):
|
||||
self.append(choice[0][1])
|
||||
|
||||
return True
|
||||
else:
|
||||
from simple_term_menu import TerminalMenu
|
||||
|
||||
menu = TerminalMenu(
|
||||
map(title, enumerate(results)),
|
||||
preview_command=from_title,
|
||||
preview_size=0.5,
|
||||
title=(
|
||||
f"{source.capitalize()} {media_type} search.\n"
|
||||
"SPACE - multiselection, ENTER - download, ESC - exit"
|
||||
),
|
||||
cycle_cursor=True,
|
||||
clear_screen=True,
|
||||
multi_select=True,
|
||||
)
|
||||
choice = menu.show()
|
||||
if choice is None:
|
||||
return False
|
||||
else:
|
||||
if isinstance(choice, int):
|
||||
self.append(results[choice])
|
||||
elif isinstance(choice, tuple):
|
||||
for i in choice:
|
||||
self.append(results[i])
|
||||
return True
|
||||
|
||||
def get_lastfm_playlist(self, url: str) -> Tuple[str, list]:
|
||||
"""From a last.fm url, find the playlist title and tracks.
|
||||
|
||||
Each page contains 50 results, so `num_tracks // 50 + 1` requests
|
||||
are sent per playlist.
|
||||
|
||||
:param url:
|
||||
:type url: str
|
||||
:rtype: Tuple[str, list]
|
||||
"""
|
||||
logger.debug("Fetching lastfm playlist")
|
||||
|
||||
info = []
|
||||
words = re.compile(r"[\w\s]+")
|
||||
title_tags = re.compile('title="([^"]+)"')
|
||||
|
||||
def essence(s):
|
||||
s = re.sub(r"&#\d+;", "", s) # remove HTML entities
|
||||
# TODO: change to finditer
|
||||
return "".join(words.findall(s))
|
||||
|
||||
def get_titles(s):
|
||||
titles = title_tags.findall(s)[2:]
|
||||
for i in range(0, len(titles) - 1, 2):
|
||||
info.append((essence(titles[i]), essence(titles[i + 1])))
|
||||
|
||||
r = requests.get(url)
|
||||
get_titles(r.text)
|
||||
remaining_tracks_match = re.search(
|
||||
r'data-playlisting-entry-count="(\d+)"', r.text
|
||||
)
|
||||
if remaining_tracks_match is None:
|
||||
raise ParsingError("Error parsing lastfm page: %s", r.text)
|
||||
|
||||
total_tracks = int(remaining_tracks_match.group(1))
|
||||
logger.debug("Total tracks: %d", total_tracks)
|
||||
remaining_tracks = total_tracks - 50
|
||||
|
||||
playlist_title_match = re.search(
|
||||
r'<h1 class="playlisting-playlist-header-title">([^<]+)</h1>',
|
||||
r.text,
|
||||
)
|
||||
if playlist_title_match is None:
|
||||
raise ParsingError("Error finding title from response")
|
||||
|
||||
playlist_title = html.unescape(playlist_title_match.group(1))
|
||||
|
||||
if remaining_tracks > 0:
|
||||
with concurrent.futures.ThreadPoolExecutor(max_workers=15) as executor:
|
||||
last_page = int(remaining_tracks // 50) + int(
|
||||
remaining_tracks % 50 != 0
|
||||
)
|
||||
|
||||
futures = [
|
||||
executor.submit(requests.get, f"{url}?page={page}")
|
||||
for page in range(1, last_page + 1)
|
||||
]
|
||||
|
||||
for future in concurrent.futures.as_completed(futures):
|
||||
get_titles(future.result().text)
|
||||
|
||||
return playlist_title, info
|
||||
|
||||
def __get_source_subdir(self, source: str) -> str:
|
||||
path = self.config.session["downloads"]["folder"]
|
||||
return os.path.join(path, source.capitalize())
|
||||
|
||||
def prompt_creds(self, source: str):
|
||||
"""Prompt the user for credentials.
|
||||
|
||||
:param source:
|
||||
:type source: str
|
||||
"""
|
||||
if source == "qobuz":
|
||||
secho("Enter Qobuz email:", fg="green")
|
||||
self.config.file[source]["email"] = input()
|
||||
secho(
|
||||
"Enter Qobuz password (will not show on screen):",
|
||||
fg="green",
|
||||
)
|
||||
self.config.file[source]["password"] = md5(
|
||||
getpass(prompt="").encode("utf-8")
|
||||
).hexdigest()
|
||||
|
||||
self.config.save()
|
||||
secho(
|
||||
f'Credentials saved to config file at "{self.config._path}"',
|
||||
fg="green",
|
||||
)
|
||||
elif source == "deezer":
|
||||
secho(
|
||||
"If you're not sure how to find the ARL cookie, see the instructions at ",
|
||||
italic=True,
|
||||
nl=False,
|
||||
dim=True,
|
||||
)
|
||||
secho(
|
||||
"https://github.com/nathom/streamrip/wiki/Finding-your-Deezer-ARL-Cookie",
|
||||
underline=True,
|
||||
italic=True,
|
||||
fg="blue",
|
||||
)
|
||||
|
||||
self.config.file["deezer"]["arl"] = input(style("ARL: ", fg="green"))
|
||||
self.config.save()
|
||||
secho(
|
||||
f'Credentials saved to config file at "{self.config._path}"',
|
||||
fg="green",
|
||||
)
|
||||
else:
|
||||
raise Exception
|
||||
|
||||
def _config_updating_message(self):
|
||||
secho(
|
||||
"Updating config file... Some settings may be lost. Please run the "
|
||||
"command again.",
|
||||
fg="magenta",
|
||||
)
|
||||
|
||||
def _config_corrupted_message(self, err: Exception):
|
||||
secho(
|
||||
"There was a problem with your config file. This happens "
|
||||
"sometimes after updates. Run ",
|
||||
nl=False,
|
||||
fg="red",
|
||||
)
|
||||
secho("rip config --reset ", fg="yellow", nl=False)
|
||||
secho("to reset it. You will need to log in again.", fg="red")
|
||||
secho(str(err), fg="red")
|
||||
|
|
@ -1,5 +0,0 @@
|
|||
"""Exceptions used by RipCore."""
|
||||
|
||||
|
||||
class DeezloaderFallback(Exception):
|
||||
"""Raise if Deezer account isn't logged in and rip is falling back to Deezloader."""
|
||||
49
rip/utils.py
|
|
@ -1,49 +0,0 @@
|
|||
"""Utility functions for RipCore."""
|
||||
|
||||
import re
|
||||
from typing import Tuple
|
||||
|
||||
from streamrip.constants import AGENT
|
||||
from streamrip.utils import gen_threadsafe_session
|
||||
|
||||
interpreter_artist_regex = re.compile(r"getSimilarArtist\(\s*'(\w+)'")
|
||||
|
||||
|
||||
def extract_interpreter_url(url: str) -> str:
|
||||
"""Extract artist ID from a Qobuz interpreter url.
|
||||
|
||||
:param url: Urls of the form "https://www.qobuz.com/us-en/interpreter/{artist}/download-streaming-albums"
|
||||
:type url: str
|
||||
:rtype: str
|
||||
"""
|
||||
session = gen_threadsafe_session({"User-Agent": AGENT})
|
||||
r = session.get(url)
|
||||
match = interpreter_artist_regex.search(r.text)
|
||||
if match:
|
||||
return match.group(1)
|
||||
|
||||
raise Exception(
|
||||
"Unable to extract artist id from interpreter url. Use a "
|
||||
"url that contains an artist id."
|
||||
)
|
||||
|
||||
|
||||
deezer_id_link_regex = re.compile(
|
||||
r"https://www\.deezer\.com/[a-z]{2}/(album|artist|playlist|track)/(\d+)"
|
||||
)
|
||||
|
||||
|
||||
def extract_deezer_dynamic_link(url: str) -> Tuple[str, str]:
|
||||
"""Extract a deezer url that includes an ID from a deezer.page.link url.
|
||||
|
||||
:param url:
|
||||
:type url: str
|
||||
:rtype: Tuple[str, str]
|
||||
"""
|
||||
session = gen_threadsafe_session({"User-Agent": AGENT})
|
||||
r = session.get(url)
|
||||
match = deezer_id_link_regex.search(r.text)
|
||||
if match:
|
||||
return match.group(1), match.group(2)
|
||||
|
||||
raise Exception("Unable to extract Deezer dynamic link.")
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
"""streamrip: the all in one music downloader."""
|
||||
from . import converter, db, exceptions, media, metadata
|
||||
from .config import Config
|
||||
|
||||
__version__ = "1.9.5"
|
||||
|
||||
from . import clients, constants, converter, downloadtools, media
|
||||
__all__ = ["Config", "media", "metadata", "converter", "db", "exceptions"]
|
||||
__version__ = "2.0.5"
|
||||
|
|
|
|||
|
|
@ -0,0 +1,16 @@
|
|||
from .client import Client
|
||||
from .deezer import DeezerClient
|
||||
from .downloadable import BasicDownloadable, Downloadable
|
||||
from .qobuz import QobuzClient
|
||||
from .soundcloud import SoundcloudClient
|
||||
from .tidal import TidalClient
|
||||
|
||||
__all__ = [
|
||||
"Client",
|
||||
"DeezerClient",
|
||||
"TidalClient",
|
||||
"QobuzClient",
|
||||
"SoundcloudClient",
|
||||
"Downloadable",
|
||||
"BasicDownloadable",
|
||||
]
|
||||
|
|
@ -0,0 +1,58 @@
|
|||
"""The clients that interact with the streaming service APIs."""
|
||||
|
||||
import contextlib
|
||||
import logging
|
||||
from abc import ABC, abstractmethod
|
||||
|
||||
import aiohttp
|
||||
import aiolimiter
|
||||
|
||||
from .downloadable import Downloadable
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
DEFAULT_USER_AGENT = (
|
||||
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:83.0) Gecko/20100101 Firefox/83.0"
|
||||
)
|
||||
|
||||
|
||||
class Client(ABC):
|
||||
source: str
|
||||
max_quality: int
|
||||
session: aiohttp.ClientSession
|
||||
logged_in: bool
|
||||
|
||||
@abstractmethod
|
||||
async def login(self):
|
||||
raise NotImplementedError
|
||||
|
||||
@abstractmethod
|
||||
async def get_metadata(self, item: str, media_type):
|
||||
raise NotImplementedError
|
||||
|
||||
@abstractmethod
|
||||
async def search(self, media_type: str, query: str, limit: int = 500) -> list[dict]:
|
||||
raise NotImplementedError
|
||||
|
||||
@abstractmethod
|
||||
async def get_downloadable(self, item: str, quality: int) -> Downloadable:
|
||||
raise NotImplementedError
|
||||
|
||||
@staticmethod
|
||||
def get_rate_limiter(
|
||||
requests_per_min: int,
|
||||
) -> aiolimiter.AsyncLimiter | contextlib.nullcontext:
|
||||
return (
|
||||
aiolimiter.AsyncLimiter(requests_per_min, 60)
|
||||
if requests_per_min > 0
|
||||
else contextlib.nullcontext()
|
||||
)
|
||||
|
||||
@staticmethod
|
||||
async def get_session(headers: dict | None = None) -> aiohttp.ClientSession:
|
||||
if headers is None:
|
||||
headers = {}
|
||||
return aiohttp.ClientSession(
|
||||
headers={"User-Agent": DEFAULT_USER_AGENT},
|
||||
**headers,
|
||||
)
|
||||
|
|
@ -0,0 +1,224 @@
|
|||
import asyncio
|
||||
import binascii
|
||||
import hashlib
|
||||
import logging
|
||||
|
||||
import deezer
|
||||
from Cryptodome.Cipher import AES
|
||||
|
||||
from ..config import Config
|
||||
from ..exceptions import (
|
||||
AuthenticationError,
|
||||
MissingCredentialsError,
|
||||
NonStreamableError,
|
||||
)
|
||||
from .client import Client
|
||||
from .downloadable import DeezerDownloadable
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
logging.captureWarnings(True)
|
||||
|
||||
|
||||
class DeezerClient(Client):
|
||||
"""Client to handle deezer API. Does not do rate limiting.
|
||||
|
||||
Attributes:
|
||||
global_config: Entire config object
|
||||
client: client from deezer py used for API requests
|
||||
logged_in: True if logged in
|
||||
config: deezer local config
|
||||
session: aiohttp.ClientSession, used only for track downloads not API requests
|
||||
|
||||
"""
|
||||
|
||||
source = "deezer"
|
||||
max_quality = 2
|
||||
|
||||
def __init__(self, config: Config):
|
||||
self.global_config = config
|
||||
self.client = deezer.Deezer()
|
||||
self.logged_in = False
|
||||
self.config = config.session.deezer
|
||||
|
||||
async def login(self):
|
||||
# Used for track downloads
|
||||
self.session = await self.get_session()
|
||||
arl = self.config.arl
|
||||
if not arl:
|
||||
raise MissingCredentialsError
|
||||
success = self.client.login_via_arl(arl)
|
||||
if not success:
|
||||
raise AuthenticationError
|
||||
self.logged_in = True
|
||||
|
||||
async def get_metadata(self, item_id: str, media_type: str) -> dict:
|
||||
# TODO: open asyncio PR to deezer py and integrate
|
||||
if media_type == "track":
|
||||
return await self.get_track(item_id)
|
||||
elif media_type == "album":
|
||||
return await self.get_album(item_id)
|
||||
elif media_type == "playlist":
|
||||
return await self.get_playlist(item_id)
|
||||
elif media_type == "artist":
|
||||
return await self.get_artist(item_id)
|
||||
else:
|
||||
raise Exception(f"Media type {media_type} not available on deezer")
|
||||
|
||||
async def get_track(self, item_id: str) -> dict:
|
||||
try:
|
||||
item = await asyncio.to_thread(self.client.api.get_track, item_id)
|
||||
except Exception as e:
|
||||
raise NonStreamableError(e)
|
||||
|
||||
album_id = item["album"]["id"]
|
||||
try:
|
||||
album_metadata, album_tracks = await asyncio.gather(
|
||||
asyncio.to_thread(self.client.api.get_album, album_id),
|
||||
asyncio.to_thread(self.client.api.get_album_tracks, album_id),
|
||||
)
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching album of track {item_id}: {e}")
|
||||
return item
|
||||
|
||||
album_metadata["tracks"] = album_tracks["data"]
|
||||
album_metadata["track_total"] = len(album_tracks["data"])
|
||||
item["album"] = album_metadata
|
||||
|
||||
return item
|
||||
|
||||
async def get_album(self, item_id: str) -> dict:
|
||||
album_metadata, album_tracks = await asyncio.gather(
|
||||
asyncio.to_thread(self.client.api.get_album, item_id),
|
||||
asyncio.to_thread(self.client.api.get_album_tracks, item_id),
|
||||
)
|
||||
album_metadata["tracks"] = album_tracks["data"]
|
||||
album_metadata["track_total"] = len(album_tracks["data"])
|
||||
return album_metadata
|
||||
|
||||
async def get_playlist(self, item_id: str) -> dict:
|
||||
pl_metadata, pl_tracks = await asyncio.gather(
|
||||
asyncio.to_thread(self.client.api.get_playlist, item_id),
|
||||
asyncio.to_thread(self.client.api.get_playlist_tracks, item_id),
|
||||
)
|
||||
pl_metadata["tracks"] = pl_tracks["data"]
|
||||
pl_metadata["track_total"] = len(pl_tracks["data"])
|
||||
return pl_metadata
|
||||
|
||||
async def get_artist(self, item_id: str) -> dict:
|
||||
artist, albums = await asyncio.gather(
|
||||
asyncio.to_thread(self.client.api.get_artist, item_id),
|
||||
asyncio.to_thread(self.client.api.get_artist_albums, item_id),
|
||||
)
|
||||
artist["albums"] = albums["data"]
|
||||
return artist
|
||||
|
||||
async def search(self, media_type: str, query: str, limit: int = 200) -> list[dict]:
|
||||
# TODO: use limit parameter
|
||||
if media_type == "featured":
|
||||
try:
|
||||
if query:
|
||||
search_function = getattr(self.client.api, f"get_editorial_{query}")
|
||||
else:
|
||||
search_function = self.client.api.get_editorial_releases
|
||||
except AttributeError:
|
||||
raise Exception(f'Invalid editorical selection "{query}"')
|
||||
else:
|
||||
try:
|
||||
search_function = getattr(self.client.api, f"search_{media_type}")
|
||||
except AttributeError:
|
||||
raise Exception(f"Invalid media type {media_type}")
|
||||
|
||||
response = search_function(query, limit=limit) # type: ignore
|
||||
if response["total"] > 0:
|
||||
return [response]
|
||||
return []
|
||||
|
||||
async def get_downloadable(
|
||||
self,
|
||||
item_id: str,
|
||||
quality: int = 2,
|
||||
is_retry: bool = False,
|
||||
) -> DeezerDownloadable:
|
||||
if item_id is None:
|
||||
raise NonStreamableError(
|
||||
"No item id provided. This can happen when searching for fallback songs.",
|
||||
)
|
||||
# TODO: optimize such that all of the ids are requested at once
|
||||
dl_info: dict = {"quality": quality, "id": item_id}
|
||||
|
||||
track_info = self.client.gw.get_track(item_id)
|
||||
|
||||
fallback_id = track_info.get("FALLBACK", {}).get("SNG_ID")
|
||||
|
||||
quality_map = [
|
||||
(9, "MP3_128"), # quality 0
|
||||
(3, "MP3_320"), # quality 1
|
||||
(1, "FLAC"), # quality 2
|
||||
]
|
||||
|
||||
_, format_str = quality_map[quality]
|
||||
|
||||
dl_info["quality_to_size"] = [
|
||||
int(track_info.get(f"FILESIZE_{format}", 0)) for _, format in quality_map
|
||||
]
|
||||
|
||||
token = track_info["TRACK_TOKEN"]
|
||||
try:
|
||||
logger.debug("Fetching deezer url with token %s", token)
|
||||
url = self.client.get_track_url(token, format_str)
|
||||
except deezer.WrongLicense:
|
||||
raise NonStreamableError(
|
||||
"The requested quality is not available with your subscription. "
|
||||
"Deezer HiFi is required for quality 2. Otherwise, the maximum "
|
||||
"quality allowed is 1.",
|
||||
)
|
||||
except deezer.WrongGeolocation:
|
||||
if not is_retry:
|
||||
return await self.get_downloadable(fallback_id, quality, is_retry=True)
|
||||
raise NonStreamableError(
|
||||
"The requested track is not available. This may be due to your country/location.",
|
||||
)
|
||||
|
||||
if url is None:
|
||||
url = self._get_encrypted_file_url(
|
||||
item_id,
|
||||
track_info["MD5_ORIGIN"],
|
||||
track_info["MEDIA_VERSION"],
|
||||
)
|
||||
|
||||
dl_info["url"] = url
|
||||
logger.debug("dz track info: %s", track_info)
|
||||
return DeezerDownloadable(self.session, dl_info)
|
||||
|
||||
def _get_encrypted_file_url(
|
||||
self,
|
||||
meta_id: str,
|
||||
track_hash: str,
|
||||
media_version: str,
|
||||
):
|
||||
logger.debug("Unable to fetch URL. Trying encryption method.")
|
||||
format_number = 1
|
||||
|
||||
url_bytes = b"\xa4".join(
|
||||
(
|
||||
track_hash.encode(),
|
||||
str(format_number).encode(),
|
||||
str(meta_id).encode(),
|
||||
str(media_version).encode(),
|
||||
),
|
||||
)
|
||||
url_hash = hashlib.md5(url_bytes).hexdigest()
|
||||
info_bytes = bytearray(url_hash.encode())
|
||||
info_bytes.extend(b"\xa4")
|
||||
info_bytes.extend(url_bytes)
|
||||
info_bytes.extend(b"\xa4")
|
||||
# Pad the bytes so that len(info_bytes) % 16 == 0
|
||||
padding_len = 16 - (len(info_bytes) % 16)
|
||||
info_bytes.extend(b"." * padding_len)
|
||||
|
||||
path = binascii.hexlify(
|
||||
AES.new(b"jo6aey6haid2Teih", AES.MODE_ECB).encrypt(info_bytes),
|
||||
).decode("utf-8")
|
||||
url = f"https://e-cdns-proxy-{track_hash[0]}.dzcdn.net/mobile/1/{path}"
|
||||
logger.debug("Encrypted file path %s", url)
|
||||
return url
|
||||
|
|
@ -0,0 +1,429 @@
|
|||
import asyncio
|
||||
import base64
|
||||
import functools
|
||||
import hashlib
|
||||
import itertools
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
import shutil
|
||||
import tempfile
|
||||
import time
|
||||
from abc import ABC, abstractmethod
|
||||
from dataclasses import dataclass
|
||||
from typing import Any, Callable, Optional
|
||||
|
||||
import aiofiles
|
||||
import aiohttp
|
||||
import m3u8
|
||||
import requests
|
||||
from Cryptodome.Cipher import AES, Blowfish
|
||||
from Cryptodome.Util import Counter
|
||||
|
||||
from .. import converter
|
||||
from ..exceptions import NonStreamableError
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
|
||||
BLOWFISH_SECRET = "g4el58wc0zvf9na1"
|
||||
|
||||
|
||||
def generate_temp_path(url: str):
|
||||
return os.path.join(
|
||||
tempfile.gettempdir(),
|
||||
f"__streamrip_{hash(url)}_{time.time()}.download",
|
||||
)
|
||||
|
||||
|
||||
async def fast_async_download(path, url, headers, callback):
|
||||
"""Synchronous download with yield for every 1MB read.
|
||||
|
||||
Using aiofiles/aiohttp resulted in a yield to the event loop for every 1KB,
|
||||
which made file downloads CPU-bound. This resulted in a ~10MB max total download
|
||||
speed. This fixes the issue by only yielding to the event loop for every 1MB read.
|
||||
"""
|
||||
chunk_size: int = 2**17 # 131 KB
|
||||
counter = 0
|
||||
yield_every = 8 # 1 MB
|
||||
with open(path, "wb") as file: # noqa: ASYNC101
|
||||
with requests.get( # noqa: ASYNC100
|
||||
url,
|
||||
headers=headers,
|
||||
allow_redirects=True,
|
||||
stream=True,
|
||||
) as resp:
|
||||
for chunk in resp.iter_content(chunk_size=chunk_size):
|
||||
file.write(chunk)
|
||||
callback(len(chunk))
|
||||
if counter % yield_every == 0:
|
||||
await asyncio.sleep(0)
|
||||
counter += 1
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class Downloadable(ABC):
|
||||
session: aiohttp.ClientSession
|
||||
url: str
|
||||
extension: str
|
||||
source: str = "Unknown"
|
||||
_size_base: Optional[int] = None
|
||||
|
||||
async def download(self, path: str, callback: Callable[[int], Any]):
|
||||
await self._download(path, callback)
|
||||
|
||||
async def size(self) -> int:
|
||||
if hasattr(self, "_size") and self._size is not None:
|
||||
return self._size
|
||||
|
||||
async with self.session.head(self.url) as response:
|
||||
response.raise_for_status()
|
||||
content_length = response.headers.get("Content-Length", 0)
|
||||
self._size = int(content_length)
|
||||
return self._size
|
||||
|
||||
@property
|
||||
def _size(self):
|
||||
return self._size_base
|
||||
|
||||
@_size.setter
|
||||
def _size(self, v):
|
||||
self._size_base = v
|
||||
|
||||
@abstractmethod
|
||||
async def _download(self, path: str, callback: Callable[[int], None]):
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
class BasicDownloadable(Downloadable):
|
||||
"""Just downloads a URL."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
session: aiohttp.ClientSession,
|
||||
url: str,
|
||||
extension: str,
|
||||
source: str | None = None,
|
||||
):
|
||||
self.session = session
|
||||
self.url = url
|
||||
self.extension = extension
|
||||
self._size = None
|
||||
self.source: str = source or "Unknown"
|
||||
|
||||
async def _download(self, path: str, callback):
|
||||
await fast_async_download(path, self.url, self.session.headers, callback)
|
||||
|
||||
|
||||
class DeezerDownloadable(Downloadable):
|
||||
is_encrypted = re.compile("/m(?:obile|edia)/")
|
||||
|
||||
def __init__(self, session: aiohttp.ClientSession, info: dict):
|
||||
logger.debug("Deezer info for downloadable: %s", info)
|
||||
self.session = session
|
||||
self.url = info["url"]
|
||||
self.source: str = "deezer"
|
||||
max_quality_available = max(
|
||||
i for i, size in enumerate(info["quality_to_size"]) if size > 0
|
||||
)
|
||||
self.quality = min(info["quality"], max_quality_available)
|
||||
self._size = info["quality_to_size"][self.quality]
|
||||
if self.quality <= 1:
|
||||
self.extension = "mp3"
|
||||
else:
|
||||
self.extension = "flac"
|
||||
self.id = str(info["id"])
|
||||
|
||||
async def _download(self, path: str, callback):
|
||||
# with requests.Session().get(self.url, allow_redirects=True) as resp:
|
||||
async with self.session.get(self.url, allow_redirects=True) as resp:
|
||||
resp.raise_for_status()
|
||||
self._size = int(resp.headers.get("Content-Length", 0))
|
||||
if self._size < 20000 and not self.url.endswith(".jpg"):
|
||||
try:
|
||||
info = await resp.json()
|
||||
try:
|
||||
# Usually happens with deezloader downloads
|
||||
raise NonStreamableError(f"{info['error']} - {info['message']}")
|
||||
except KeyError:
|
||||
raise NonStreamableError(info)
|
||||
|
||||
except json.JSONDecodeError:
|
||||
raise NonStreamableError("File not found.")
|
||||
|
||||
if self.is_encrypted.search(self.url) is None:
|
||||
logger.debug(f"Deezer file at {self.url} not encrypted.")
|
||||
await fast_async_download(
|
||||
path, self.url, self.session.headers, callback
|
||||
)
|
||||
else:
|
||||
blowfish_key = self._generate_blowfish_key(self.id)
|
||||
logger.debug(
|
||||
"Deezer file (id %s) at %s is encrypted. Decrypting with %s",
|
||||
self.id,
|
||||
self.url,
|
||||
blowfish_key,
|
||||
)
|
||||
|
||||
buf = bytearray()
|
||||
async for data, _ in resp.content.iter_chunks():
|
||||
buf += data
|
||||
callback(len(data))
|
||||
|
||||
encrypt_chunk_size = 3 * 2048
|
||||
async with aiofiles.open(path, "wb") as audio:
|
||||
buflen = len(buf)
|
||||
for i in range(0, buflen, encrypt_chunk_size):
|
||||
data = buf[i : min(i + encrypt_chunk_size, buflen)]
|
||||
if len(data) >= 2048:
|
||||
decrypted_chunk = (
|
||||
self._decrypt_chunk(blowfish_key, data[:2048])
|
||||
+ data[2048:]
|
||||
)
|
||||
else:
|
||||
decrypted_chunk = data
|
||||
await audio.write(decrypted_chunk)
|
||||
|
||||
@staticmethod
|
||||
def _decrypt_chunk(key, data):
|
||||
"""Decrypt a chunk of a Deezer stream.
|
||||
|
||||
:param key:
|
||||
:param data:
|
||||
"""
|
||||
return Blowfish.new(
|
||||
key,
|
||||
Blowfish.MODE_CBC,
|
||||
b"\x00\x01\x02\x03\x04\x05\x06\x07",
|
||||
).decrypt(data)
|
||||
|
||||
@staticmethod
|
||||
def _generate_blowfish_key(track_id: str) -> bytes:
|
||||
"""Generate the blowfish key for Deezer downloads.
|
||||
|
||||
:param track_id:
|
||||
:type track_id: str
|
||||
"""
|
||||
md5_hash = hashlib.md5(track_id.encode()).hexdigest()
|
||||
# good luck :)
|
||||
return "".join(
|
||||
chr(functools.reduce(lambda x, y: x ^ y, map(ord, t)))
|
||||
for t in zip(md5_hash[:16], md5_hash[16:], BLOWFISH_SECRET)
|
||||
).encode()
|
||||
|
||||
|
||||
class TidalDownloadable(Downloadable):
|
||||
"""A wrapper around BasicDownloadable that includes Tidal-specific
|
||||
error messages.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
session: aiohttp.ClientSession,
|
||||
url: str | None,
|
||||
codec: str,
|
||||
encryption_key: str | None,
|
||||
restrictions,
|
||||
):
|
||||
self.session = session
|
||||
self.source = "tidal"
|
||||
codec = codec.lower()
|
||||
if codec in ("flac", "mqa"):
|
||||
self.extension = "flac"
|
||||
else:
|
||||
self.extension = "m4a"
|
||||
|
||||
if url is None:
|
||||
# Turn CamelCase code into a readable sentence
|
||||
if restrictions:
|
||||
words = re.findall(r"([A-Z][a-z]+)", restrictions[0]["code"])
|
||||
raise NonStreamableError(
|
||||
words[0] + " " + " ".join(map(str.lower, words[1:])),
|
||||
)
|
||||
raise NonStreamableError(
|
||||
f"Tidal download: dl_info = {url, codec, encryption_key}"
|
||||
)
|
||||
self.url = url
|
||||
self.enc_key = encryption_key
|
||||
self.downloadable = BasicDownloadable(session, url, self.extension, "tidal")
|
||||
|
||||
async def _download(self, path: str, callback):
|
||||
await self.downloadable._download(path, callback)
|
||||
if self.enc_key is not None:
|
||||
dec_bytes = await self._decrypt_mqa_file(path, self.enc_key)
|
||||
async with aiofiles.open(path, "wb") as audio:
|
||||
await audio.write(dec_bytes)
|
||||
|
||||
@property
|
||||
def _size(self):
|
||||
return self.downloadable._size
|
||||
|
||||
@_size.setter
|
||||
def _size(self, v):
|
||||
self.downloadable._size = v
|
||||
|
||||
@staticmethod
|
||||
async def _decrypt_mqa_file(in_path, encryption_key):
|
||||
"""Decrypt an MQA file.
|
||||
|
||||
:param in_path:
|
||||
:param out_path:
|
||||
:param encryption_key:
|
||||
"""
|
||||
|
||||
# Do not change this
|
||||
master_key = "UIlTTEMmmLfGowo/UC60x2H45W6MdGgTRfo/umg4754="
|
||||
|
||||
# Decode the base64 strings to ascii strings
|
||||
master_key = base64.b64decode(master_key)
|
||||
security_token = base64.b64decode(encryption_key)
|
||||
|
||||
# Get the IV from the first 16 bytes of the securityToken
|
||||
iv = security_token[:16]
|
||||
encrypted_st = security_token[16:]
|
||||
|
||||
# Initialize decryptor
|
||||
decryptor = AES.new(master_key, AES.MODE_CBC, iv)
|
||||
|
||||
# Decrypt the security token
|
||||
decrypted_st = decryptor.decrypt(encrypted_st)
|
||||
|
||||
# Get the audio stream decryption key and nonce from the decrypted security token
|
||||
key = decrypted_st[:16]
|
||||
nonce = decrypted_st[16:24]
|
||||
|
||||
counter = Counter.new(64, prefix=nonce, initial_value=0)
|
||||
decryptor = AES.new(key, AES.MODE_CTR, counter=counter)
|
||||
|
||||
async with aiofiles.open(in_path, "rb") as enc_file:
|
||||
dec_bytes = decryptor.decrypt(await enc_file.read())
|
||||
return dec_bytes
|
||||
|
||||
|
||||
class SoundcloudDownloadable(Downloadable):
|
||||
def __init__(self, session, info: dict):
|
||||
self.session = session
|
||||
self.file_type = info["type"]
|
||||
self.source = "soundcloud"
|
||||
if self.file_type == "mp3":
|
||||
self.extension = "mp3"
|
||||
elif self.file_type == "original":
|
||||
self.extension = "flac"
|
||||
else:
|
||||
raise Exception(f"Invalid file type: {self.file_type}")
|
||||
self.url = info["url"]
|
||||
|
||||
async def _download(self, path, callback):
|
||||
if self.file_type == "mp3":
|
||||
await self._download_mp3(path, callback)
|
||||
else:
|
||||
await self._download_original(path, callback)
|
||||
|
||||
async def _download_original(self, path: str, callback):
|
||||
downloader = BasicDownloadable(
|
||||
self.session, self.url, "flac", source="soundcloud"
|
||||
)
|
||||
await downloader.download(path, callback)
|
||||
self.size = downloader.size
|
||||
engine = converter.FLAC(path)
|
||||
await engine.convert(path)
|
||||
|
||||
async def _download_mp3(self, path: str, callback):
|
||||
# TODO: make progress bar reflect bytes
|
||||
async with self.session.get(self.url) as resp:
|
||||
content = await resp.text("utf-8")
|
||||
|
||||
parsed_m3u = m3u8.loads(content)
|
||||
self._size = len(parsed_m3u.segments)
|
||||
tasks = [
|
||||
asyncio.create_task(self._download_segment(segment.uri))
|
||||
for segment in parsed_m3u.segments
|
||||
]
|
||||
|
||||
segment_paths = []
|
||||
for coro in asyncio.as_completed(tasks):
|
||||
segment_paths.append(await coro)
|
||||
callback(1)
|
||||
|
||||
await concat_audio_files(segment_paths, path, "mp3")
|
||||
|
||||
async def _download_segment(self, segment_uri: str) -> str:
|
||||
tmp = generate_temp_path(segment_uri)
|
||||
async with self.session.get(segment_uri) as resp:
|
||||
resp.raise_for_status()
|
||||
async with aiofiles.open(tmp, "wb") as file:
|
||||
content = await resp.content.read()
|
||||
await file.write(content)
|
||||
return tmp
|
||||
|
||||
async def size(self) -> int:
|
||||
if self.file_type == "mp3":
|
||||
async with self.session.get(self.url) as resp:
|
||||
content = await resp.text("utf-8")
|
||||
|
||||
parsed_m3u = m3u8.loads(content)
|
||||
self._size = len(parsed_m3u.segments)
|
||||
return await super().size()
|
||||
|
||||
|
||||
async def concat_audio_files(paths: list[str], out: str, ext: str, max_files_open=128):
|
||||
"""Concatenate audio files using FFmpeg. Batched by max files open.
|
||||
|
||||
Recurses log_{max_file_open}(len(paths)) times.
|
||||
"""
|
||||
if shutil.which("ffmpeg") is None:
|
||||
raise Exception("FFmpeg must be installed.")
|
||||
|
||||
# Base case
|
||||
if len(paths) == 1:
|
||||
shutil.move(paths[0], out)
|
||||
return
|
||||
|
||||
it = iter(paths)
|
||||
num_batches = len(paths) // max_files_open + (
|
||||
1 if len(paths) % max_files_open != 0 else 0
|
||||
)
|
||||
tempdir = tempfile.gettempdir()
|
||||
outpaths = [
|
||||
os.path.join(
|
||||
tempdir,
|
||||
f"__streamrip_ffmpeg_{hash(paths[i*max_files_open])}.{ext}",
|
||||
)
|
||||
for i in range(num_batches)
|
||||
]
|
||||
|
||||
for p in outpaths:
|
||||
try:
|
||||
os.remove(p) # in case of failure
|
||||
except FileNotFoundError:
|
||||
pass
|
||||
|
||||
proc_futures = []
|
||||
for i in range(num_batches):
|
||||
command = (
|
||||
"ffmpeg",
|
||||
"-i",
|
||||
f"concat:{'|'.join(itertools.islice(it, max_files_open))}",
|
||||
"-acodec",
|
||||
"copy",
|
||||
"-loglevel",
|
||||
"warning",
|
||||
outpaths[i],
|
||||
)
|
||||
fut = asyncio.create_subprocess_exec(*command, stderr=asyncio.subprocess.PIPE)
|
||||
proc_futures.append(fut)
|
||||
|
||||
# Create all processes concurrently
|
||||
processes = await asyncio.gather(*proc_futures)
|
||||
|
||||
# wait for all of them to finish
|
||||
await asyncio.gather(*[p.communicate() for p in processes])
|
||||
for proc in processes:
|
||||
if proc.returncode != 0:
|
||||
raise Exception(
|
||||
f"FFMPEG returned with status code {proc.returncode} error: {proc.stderr} output: {proc.stdout}",
|
||||
)
|
||||
|
||||
# Recurse on remaining batches
|
||||
await concat_audio_files(outpaths, out, ext)
|
||||
|
|
@ -0,0 +1,437 @@
|
|||
import asyncio
|
||||
import base64
|
||||
import hashlib
|
||||
import logging
|
||||
import re
|
||||
import time
|
||||
from collections import OrderedDict
|
||||
from typing import List, Optional
|
||||
|
||||
import aiohttp
|
||||
|
||||
from ..config import Config
|
||||
from ..exceptions import (
|
||||
AuthenticationError,
|
||||
IneligibleError,
|
||||
InvalidAppIdError,
|
||||
InvalidAppSecretError,
|
||||
MissingCredentialsError,
|
||||
NonStreamableError,
|
||||
)
|
||||
from .client import Client
|
||||
from .downloadable import BasicDownloadable, Downloadable
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
QOBUZ_BASE_URL = "https://www.qobuz.com/api.json/0.2"
|
||||
|
||||
QOBUZ_FEATURED_KEYS = {
|
||||
"most-streamed",
|
||||
"recent-releases",
|
||||
"best-sellers",
|
||||
"press-awards",
|
||||
"ideal-discography",
|
||||
"editor-picks",
|
||||
"most-featured",
|
||||
"qobuzissims",
|
||||
"new-releases",
|
||||
"new-releases-full",
|
||||
"harmonia-mundi",
|
||||
"universal-classic",
|
||||
"universal-jazz",
|
||||
"universal-jeunesse",
|
||||
"universal-chanson",
|
||||
}
|
||||
|
||||
|
||||
class QobuzSpoofer:
|
||||
"""Spoofs the information required to stream tracks from Qobuz."""
|
||||
|
||||
def __init__(self):
|
||||
"""Create a Spoofer."""
|
||||
self.seed_timezone_regex = (
|
||||
r'[a-z]\.initialSeed\("(?P<seed>[\w=]+)",window\.ut'
|
||||
r"imezone\.(?P<timezone>[a-z]+)\)"
|
||||
)
|
||||
# note: {timezones} should be replaced with every capitalized timezone joined by a |
|
||||
self.info_extras_regex = (
|
||||
r'name:"\w+/(?P<timezone>{timezones})",info:"'
|
||||
r'(?P<info>[\w=]+)",extras:"(?P<extras>[\w=]+)"'
|
||||
)
|
||||
self.app_id_regex = (
|
||||
r'production:{api:{appId:"(?P<app_id>\d{9})",appSecret:"(\w{32})'
|
||||
)
|
||||
self.session = None
|
||||
|
||||
async def get_app_id_and_secrets(self) -> tuple[str, list[str]]:
|
||||
assert self.session is not None
|
||||
async with self.session.get("https://play.qobuz.com/login") as req:
|
||||
login_page = await req.text()
|
||||
|
||||
bundle_url_match = re.search(
|
||||
r'<script src="(/resources/\d+\.\d+\.\d+-[a-z]\d{3}/bundle\.js)"></script>',
|
||||
login_page,
|
||||
)
|
||||
assert bundle_url_match is not None
|
||||
bundle_url = bundle_url_match.group(1)
|
||||
|
||||
async with self.session.get("https://play.qobuz.com" + bundle_url) as req:
|
||||
self.bundle = await req.text()
|
||||
|
||||
match = re.search(self.app_id_regex, self.bundle)
|
||||
if match is None:
|
||||
raise Exception("Could not find app id.")
|
||||
|
||||
app_id = str(match.group("app_id"))
|
||||
|
||||
# get secrets
|
||||
seed_matches = re.finditer(self.seed_timezone_regex, self.bundle)
|
||||
secrets = OrderedDict()
|
||||
for match in seed_matches:
|
||||
seed, timezone = match.group("seed", "timezone")
|
||||
secrets[timezone] = [seed]
|
||||
|
||||
"""
|
||||
The code that follows switches around the first and second timezone.
|
||||
Qobuz uses two ternary (a shortened if statement) conditions that
|
||||
should always return false. The way Javascript's ternary syntax
|
||||
works, the second option listed is what runs if the condition returns
|
||||
false. Because of this, we must prioritize the *second* seed/timezone
|
||||
pair captured, not the first.
|
||||
"""
|
||||
|
||||
keypairs = list(secrets.items())
|
||||
secrets.move_to_end(keypairs[1][0], last=False)
|
||||
|
||||
info_extras_regex = self.info_extras_regex.format(
|
||||
timezones="|".join(timezone.capitalize() for timezone in secrets),
|
||||
)
|
||||
info_extras_matches = re.finditer(info_extras_regex, self.bundle)
|
||||
for match in info_extras_matches:
|
||||
timezone, info, extras = match.group("timezone", "info", "extras")
|
||||
secrets[timezone.lower()] += [info, extras]
|
||||
|
||||
for secret_pair in secrets:
|
||||
secrets[secret_pair] = base64.standard_b64decode(
|
||||
"".join(secrets[secret_pair])[:-44],
|
||||
).decode("utf-8")
|
||||
|
||||
vals: List[str] = list(secrets.values())
|
||||
vals.remove("")
|
||||
|
||||
secrets_list = vals
|
||||
|
||||
return app_id, secrets_list
|
||||
|
||||
async def __aenter__(self):
|
||||
self.session = aiohttp.ClientSession()
|
||||
return self
|
||||
|
||||
async def __aexit__(self, *_):
|
||||
if self.session is not None:
|
||||
await self.session.close()
|
||||
self.session = None
|
||||
|
||||
|
||||
class QobuzClient(Client):
|
||||
source = "qobuz"
|
||||
max_quality = 4
|
||||
|
||||
def __init__(self, config: Config):
|
||||
self.logged_in = False
|
||||
self.config = config
|
||||
self.rate_limiter = self.get_rate_limiter(
|
||||
config.session.downloads.requests_per_minute,
|
||||
)
|
||||
self.secret: Optional[str] = None
|
||||
|
||||
async def login(self):
|
||||
self.session = await self.get_session()
|
||||
c = self.config.session.qobuz
|
||||
if not c.email_or_userid or not c.password_or_token:
|
||||
raise MissingCredentialsError
|
||||
|
||||
assert not self.logged_in, "Already logged in"
|
||||
|
||||
if not c.app_id or not c.secrets:
|
||||
logger.info("App id/secrets not found, fetching")
|
||||
c.app_id, c.secrets = await self._get_app_id_and_secrets()
|
||||
# write to file
|
||||
f = self.config.file
|
||||
f.qobuz.app_id = c.app_id
|
||||
f.qobuz.secrets = c.secrets
|
||||
f.set_modified()
|
||||
|
||||
self.session.headers.update({"X-App-Id": c.app_id})
|
||||
self.secret = await self._get_valid_secret(c.secrets)
|
||||
|
||||
if c.use_auth_token:
|
||||
params = {
|
||||
"user_id": c.email_or_userid,
|
||||
"user_auth_token": c.password_or_token,
|
||||
"app_id": c.app_id,
|
||||
}
|
||||
else:
|
||||
params = {
|
||||
"email": c.email_or_userid,
|
||||
"password": c.password_or_token,
|
||||
"app_id": c.app_id,
|
||||
}
|
||||
|
||||
logger.debug("Request params %s", params)
|
||||
status, resp = await self._api_request("user/login", params)
|
||||
logger.debug("Login resp: %s", resp)
|
||||
|
||||
if status == 401:
|
||||
raise AuthenticationError(f"Invalid credentials from params {params}")
|
||||
elif status == 400:
|
||||
raise InvalidAppIdError(f"Invalid app id from params {params}")
|
||||
|
||||
logger.debug("Logged in to Qobuz")
|
||||
|
||||
if not resp["user"]["credential"]["parameters"]:
|
||||
raise IneligibleError("Free accounts are not eligible to download tracks.")
|
||||
|
||||
uat = resp["user_auth_token"]
|
||||
self.session.headers.update({"X-User-Auth-Token": uat})
|
||||
|
||||
self.logged_in = True
|
||||
|
||||
async def get_metadata(self, item: str, media_type: str):
|
||||
if media_type == "label":
|
||||
return await self.get_label(item)
|
||||
|
||||
c = self.config.session.qobuz
|
||||
params = {
|
||||
"app_id": c.app_id,
|
||||
f"{media_type}_id": item,
|
||||
# Do these matter?
|
||||
"limit": 500,
|
||||
"offset": 0,
|
||||
}
|
||||
|
||||
extras = {
|
||||
"artist": "albums",
|
||||
"playlist": "tracks",
|
||||
"label": "albums",
|
||||
}
|
||||
|
||||
if media_type in extras:
|
||||
params.update({"extra": extras[media_type]})
|
||||
|
||||
logger.debug("request params: %s", params)
|
||||
|
||||
epoint = f"{media_type}/get"
|
||||
|
||||
status, resp = await self._api_request(epoint, params)
|
||||
|
||||
if status != 200:
|
||||
raise NonStreamableError(
|
||||
f'Error fetching metadata. Message: "{resp["message"]}"',
|
||||
)
|
||||
|
||||
return resp
|
||||
|
||||
async def get_label(self, label_id: str) -> dict:
|
||||
c = self.config.session.qobuz
|
||||
page_limit = 500
|
||||
params = {
|
||||
"app_id": c.app_id,
|
||||
"label_id": label_id,
|
||||
"limit": page_limit,
|
||||
"offset": 0,
|
||||
"extra": "albums",
|
||||
}
|
||||
epoint = "label/get"
|
||||
status, label_resp = await self._api_request(epoint, params)
|
||||
assert status == 200
|
||||
albums_count = label_resp["albums_count"]
|
||||
|
||||
if albums_count <= page_limit:
|
||||
return label_resp
|
||||
|
||||
requests = [
|
||||
self._api_request(
|
||||
epoint,
|
||||
{
|
||||
"app_id": c.app_id,
|
||||
"label_id": label_id,
|
||||
"limit": page_limit,
|
||||
"offset": offset,
|
||||
"extra": "albums",
|
||||
},
|
||||
)
|
||||
for offset in range(page_limit, albums_count, page_limit)
|
||||
]
|
||||
|
||||
results = await asyncio.gather(*requests)
|
||||
items = label_resp["albums"]["items"]
|
||||
for status, resp in results:
|
||||
assert status == 200
|
||||
items.extend(resp["albums"]["items"])
|
||||
|
||||
return label_resp
|
||||
|
||||
async def search(self, media_type: str, query: str, limit: int = 500) -> list[dict]:
|
||||
if media_type not in ("artist", "album", "track", "playlist"):
|
||||
raise Exception(f"{media_type} not available for search on qobuz")
|
||||
|
||||
params = {
|
||||
"query": query,
|
||||
}
|
||||
epoint = f"{media_type}/search"
|
||||
|
||||
return await self._paginate(epoint, params, limit=limit)
|
||||
|
||||
async def get_featured(self, query, limit: int = 500) -> list[dict]:
|
||||
params = {
|
||||
"type": query,
|
||||
}
|
||||
assert query in QOBUZ_FEATURED_KEYS, f'query "{query}" is invalid.'
|
||||
epoint = "album/getFeatured"
|
||||
return await self._paginate(epoint, params, limit=limit)
|
||||
|
||||
async def get_user_favorites(self, media_type: str, limit: int = 500) -> list[dict]:
|
||||
assert media_type in ("track", "artist", "album")
|
||||
params = {"type": f"{media_type}s"}
|
||||
epoint = "favorite/getUserFavorites"
|
||||
|
||||
return await self._paginate(epoint, params, limit=limit)
|
||||
|
||||
async def get_user_playlists(self, limit: int = 500) -> list[dict]:
|
||||
epoint = "playlist/getUserPlaylists"
|
||||
return await self._paginate(epoint, {}, limit=limit)
|
||||
|
||||
async def get_downloadable(self, item: str, quality: int) -> Downloadable:
|
||||
assert self.secret is not None and self.logged_in and 1 <= quality <= 4
|
||||
status, resp_json = await self._request_file_url(item, quality, self.secret)
|
||||
assert status == 200
|
||||
stream_url = resp_json.get("url")
|
||||
|
||||
if stream_url is None:
|
||||
restrictions = resp_json["restrictions"]
|
||||
if restrictions:
|
||||
# Turn CamelCase code into a readable sentence
|
||||
words = re.findall(r"([A-Z][a-z]+)", restrictions[0]["code"])
|
||||
raise NonStreamableError(
|
||||
words[0] + " " + " ".join(map(str.lower, words[1:])) + ".",
|
||||
)
|
||||
raise NonStreamableError
|
||||
|
||||
return BasicDownloadable(
|
||||
self.session, stream_url, "flac" if quality > 1 else "mp3", source="qobuz"
|
||||
)
|
||||
|
||||
async def _paginate(
|
||||
self,
|
||||
epoint: str,
|
||||
params: dict,
|
||||
limit: int = 500,
|
||||
) -> list[dict]:
|
||||
"""Paginate search results.
|
||||
|
||||
params:
|
||||
limit: If None, all the results are yielded. Otherwise a maximum
|
||||
of `limit` results are yielded.
|
||||
|
||||
Returns
|
||||
-------
|
||||
Generator that yields (status code, response) tuples
|
||||
"""
|
||||
params.update({"limit": limit})
|
||||
status, page = await self._api_request(epoint, params)
|
||||
assert status == 200, status
|
||||
logger.debug("paginate: initial request made with status %d", status)
|
||||
# albums, tracks, etc.
|
||||
key = epoint.split("/")[0] + "s"
|
||||
items = page.get(key, {})
|
||||
total = items.get("total", 0)
|
||||
if limit is not None and limit < total:
|
||||
total = limit
|
||||
|
||||
logger.debug("paginate: %d total items requested", total)
|
||||
|
||||
if total == 0:
|
||||
logger.debug("Nothing found from %s epoint", epoint)
|
||||
return []
|
||||
|
||||
limit = int(page.get(key, {}).get("limit", 500))
|
||||
offset = int(page.get(key, {}).get("offset", 0))
|
||||
|
||||
logger.debug("paginate: from response: limit=%d, offset=%d", limit, offset)
|
||||
params.update({"limit": limit})
|
||||
|
||||
pages = []
|
||||
requests = []
|
||||
assert status == 200, status
|
||||
pages.append(page)
|
||||
while (offset + limit) < total:
|
||||
offset += limit
|
||||
params.update({"offset": offset})
|
||||
requests.append(self._api_request(epoint, params.copy()))
|
||||
|
||||
for status, resp in await asyncio.gather(*requests):
|
||||
assert status == 200
|
||||
pages.append(resp)
|
||||
|
||||
return pages
|
||||
|
||||
async def _get_app_id_and_secrets(self) -> tuple[str, list[str]]:
|
||||
async with QobuzSpoofer() as spoofer:
|
||||
return await spoofer.get_app_id_and_secrets()
|
||||
|
||||
async def _get_valid_secret(self, secrets: list[str]) -> str:
|
||||
results = await asyncio.gather(
|
||||
*[self._test_secret(secret) for secret in secrets],
|
||||
)
|
||||
working_secrets = [r for r in results if r is not None]
|
||||
|
||||
if len(working_secrets) == 0:
|
||||
raise InvalidAppSecretError(secrets)
|
||||
|
||||
return working_secrets[0]
|
||||
|
||||
async def _test_secret(self, secret: str) -> Optional[str]:
|
||||
status, _ = await self._request_file_url("19512574", 4, secret)
|
||||
if status == 400:
|
||||
return None
|
||||
if status == 200:
|
||||
return secret
|
||||
logger.warning("Got status %d when testing secret", status)
|
||||
return None
|
||||
|
||||
async def _request_file_url(
|
||||
self,
|
||||
track_id: str,
|
||||
quality: int,
|
||||
secret: str,
|
||||
) -> tuple[int, dict]:
|
||||
quality = self.get_quality(quality)
|
||||
unix_ts = time.time()
|
||||
r_sig = f"trackgetFileUrlformat_id{quality}intentstreamtrack_id{track_id}{unix_ts}{secret}"
|
||||
logger.debug("Raw request signature: %s", r_sig)
|
||||
r_sig_hashed = hashlib.md5(r_sig.encode("utf-8")).hexdigest()
|
||||
logger.debug("Hashed request signature: %s", r_sig_hashed)
|
||||
params = {
|
||||
"request_ts": unix_ts,
|
||||
"request_sig": r_sig_hashed,
|
||||
"track_id": track_id,
|
||||
"format_id": quality,
|
||||
"intent": "stream",
|
||||
}
|
||||
return await self._api_request("track/getFileUrl", params)
|
||||
|
||||
async def _api_request(self, epoint: str, params: dict) -> tuple[int, dict]:
|
||||
"""Make a request to the API.
|
||||
returns: status code, json parsed response
|
||||
"""
|
||||
url = f"{QOBUZ_BASE_URL}/{epoint}"
|
||||
logger.debug("api_request: endpoint=%s, params=%s", epoint, params)
|
||||
async with self.rate_limiter:
|
||||
async with self.session.get(url, params=params) as response:
|
||||
return response.status, await response.json()
|
||||
|
||||
@staticmethod
|
||||
def get_quality(quality: int):
|
||||
quality_map = (5, 6, 7, 27)
|
||||
return quality_map[quality - 1]
|
||||
|
|
@ -0,0 +1,301 @@
|
|||
import asyncio
|
||||
import itertools
|
||||
import logging
|
||||
import random
|
||||
import re
|
||||
|
||||
from ..config import Config
|
||||
from ..exceptions import NonStreamableError
|
||||
from .client import Client
|
||||
from .downloadable import SoundcloudDownloadable
|
||||
|
||||
# e.g. 123456-293847-121314-209849
|
||||
USER_ID = "-".join(str(random.randint(111111, 999999)) for _ in range(4))
|
||||
BASE = "https://api-v2.soundcloud.com"
|
||||
STOCK_URL = "https://soundcloud.com/"
|
||||
|
||||
# for playlists
|
||||
MAX_BATCH_SIZE = 50
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
|
||||
class SoundcloudClient(Client):
|
||||
source = "soundcloud"
|
||||
logged_in = False
|
||||
|
||||
NON_STREAMABLE = "_non_streamable"
|
||||
ORIGINAL_DOWNLOAD = "_original_download"
|
||||
NOT_RESOLVED = "_not_resolved"
|
||||
|
||||
def __init__(self, config: Config):
|
||||
self.global_config = config
|
||||
self.config = config.session.soundcloud
|
||||
self.rate_limiter = self.get_rate_limiter(
|
||||
config.session.downloads.requests_per_minute,
|
||||
)
|
||||
|
||||
async def login(self):
|
||||
self.session = await self.get_session()
|
||||
client_id, app_version = self.config.client_id, self.config.app_version
|
||||
if not client_id or not app_version or not (await self._announce_success()):
|
||||
client_id, app_version = await self._refresh_tokens()
|
||||
# update file and session configs and save to disk
|
||||
cf = self.global_config.file.soundcloud
|
||||
cs = self.global_config.session.soundcloud
|
||||
cs.client_id = client_id
|
||||
cs.app_version = app_version
|
||||
cf.client_id = client_id
|
||||
cf.app_version = app_version
|
||||
self.global_config.file.set_modified()
|
||||
|
||||
logger.debug(f"Current valid {client_id=} {app_version=}")
|
||||
self.logged_in = True
|
||||
|
||||
async def get_metadata(self, item_id: str, media_type: str) -> dict:
|
||||
"""Fetch metadata for an item in Soundcloud API.
|
||||
|
||||
Args:
|
||||
|
||||
item_id (str): Plain soundcloud item ID (e.g 1633786176)
|
||||
media_type (str): track or playlist
|
||||
|
||||
Returns:
|
||||
|
||||
API response. The item IDs for the tracks in the playlist are modified to
|
||||
include resolution status.
|
||||
"""
|
||||
if media_type == "track":
|
||||
# parse custom id that we injected
|
||||
_item_id, _ = item_id.split("|")
|
||||
return await self._get_track(_item_id)
|
||||
elif media_type == "playlist":
|
||||
return await self._get_playlist(item_id)
|
||||
else:
|
||||
raise Exception(f"{media_type} not supported")
|
||||
|
||||
async def search(
|
||||
self,
|
||||
media_type: str,
|
||||
query: str,
|
||||
limit: int = 50,
|
||||
offset: int = 0,
|
||||
) -> list[dict]:
|
||||
# TODO: implement pagination
|
||||
assert media_type in ("track", "playlist"), f"Cannot search for {media_type}"
|
||||
params = {
|
||||
"q": query,
|
||||
"facet": "genre",
|
||||
"user_id": USER_ID,
|
||||
"limit": limit,
|
||||
"offset": offset,
|
||||
"linked_partitioning": "1",
|
||||
}
|
||||
resp, status = await self._api_request(f"search/{media_type}s", params=params)
|
||||
assert status == 200
|
||||
if media_type == "track":
|
||||
for item in resp["collection"]:
|
||||
item["id"] = self._get_custom_id(item)
|
||||
return [resp]
|
||||
|
||||
async def get_downloadable(self, item_info: str, _) -> SoundcloudDownloadable:
|
||||
# We have `get_metadata` overwrite the "id" field so that it contains
|
||||
# some extra information we need to download soundcloud tracks
|
||||
|
||||
# item_id is the soundcloud ID of the track
|
||||
# download_url is either the url that points to an mp3 download or ""
|
||||
# if download_url == '_non_streamable' then we raise an exception
|
||||
|
||||
infos: list[str] = item_info.split("|")
|
||||
logger.debug(f"{infos=}")
|
||||
assert len(infos) == 2, infos
|
||||
item_id, download_info = infos
|
||||
assert re.match(r"\d+", item_id) is not None
|
||||
|
||||
if download_info == self.NON_STREAMABLE:
|
||||
raise NonStreamableError(item_info)
|
||||
|
||||
if download_info == self.ORIGINAL_DOWNLOAD:
|
||||
resp_json, status = await self._api_request(f"tracks/{item_id}/download")
|
||||
assert status == 200
|
||||
return SoundcloudDownloadable(
|
||||
self.session,
|
||||
{"url": resp_json["redirectUri"], "type": "original"},
|
||||
)
|
||||
|
||||
if download_info == self.NOT_RESOLVED:
|
||||
raise NotImplementedError(item_info)
|
||||
|
||||
# download_info contains mp3 stream url
|
||||
resp_json, status = await self._request(download_info)
|
||||
return SoundcloudDownloadable(
|
||||
self.session,
|
||||
{"url": resp_json["url"], "type": "mp3"},
|
||||
)
|
||||
|
||||
async def resolve_url(self, url: str) -> dict:
|
||||
"""Get metadata of the item pointed to by a soundcloud url.
|
||||
|
||||
This is necessary only for soundcloud because they don't store
|
||||
the item IDs in their url. See SoundcloudURL.into_pending for example
|
||||
usage.
|
||||
|
||||
Args:
|
||||
url (str): Url to resolve.
|
||||
|
||||
Returns:
|
||||
API response for item.
|
||||
"""
|
||||
resp, status = await self._api_request("resolve", params={"url": url})
|
||||
assert status == 200
|
||||
if resp["kind"] == "track":
|
||||
resp["id"] = self._get_custom_id(resp)
|
||||
|
||||
return resp
|
||||
|
||||
async def _get_track(self, item_id: str):
|
||||
resp, status = await self._api_request(f"tracks/{item_id}")
|
||||
assert status == 200
|
||||
return resp
|
||||
|
||||
async def _get_playlist(self, item_id: str):
|
||||
original_resp, status = await self._api_request(f"playlists/{item_id}")
|
||||
assert status == 200
|
||||
|
||||
unresolved_tracks = [
|
||||
track["id"] for track in original_resp["tracks"] if "media" not in track
|
||||
]
|
||||
|
||||
if len(unresolved_tracks) == 0:
|
||||
return original_resp
|
||||
|
||||
batches = batched(unresolved_tracks, MAX_BATCH_SIZE)
|
||||
requests = [
|
||||
self._api_request(
|
||||
"tracks",
|
||||
params={"ids": ",".join(str(id) for id in filter_none(batch))},
|
||||
)
|
||||
for batch in batches
|
||||
]
|
||||
|
||||
# (list of track metadata, status code)
|
||||
responses: list[tuple[list, int]] = await asyncio.gather(*requests)
|
||||
|
||||
assert all(status == 200 for _, status in responses)
|
||||
|
||||
remaining_tracks = list(itertools.chain(*[resp for resp, _ in responses]))
|
||||
|
||||
# Insert the new metadata into the original response
|
||||
track_map: dict[str, dict] = {track["id"]: track for track in remaining_tracks}
|
||||
for i, track in enumerate(original_resp["tracks"]):
|
||||
if "media" in track: # track already has metadata
|
||||
continue
|
||||
this_track = track_map.get(track["id"])
|
||||
if this_track is None:
|
||||
raise Exception(f"Requested {track['id']} but got no response")
|
||||
original_resp["tracks"][i] = this_track
|
||||
|
||||
# Overwrite all ids in playlist
|
||||
for track in original_resp["tracks"]:
|
||||
track["id"] = self._get_custom_id(track)
|
||||
|
||||
return original_resp
|
||||
|
||||
@classmethod
|
||||
def _get_custom_id(cls, resp: dict) -> str:
|
||||
item_id = resp["id"]
|
||||
assert "media" in resp, f"track {resp} should be resolved"
|
||||
|
||||
if not resp["streamable"] or resp["policy"] == "BLOCK":
|
||||
return f"{item_id}|{cls.NON_STREAMABLE}"
|
||||
|
||||
if resp["downloadable"] and resp["has_downloads_left"]:
|
||||
return f"{item_id}|{cls.ORIGINAL_DOWNLOAD}"
|
||||
|
||||
url = None
|
||||
for tc in resp["media"]["transcodings"]:
|
||||
fmt = tc["format"]
|
||||
if fmt["protocol"] == "hls" and fmt["mime_type"] == "audio/mpeg":
|
||||
url = tc["url"]
|
||||
break
|
||||
|
||||
assert url is not None
|
||||
return f"{item_id}|{url}"
|
||||
|
||||
async def _api_request(self, path, params=None, headers=None):
|
||||
url = f"{BASE}/{path}"
|
||||
return await self._request(url, params=params, headers=headers)
|
||||
|
||||
async def _request(self, url, params=None, headers=None) -> tuple[dict, int]:
|
||||
c = self.config
|
||||
_params = {
|
||||
"client_id": c.client_id,
|
||||
"app_version": c.app_version,
|
||||
"app_locale": "en",
|
||||
}
|
||||
if params is not None:
|
||||
_params.update(params)
|
||||
|
||||
logger.debug(f"Requesting {url} with {_params=}, {headers=}")
|
||||
async with self.session.get(url, params=_params, headers=headers) as resp:
|
||||
return await resp.json(), resp.status
|
||||
|
||||
async def _request_body(self, url, params=None, headers=None):
|
||||
c = self.config
|
||||
_params = {
|
||||
"client_id": c.client_id,
|
||||
"app_version": c.app_version,
|
||||
"app_locale": "en",
|
||||
}
|
||||
if params is not None:
|
||||
_params.update(params)
|
||||
|
||||
async with self.session.get(url, params=_params, headers=headers) as resp:
|
||||
return await resp.content.read(), resp.status
|
||||
|
||||
async def _announce_success(self):
|
||||
url = f"{BASE}/announcements"
|
||||
_, status = await self._request_body(url)
|
||||
return status == 200
|
||||
|
||||
async def _refresh_tokens(self) -> tuple[str, str]:
|
||||
"""Return a valid client_id, app_version pair."""
|
||||
async with self.session.get(STOCK_URL) as resp:
|
||||
page_text = await resp.text(encoding="utf-8")
|
||||
|
||||
*_, client_id_url_match = re.finditer(
|
||||
r"<script\s+crossorigin\s+src=\"([^\"]+)\"",
|
||||
page_text,
|
||||
)
|
||||
|
||||
if client_id_url_match is None:
|
||||
raise Exception("Could not find client ID in %s" % STOCK_URL)
|
||||
|
||||
client_id_url = client_id_url_match.group(1)
|
||||
|
||||
app_version_match = re.search(
|
||||
r'<script>window\.__sc_version="(\d+)"</script>',
|
||||
page_text,
|
||||
)
|
||||
if app_version_match is None:
|
||||
raise Exception("Could not find app version in %s" % client_id_url_match)
|
||||
app_version = app_version_match.group(1)
|
||||
|
||||
async with self.session.get(client_id_url) as resp:
|
||||
page_text2 = await resp.text(encoding="utf-8")
|
||||
|
||||
client_id_match = re.search(r'client_id:\s*"(\w+)"', page_text2)
|
||||
assert client_id_match is not None
|
||||
client_id = client_id_match.group(1)
|
||||
|
||||
logger.debug(f"Refreshed soundcloud tokens as {client_id=} {app_version=}")
|
||||
return client_id, app_version
|
||||
|
||||
|
||||
def batched(iterable, n, fillvalue=None):
|
||||
args = [iter(iterable)] * n
|
||||
return list(itertools.zip_longest(*args, fillvalue=fillvalue))
|
||||
|
||||
|
||||
def filter_none(iterable):
|
||||
return (x for x in iterable if x is not None)
|
||||
|
|
@ -0,0 +1,329 @@
|
|||
import asyncio
|
||||
import base64
|
||||
import json
|
||||
import logging
|
||||
import re
|
||||
import time
|
||||
|
||||
import aiohttp
|
||||
|
||||
from ..config import Config
|
||||
from ..exceptions import NonStreamableError
|
||||
from .client import Client
|
||||
from .downloadable import TidalDownloadable
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
BASE = "https://api.tidalhifi.com/v1"
|
||||
AUTH_URL = "https://auth.tidal.com/v1/oauth2"
|
||||
|
||||
CLIENT_ID = base64.b64decode("elU0WEhWVmtjMnREUG80dA==").decode("iso-8859-1")
|
||||
CLIENT_SECRET = base64.b64decode(
|
||||
"VkpLaERGcUpQcXZzUFZOQlY2dWtYVEptd2x2YnR0UDd3bE1scmM3MnNlND0=",
|
||||
).decode("iso-8859-1")
|
||||
AUTH = aiohttp.BasicAuth(login=CLIENT_ID, password=CLIENT_SECRET)
|
||||
STREAM_URL_REGEX = re.compile(
|
||||
r"#EXT-X-STREAM-INF:BANDWIDTH=\d+,AVERAGE-BANDWIDTH=\d+,CODECS=\"(?!jpeg)[^\"]+\",RESOLUTION=\d+x\d+\n(.+)"
|
||||
)
|
||||
|
||||
QUALITY_MAP = {
|
||||
0: "LOW", # AAC
|
||||
1: "HIGH", # AAC
|
||||
2: "LOSSLESS", # CD Quality
|
||||
3: "HI_RES", # MQA
|
||||
}
|
||||
|
||||
|
||||
class TidalClient(Client):
|
||||
"""TidalClient."""
|
||||
|
||||
source = "tidal"
|
||||
max_quality = 3
|
||||
|
||||
def __init__(self, config: Config):
|
||||
self.logged_in = False
|
||||
self.global_config = config
|
||||
self.config = config.session.tidal
|
||||
self.rate_limiter = self.get_rate_limiter(
|
||||
config.session.downloads.requests_per_minute,
|
||||
)
|
||||
|
||||
async def login(self):
|
||||
self.session = await self.get_session()
|
||||
c = self.config
|
||||
if not c.access_token:
|
||||
raise Exception("Access token not found in config.")
|
||||
|
||||
self.token_expiry = float(c.token_expiry)
|
||||
self.refresh_token = c.refresh_token
|
||||
|
||||
if self.token_expiry - time.time() < 86400: # 1 day
|
||||
await self._refresh_access_token()
|
||||
else:
|
||||
await self._login_by_access_token(c.access_token, c.user_id)
|
||||
|
||||
self.logged_in = True
|
||||
|
||||
async def get_metadata(self, item_id: str, media_type: str) -> dict:
|
||||
"""Send a request to the api for information.
|
||||
|
||||
:param item_id:
|
||||
:type item_id: str
|
||||
:param media_type: track, album, playlist, or video.
|
||||
:type media_type: str
|
||||
:rtype: dict
|
||||
"""
|
||||
assert media_type in ("track", "playlist", "album", "artist"), media_type
|
||||
|
||||
url = f"{media_type}s/{item_id}"
|
||||
item = await self._api_request(url)
|
||||
if media_type in ("playlist", "album"):
|
||||
# TODO: move into new method and make concurrent
|
||||
resp = await self._api_request(f"{url}/items")
|
||||
tracks_left = item["numberOfTracks"]
|
||||
if tracks_left > 100:
|
||||
offset = 0
|
||||
while tracks_left > 0:
|
||||
offset += 100
|
||||
tracks_left -= 100
|
||||
items_resp = await self._api_request(
|
||||
f"{url}/items", {"offset": offset}
|
||||
)
|
||||
resp["items"].extend(items_resp["items"])
|
||||
|
||||
item["tracks"] = [item["item"] for item in resp["items"]]
|
||||
elif media_type == "artist":
|
||||
logger.debug("filtering eps")
|
||||
album_resp, ep_resp = await asyncio.gather(
|
||||
self._api_request(f"{url}/albums"),
|
||||
self._api_request(f"{url}/albums", params={"filter": "EPSANDSINGLES"}),
|
||||
)
|
||||
|
||||
item["albums"] = album_resp["items"]
|
||||
item["albums"].extend(ep_resp["items"])
|
||||
|
||||
logger.debug(item)
|
||||
return item
|
||||
|
||||
async def search(self, media_type: str, query: str, limit: int = 100) -> list[dict]:
|
||||
"""Search for a query.
|
||||
|
||||
:param query:
|
||||
:type query: str
|
||||
:param media_type: track, album, playlist, or video.
|
||||
:type media_type: str
|
||||
:param limit: max is 100
|
||||
:type limit: int
|
||||
:rtype: dict
|
||||
"""
|
||||
params = {
|
||||
"query": query,
|
||||
"limit": limit,
|
||||
}
|
||||
assert media_type in ("album", "track", "playlist", "video", "artist")
|
||||
resp = await self._api_request(f"search/{media_type}s", params=params)
|
||||
if len(resp["items"]) > 1:
|
||||
return [resp]
|
||||
return []
|
||||
|
||||
async def get_downloadable(self, track_id: str, quality: int):
|
||||
params = {
|
||||
"audioquality": QUALITY_MAP[quality],
|
||||
"playbackmode": "STREAM",
|
||||
"assetpresentation": "FULL",
|
||||
}
|
||||
resp = await self._api_request(
|
||||
f"tracks/{track_id}/playbackinfopostpaywall", params
|
||||
)
|
||||
logger.debug(resp)
|
||||
try:
|
||||
manifest = json.loads(base64.b64decode(resp["manifest"]).decode("utf-8"))
|
||||
except KeyError:
|
||||
raise Exception(resp["userMessage"])
|
||||
|
||||
logger.debug(manifest)
|
||||
enc_key = manifest.get("keyId")
|
||||
if manifest.get("encryptionType") == "NONE":
|
||||
enc_key = None
|
||||
return TidalDownloadable(
|
||||
self.session,
|
||||
url=manifest["urls"][0],
|
||||
codec=manifest["codecs"],
|
||||
encryption_key=enc_key,
|
||||
restrictions=manifest.get("restrictions"),
|
||||
)
|
||||
|
||||
async def get_video_file_url(self, video_id: str) -> str:
|
||||
"""Get the HLS video stream url.
|
||||
|
||||
The stream is downloaded using ffmpeg for now.
|
||||
|
||||
:param video_id:
|
||||
:type video_id: str
|
||||
:rtype: str
|
||||
"""
|
||||
params = {
|
||||
"videoquality": "HIGH",
|
||||
"playbackmode": "STREAM",
|
||||
"assetpresentation": "FULL",
|
||||
}
|
||||
resp = await self._api_request(
|
||||
f"videos/{video_id}/playbackinfopostpaywall", params=params
|
||||
)
|
||||
manifest = json.loads(base64.b64decode(resp["manifest"]).decode("utf-8"))
|
||||
async with self.session.get(manifest["urls"][0]) as resp:
|
||||
available_urls = await resp.json()
|
||||
available_urls.encoding = "utf-8"
|
||||
|
||||
# Highest resolution is last
|
||||
*_, last_match = STREAM_URL_REGEX.finditer(available_urls.text)
|
||||
|
||||
return last_match.group(1)
|
||||
|
||||
# ---------- Login Utilities ---------------
|
||||
|
||||
async def _login_by_access_token(self, token: str, user_id: str):
|
||||
"""Login using the access token.
|
||||
|
||||
Used after the initial authorization.
|
||||
|
||||
:param token: access token
|
||||
:param user_id: To verify that the user is correct
|
||||
"""
|
||||
headers = {"authorization": f"Bearer {token}"} # temporary
|
||||
async with self.session.get(
|
||||
"https://api.tidal.com/v1/sessions",
|
||||
headers=headers,
|
||||
) as _resp:
|
||||
resp = await _resp.json()
|
||||
|
||||
if resp.get("status", 200) != 200:
|
||||
raise Exception(f"Login failed {resp}")
|
||||
|
||||
if str(resp.get("userId")) != str(user_id):
|
||||
raise Exception(f"User id mismatch {resp['userId']} v {user_id}")
|
||||
|
||||
c = self.config
|
||||
c.user_id = resp["userId"]
|
||||
c.country_code = resp["countryCode"]
|
||||
c.access_token = token
|
||||
self._update_authorization_from_config()
|
||||
|
||||
async def _get_login_link(self) -> str:
|
||||
data = {
|
||||
"client_id": CLIENT_ID,
|
||||
"scope": "r_usr+w_usr+w_sub",
|
||||
}
|
||||
resp = await self._api_post(f"{AUTH_URL}/device_authorization", data)
|
||||
|
||||
if resp.get("status", 200) != 200:
|
||||
raise Exception(f"Device authorization failed {resp}")
|
||||
|
||||
device_code = resp["deviceCode"]
|
||||
return f"https://{device_code}"
|
||||
|
||||
def _update_authorization_from_config(self):
|
||||
self.session.headers.update(
|
||||
{"authorization": f"Bearer {self.config.access_token}"},
|
||||
)
|
||||
|
||||
async def _get_auth_status(self, device_code) -> tuple[int, dict[str, int | str]]:
|
||||
"""Check if the user has logged in inside the browser.
|
||||
|
||||
returns (status, authentication info)
|
||||
"""
|
||||
data = {
|
||||
"client_id": CLIENT_ID,
|
||||
"device_code": device_code,
|
||||
"grant_type": "urn:ietf:params:oauth:grant-type:device_code",
|
||||
"scope": "r_usr+w_usr+w_sub",
|
||||
}
|
||||
logger.debug("Checking with %s", data)
|
||||
resp = await self._api_post(f"{AUTH_URL}/token", data, AUTH)
|
||||
|
||||
if "status" in resp and resp["status"] != 200:
|
||||
if resp["status"] == 400 and resp["sub_status"] == 1002:
|
||||
return 2, {}
|
||||
else:
|
||||
return 1, {}
|
||||
|
||||
ret = {}
|
||||
ret["user_id"] = resp["user"]["userId"]
|
||||
ret["country_code"] = resp["user"]["countryCode"]
|
||||
ret["access_token"] = resp["access_token"]
|
||||
ret["refresh_token"] = resp["refresh_token"]
|
||||
ret["token_expiry"] = resp["expires_in"] + time.time()
|
||||
return 0, ret
|
||||
|
||||
async def _refresh_access_token(self):
|
||||
"""Refresh the access token given a refresh token.
|
||||
|
||||
The access token expires in a week, so it must be refreshed.
|
||||
Requires a refresh token.
|
||||
"""
|
||||
data = {
|
||||
"client_id": CLIENT_ID,
|
||||
"refresh_token": self.refresh_token,
|
||||
"grant_type": "refresh_token",
|
||||
"scope": "r_usr+w_usr+w_sub",
|
||||
}
|
||||
resp = await self._api_post(f"{AUTH_URL}/token", data, AUTH)
|
||||
|
||||
if resp.get("status", 200) != 200:
|
||||
raise Exception("Refresh failed")
|
||||
|
||||
c = self.config
|
||||
c.access_token = resp["access_token"]
|
||||
c.token_expiry = resp["expires_in"] + time.time()
|
||||
self._update_authorization_from_config()
|
||||
|
||||
async def _get_device_code(self) -> tuple[str, str]:
|
||||
"""Get the device code that will be used to log in on the browser."""
|
||||
if not hasattr(self, "session"):
|
||||
self.session = await self.get_session()
|
||||
|
||||
data = {
|
||||
"client_id": CLIENT_ID,
|
||||
"scope": "r_usr+w_usr+w_sub",
|
||||
}
|
||||
resp = await self._api_post(f"{AUTH_URL}/device_authorization", data)
|
||||
|
||||
if resp.get("status", 200) != 200:
|
||||
raise Exception(f"Device authorization failed {resp}")
|
||||
|
||||
return resp["deviceCode"], resp["verificationUriComplete"]
|
||||
|
||||
# ---------- API Request Utilities ---------------
|
||||
|
||||
async def _api_post(self, url, data, auth: aiohttp.BasicAuth | None = None) -> dict:
|
||||
"""Post to the Tidal API. Status not checked!
|
||||
|
||||
:param url:
|
||||
:param data:
|
||||
:param auth:
|
||||
"""
|
||||
async with self.rate_limiter:
|
||||
async with self.session.post(url, data=data, auth=auth) as resp:
|
||||
return await resp.json()
|
||||
|
||||
async def _api_request(self, path: str, params=None) -> dict:
|
||||
"""Handle Tidal API requests.
|
||||
|
||||
:param path:
|
||||
:type path: str
|
||||
:param params:
|
||||
:rtype: dict
|
||||
"""
|
||||
if params is None:
|
||||
params = {}
|
||||
|
||||
params["countryCode"] = self.config.country_code
|
||||
params["limit"] = 100
|
||||
|
||||
async with self.rate_limiter:
|
||||
async with self.session.get(f"{BASE}/{path}", params=params) as resp:
|
||||
if resp.status == 404:
|
||||
logger.warning("TIDAL: track not found", resp)
|
||||
raise NonStreamableError("TIDAL: Track not found")
|
||||
resp.raise_for_status()
|
||||
return await resp.json()
|
||||
1261
streamrip/clients.py
|
|
@ -0,0 +1,473 @@
|
|||
"""Classes and functions that manage config state."""
|
||||
|
||||
import copy
|
||||
import functools
|
||||
import logging
|
||||
import os
|
||||
import shutil
|
||||
from dataclasses import dataclass, fields
|
||||
from pathlib import Path
|
||||
|
||||
import click
|
||||
from tomlkit.api import dumps, parse
|
||||
from tomlkit.toml_document import TOMLDocument
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
APP_DIR = click.get_app_dir("streamrip")
|
||||
os.makedirs(APP_DIR, exist_ok=True)
|
||||
DEFAULT_CONFIG_PATH = os.path.join(APP_DIR, "config.toml")
|
||||
CURRENT_CONFIG_VERSION = "2.0.6"
|
||||
|
||||
|
||||
class OutdatedConfigError(Exception):
|
||||
pass
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class QobuzConfig:
|
||||
use_auth_token: bool
|
||||
email_or_userid: str
|
||||
# This is an md5 hash of the plaintext password
|
||||
password_or_token: str
|
||||
# Do not change
|
||||
app_id: str
|
||||
quality: int
|
||||
# This will download booklet pdfs that are included with some albums
|
||||
download_booklets: bool
|
||||
# Do not change
|
||||
secrets: list[str]
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class TidalConfig:
|
||||
# Do not change any of the fields below
|
||||
user_id: str
|
||||
country_code: str
|
||||
access_token: str
|
||||
refresh_token: str
|
||||
# Tokens last 1 week after refresh. This is the Unix timestamp of the expiration
|
||||
# time. If you haven't used streamrip in more than a week, you may have to log
|
||||
# in again using `rip config --tidal`
|
||||
token_expiry: str
|
||||
# 0: 256kbps AAC, 1: 320kbps AAC, 2: 16/44.1 "HiFi" FLAC, 3: 24/44.1 "MQA" FLAC
|
||||
quality: int
|
||||
# This will download videos included in Video Albums.
|
||||
download_videos: bool
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class DeezerConfig:
|
||||
# An authentication cookie that allows streamrip to use your Deezer account
|
||||
# See https://github.com/nathom/streamrip/wiki/Finding-Your-Deezer-ARL-Cookie
|
||||
# for instructions on how to find this
|
||||
arl: str
|
||||
# 0, 1, or 2
|
||||
# This only applies to paid Deezer subscriptions. Those using deezloader
|
||||
# are automatically limited to quality = 1
|
||||
quality: int
|
||||
# This allows for free 320kbps MP3 downloads from Deezer
|
||||
# If an arl is provided, deezloader is never used
|
||||
use_deezloader: bool
|
||||
# This warns you when the paid deezer account is not logged in and rip falls
|
||||
# back to deezloader, which is unreliable
|
||||
deezloader_warnings: bool
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class SoundcloudConfig:
|
||||
# This changes periodically, so it needs to be updated
|
||||
client_id: str
|
||||
app_version: str
|
||||
# Only 0 is available for now
|
||||
quality: int
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class YoutubeConfig:
|
||||
# The path to download the videos to
|
||||
video_downloads_folder: str
|
||||
# Only 0 is available for now
|
||||
quality: int
|
||||
# Download the video along with the audio
|
||||
download_videos: bool
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class DatabaseConfig:
|
||||
downloads_enabled: bool
|
||||
downloads_path: str
|
||||
failed_downloads_enabled: bool
|
||||
failed_downloads_path: str
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class ConversionConfig:
|
||||
enabled: bool
|
||||
# FLAC, ALAC, OPUS, MP3, VORBIS, or AAC
|
||||
codec: str
|
||||
# In Hz. Tracks are downsampled if their sampling rate is greater than this.
|
||||
# Value of 48000 is recommended to maximize quality and minimize space
|
||||
sampling_rate: int
|
||||
# Only 16 and 24 are available. It is only applied when the bit depth is higher
|
||||
# than this value.
|
||||
bit_depth: int
|
||||
# Only applicable for lossy codecs
|
||||
lossy_bitrate: int
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class QobuzDiscographyFilterConfig:
|
||||
# Remove Collectors Editions, live recordings, etc.
|
||||
extras: bool
|
||||
# Picks the highest quality out of albums with identical titles.
|
||||
repeats: bool
|
||||
# Remove EPs and Singles
|
||||
non_albums: bool
|
||||
# Remove albums whose artist is not the one requested
|
||||
features: bool
|
||||
# Skip non studio albums
|
||||
non_studio_albums: bool
|
||||
# Only download remastered albums
|
||||
non_remaster: bool
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class ArtworkConfig:
|
||||
# Write the image to the audio file
|
||||
embed: bool
|
||||
# The size of the artwork to embed. Options: thumbnail, small, large, original.
|
||||
# "original" images can be up to 30MB, and may fail embedding.
|
||||
# Using "large" is recommended.
|
||||
embed_size: str
|
||||
# Both of these options limit the size of the embedded artwork. If their values
|
||||
# are larger than the actual dimensions of the image, they will be ignored.
|
||||
# If either value is -1, the image is left untouched.
|
||||
embed_max_width: int
|
||||
# Save the cover image at the highest quality as a seperate jpg file
|
||||
save_artwork: bool
|
||||
# If artwork is saved, downscale it to these dimensions, or ignore if -1
|
||||
saved_max_width: int
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class MetadataConfig:
|
||||
# Sets the value of the 'ALBUM' field in the metadata to the playlist's name.
|
||||
# This is useful if your music library software organizes tracks based on album name.
|
||||
set_playlist_to_album: bool
|
||||
# If part of a playlist, sets the `tracknumber` field in the metadata to the track's
|
||||
# position in the playlist instead of its position in its album
|
||||
renumber_playlist_tracks: bool
|
||||
# The following metadata tags won't be applied
|
||||
# See https://github.com/nathom/streamrip/wiki/Metadata-Tag-Names for more info
|
||||
exclude: list[str]
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class FilepathsConfig:
|
||||
# Create folders for single tracks within the downloads directory using the folder_format
|
||||
# template
|
||||
add_singles_to_folder: bool
|
||||
# Available keys: "albumartist", "title", "year", "bit_depth", "sampling_rate",
|
||||
# "container", "id", and "albumcomposer"
|
||||
folder_format: str
|
||||
# Available keys: "tracknumber", "artist", "albumartist", "composer", "title",
|
||||
# and "albumcomposer"
|
||||
track_format: str
|
||||
# Only allow printable ASCII characters in filenames.
|
||||
restrict_characters: bool
|
||||
# Truncate the filename if it is greater than 120 characters
|
||||
# Setting this to false may cause downloads to fail on some systems
|
||||
truncate_to: int
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class DownloadsConfig:
|
||||
# Folder where tracks are downloaded to
|
||||
folder: str
|
||||
# Put Qobuz albums in a 'Qobuz' folder, Tidal albums in 'Tidal' etc.
|
||||
source_subdirectories: bool
|
||||
# Put tracks in an album with 2 or more discs into a subfolder named `Disc N`
|
||||
disc_subdirectories: bool
|
||||
# Download (and convert) tracks all at once, instead of sequentially.
|
||||
# If you are converting the tracks, or have fast internet, this will
|
||||
# substantially improve processing speed.
|
||||
concurrency: bool
|
||||
# The maximum number of tracks to download at once
|
||||
# If you have very fast internet, you will benefit from a higher value,
|
||||
# A value that is too high for your bandwidth may cause slowdowns
|
||||
max_connections: int
|
||||
requests_per_minute: int
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class LastFmConfig:
|
||||
# The source on which to search for the tracks.
|
||||
source: str
|
||||
# If no results were found with the primary source, the item is searched for
|
||||
# on this one.
|
||||
fallback_source: str
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class CliConfig:
|
||||
# Print "Downloading {Album name}" etc. to screen
|
||||
text_output: bool
|
||||
# Show resolve, download progress bars
|
||||
progress_bars: bool
|
||||
# The maximum number of search results to show in the interactive menu
|
||||
max_search_results: int
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class MiscConfig:
|
||||
version: str
|
||||
check_for_updates: bool
|
||||
|
||||
|
||||
HOME = Path.home()
|
||||
DEFAULT_DOWNLOADS_FOLDER = os.path.join(HOME, "StreamripDownloads")
|
||||
DEFAULT_DOWNLOADS_DB_PATH = os.path.join(APP_DIR, "downloads.db")
|
||||
DEFAULT_FAILED_DOWNLOADS_DB_PATH = os.path.join(APP_DIR, "failed_downloads.db")
|
||||
DEFAULT_YOUTUBE_VIDEO_DOWNLOADS_FOLDER = os.path.join(
|
||||
DEFAULT_DOWNLOADS_FOLDER,
|
||||
"YouTubeVideos",
|
||||
)
|
||||
BLANK_CONFIG_PATH = os.path.join(os.path.dirname(__file__), "config.toml")
|
||||
assert os.path.isfile(BLANK_CONFIG_PATH), "Template config not found"
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class ConfigData:
|
||||
toml: TOMLDocument
|
||||
downloads: DownloadsConfig
|
||||
|
||||
qobuz: QobuzConfig
|
||||
tidal: TidalConfig
|
||||
deezer: DeezerConfig
|
||||
soundcloud: SoundcloudConfig
|
||||
youtube: YoutubeConfig
|
||||
lastfm: LastFmConfig
|
||||
|
||||
filepaths: FilepathsConfig
|
||||
artwork: ArtworkConfig
|
||||
metadata: MetadataConfig
|
||||
qobuz_filters: QobuzDiscographyFilterConfig
|
||||
|
||||
cli: CliConfig
|
||||
database: DatabaseConfig
|
||||
conversion: ConversionConfig
|
||||
|
||||
misc: MiscConfig
|
||||
|
||||
_modified: bool = False
|
||||
|
||||
@classmethod
|
||||
def from_toml(cls, toml_str: str):
|
||||
# TODO: handle the mistake where Windows people forget to escape backslash
|
||||
toml = parse(toml_str)
|
||||
if (v := toml["misc"]["version"]) != CURRENT_CONFIG_VERSION: # type: ignore
|
||||
raise OutdatedConfigError(
|
||||
f"Need to update config from {v} to {CURRENT_CONFIG_VERSION}",
|
||||
)
|
||||
|
||||
downloads = DownloadsConfig(**toml["downloads"]) # type: ignore
|
||||
qobuz = QobuzConfig(**toml["qobuz"]) # type: ignore
|
||||
tidal = TidalConfig(**toml["tidal"]) # type: ignore
|
||||
deezer = DeezerConfig(**toml["deezer"]) # type: ignore
|
||||
soundcloud = SoundcloudConfig(**toml["soundcloud"]) # type: ignore
|
||||
youtube = YoutubeConfig(**toml["youtube"]) # type: ignore
|
||||
lastfm = LastFmConfig(**toml["lastfm"]) # type: ignore
|
||||
artwork = ArtworkConfig(**toml["artwork"]) # type: ignore
|
||||
filepaths = FilepathsConfig(**toml["filepaths"]) # type: ignore
|
||||
metadata = MetadataConfig(**toml["metadata"]) # type: ignore
|
||||
qobuz_filters = QobuzDiscographyFilterConfig(**toml["qobuz_filters"]) # type: ignore
|
||||
cli = CliConfig(**toml["cli"]) # type: ignore
|
||||
database = DatabaseConfig(**toml["database"]) # type: ignore
|
||||
conversion = ConversionConfig(**toml["conversion"]) # type: ignore
|
||||
misc = MiscConfig(**toml["misc"]) # type: ignore
|
||||
|
||||
return cls(
|
||||
toml=toml,
|
||||
downloads=downloads,
|
||||
qobuz=qobuz,
|
||||
tidal=tidal,
|
||||
deezer=deezer,
|
||||
soundcloud=soundcloud,
|
||||
youtube=youtube,
|
||||
lastfm=lastfm,
|
||||
artwork=artwork,
|
||||
filepaths=filepaths,
|
||||
metadata=metadata,
|
||||
qobuz_filters=qobuz_filters,
|
||||
cli=cli,
|
||||
database=database,
|
||||
conversion=conversion,
|
||||
misc=misc,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def defaults(cls):
|
||||
with open(BLANK_CONFIG_PATH) as f:
|
||||
return cls.from_toml(f.read())
|
||||
|
||||
def set_modified(self):
|
||||
self._modified = True
|
||||
|
||||
@property
|
||||
def modified(self):
|
||||
return self._modified
|
||||
|
||||
def update_toml(self):
|
||||
update_toml_section_from_config(self.toml["downloads"], self.downloads)
|
||||
update_toml_section_from_config(self.toml["qobuz"], self.qobuz)
|
||||
update_toml_section_from_config(self.toml["tidal"], self.tidal)
|
||||
update_toml_section_from_config(self.toml["deezer"], self.deezer)
|
||||
update_toml_section_from_config(self.toml["soundcloud"], self.soundcloud)
|
||||
update_toml_section_from_config(self.toml["youtube"], self.youtube)
|
||||
update_toml_section_from_config(self.toml["lastfm"], self.lastfm)
|
||||
update_toml_section_from_config(self.toml["artwork"], self.artwork)
|
||||
update_toml_section_from_config(self.toml["filepaths"], self.filepaths)
|
||||
update_toml_section_from_config(self.toml["metadata"], self.metadata)
|
||||
update_toml_section_from_config(self.toml["qobuz_filters"], self.qobuz_filters)
|
||||
update_toml_section_from_config(self.toml["cli"], self.cli)
|
||||
update_toml_section_from_config(self.toml["database"], self.database)
|
||||
update_toml_section_from_config(self.toml["conversion"], self.conversion)
|
||||
|
||||
def get_source(
|
||||
self,
|
||||
source: str,
|
||||
) -> QobuzConfig | DeezerConfig | SoundcloudConfig | TidalConfig:
|
||||
d = {
|
||||
"qobuz": self.qobuz,
|
||||
"deezer": self.deezer,
|
||||
"soundcloud": self.soundcloud,
|
||||
"tidal": self.tidal,
|
||||
}
|
||||
res = d.get(source)
|
||||
if res is None:
|
||||
raise Exception(f"Invalid source {source}")
|
||||
return res
|
||||
|
||||
|
||||
def update_toml_section_from_config(toml_section, config):
|
||||
for field in fields(config):
|
||||
toml_section[field.name] = getattr(config, field.name)
|
||||
|
||||
|
||||
class Config:
|
||||
def __init__(self, path: str, /):
|
||||
self.path = path
|
||||
|
||||
with open(path) as toml_file:
|
||||
self.file: ConfigData = ConfigData.from_toml(toml_file.read())
|
||||
|
||||
self.session: ConfigData = copy.deepcopy(self.file)
|
||||
|
||||
def save_file(self):
|
||||
if not self.file.modified:
|
||||
return
|
||||
|
||||
with open(self.path, "w") as toml_file:
|
||||
self.file.update_toml()
|
||||
toml_file.write(dumps(self.file.toml))
|
||||
|
||||
@staticmethod
|
||||
def _update_file(old_path: str, new_path: str):
|
||||
"""Updates the current config based on a newer config `new_toml`."""
|
||||
with open(new_path) as new_conf:
|
||||
new_toml = parse(new_conf.read())
|
||||
|
||||
toml_set_user_defaults(new_toml)
|
||||
|
||||
with open(old_path) as old_conf:
|
||||
old_toml = parse(old_conf.read())
|
||||
|
||||
update_config(old_toml, new_toml)
|
||||
|
||||
with open(old_path, "w") as f:
|
||||
f.write(dumps(new_toml))
|
||||
|
||||
@classmethod
|
||||
def update_file(cls, path: str):
|
||||
cls._update_file(path, BLANK_CONFIG_PATH)
|
||||
|
||||
@classmethod
|
||||
def defaults(cls):
|
||||
return cls(BLANK_CONFIG_PATH)
|
||||
|
||||
def __enter__(self):
|
||||
return self
|
||||
|
||||
def __exit__(self, *_):
|
||||
self.save_file()
|
||||
|
||||
|
||||
def set_user_defaults(path: str, /):
|
||||
"""Update the TOML file at the path with user-specific default values."""
|
||||
shutil.copy(BLANK_CONFIG_PATH, path)
|
||||
|
||||
with open(path) as f:
|
||||
toml = parse(f.read())
|
||||
|
||||
toml_set_user_defaults(toml)
|
||||
|
||||
with open(path, "w") as f:
|
||||
f.write(dumps(toml))
|
||||
|
||||
|
||||
def toml_set_user_defaults(toml: TOMLDocument):
|
||||
toml["downloads"]["folder"] = DEFAULT_DOWNLOADS_FOLDER # type: ignore
|
||||
toml["database"]["downloads_path"] = DEFAULT_DOWNLOADS_DB_PATH # type: ignore
|
||||
toml["database"]["failed_downloads_path"] = DEFAULT_FAILED_DOWNLOADS_DB_PATH # type: ignore
|
||||
toml["youtube"]["video_downloads_folder"] = DEFAULT_YOUTUBE_VIDEO_DOWNLOADS_FOLDER # type: ignore
|
||||
|
||||
|
||||
def _get_dict_keys_r(d: dict) -> set[tuple]:
|
||||
"""Get all possible key combinations in nested dicts.
|
||||
|
||||
See tests/test_config.py for example.
|
||||
"""
|
||||
keys = d.keys()
|
||||
ret = set()
|
||||
for cur in keys:
|
||||
val = d[cur]
|
||||
if isinstance(val, dict):
|
||||
ret.update((cur, *remaining) for remaining in _get_dict_keys_r(val))
|
||||
else:
|
||||
ret.add((cur,))
|
||||
return ret
|
||||
|
||||
|
||||
def _nested_get(dictionary, *keys, default=None):
|
||||
return functools.reduce(
|
||||
lambda d, key: d.get(key, default) if isinstance(d, dict) else default,
|
||||
keys,
|
||||
dictionary,
|
||||
)
|
||||
|
||||
|
||||
def _nested_set(dictionary, *keys, val):
|
||||
"""Nested set. Throws exception if keys are invalid."""
|
||||
assert len(keys) > 0
|
||||
final = functools.reduce(lambda d, key: d.get(key), keys[:-1], dictionary)
|
||||
final[keys[-1]] = val
|
||||
|
||||
|
||||
def update_config(old_with_data: dict, new_without_data: dict):
|
||||
"""Used to update config when a new config version is detected.
|
||||
|
||||
All data associated with keys that are shared between the old and
|
||||
new configs are copied from old to new. The remaining keep their default value.
|
||||
|
||||
Assumes that new_without_data contains default config values of the
|
||||
latest version.
|
||||
"""
|
||||
old_keys = _get_dict_keys_r(old_with_data)
|
||||
new_keys = _get_dict_keys_r(new_without_data)
|
||||
common = old_keys.intersection(new_keys)
|
||||
common.discard(("misc", "version"))
|
||||
|
||||
for k in common:
|
||||
old_val = _nested_get(old_with_data, *k)
|
||||
_nested_set(new_without_data, *k, val=old_val)
|
||||
|
|
@ -3,16 +3,20 @@
|
|||
folder = ""
|
||||
# Put Qobuz albums in a 'Qobuz' folder, Tidal albums in 'Tidal' etc.
|
||||
source_subdirectories = false
|
||||
|
||||
[downloads.concurrency]
|
||||
# Put tracks in an album with 2 or more discs into a subfolder named `Disc N`
|
||||
disc_subdirectories = true
|
||||
# Download (and convert) tracks all at once, instead of sequentially.
|
||||
# If you are converting the tracks, or have fast internet, this will
|
||||
# substantially improve processing speed.
|
||||
enabled = true
|
||||
concurrency = true
|
||||
# The maximum number of tracks to download at once
|
||||
# If you have very fast internet, you will benefit from a higher value,
|
||||
# A value that is too high for your bandwidth may cause slowdowns
|
||||
max_connections = 3
|
||||
# Set to -1 for no limit
|
||||
max_connections = 6
|
||||
# Max number of API requests per source to handle per minute
|
||||
# Set to -1 for no limit
|
||||
requests_per_minute = 60
|
||||
|
||||
[qobuz]
|
||||
# 1: 320kbps MP3, 2: 16/44.1, 3: 24/<=96, 4: 24/>=96
|
||||
|
|
@ -20,9 +24,12 @@ quality = 3
|
|||
# This will download booklet pdfs that are included with some albums
|
||||
download_booklets = true
|
||||
|
||||
email = ""
|
||||
# This is an md5 hash of the plaintext password
|
||||
password = ""
|
||||
# Authenticate to Qobuz using auth token? Value can be true/false only
|
||||
use_auth_token = false
|
||||
# Enter your userid if the above use_auth_token is set to true, else enter your email
|
||||
email_or_userid = ""
|
||||
# Enter your auth token if the above use_auth_token is set to true, else enter the md5 hash of your plaintext password
|
||||
password_or_token = ""
|
||||
# Do not change
|
||||
app_id = ""
|
||||
# Do not change
|
||||
|
|
@ -75,16 +82,17 @@ download_videos = false
|
|||
# The path to download the videos to
|
||||
video_downloads_folder = ""
|
||||
|
||||
# This stores a list of item IDs so that repeats are not downloaded.
|
||||
[database.downloads]
|
||||
enabled = true
|
||||
path = ""
|
||||
|
||||
[database]
|
||||
# Create a database that contains all the track IDs downloaded so far
|
||||
# Any time a track logged in the database is requested, it is skipped
|
||||
# This can be disabled temporarily with the --no-db flag
|
||||
downloads_enabled = true
|
||||
# Path to the downloads database
|
||||
downloads_path = ""
|
||||
# If a download fails, the item ID is stored here. Then, `rip repair` can be
|
||||
# called to retry the downloads
|
||||
[database.failed_downloads]
|
||||
enabled = true
|
||||
path = ""
|
||||
failed_downloads_enabled = true
|
||||
failed_downloads_path = ""
|
||||
|
||||
# Convert tracks to a codec after downloading them.
|
||||
[conversion]
|
||||
|
|
@ -101,7 +109,8 @@ bit_depth = 24
|
|||
lossy_bitrate = 320
|
||||
|
||||
# Filter a Qobuz artist's discography. Set to 'true' to turn on a filter.
|
||||
[filters]
|
||||
# This will also be applied to other sources, but is not guaranteed to work correctly
|
||||
[qobuz_filters]
|
||||
# Remove Collectors Editions, live recordings, etc.
|
||||
extras = false
|
||||
# Picks the highest quality out of albums with identical titles.
|
||||
|
|
@ -121,21 +130,24 @@ embed = true
|
|||
# The size of the artwork to embed. Options: thumbnail, small, large, original.
|
||||
# "original" images can be up to 30MB, and may fail embedding.
|
||||
# Using "large" is recommended.
|
||||
size = "large"
|
||||
# Both of these options limit the size of the embedded artwork. If their values
|
||||
# are larger than the actual dimensions of the image, they will be ignored.
|
||||
# If either value is -1, the image is left untouched.
|
||||
max_width = -1
|
||||
max_height = -1
|
||||
embed_size = "large"
|
||||
# If this is set to a value > 0, max(width, height) of the embedded art will be set to this value in pixels
|
||||
# Proportions of the image will remain the same
|
||||
embed_max_width = -1
|
||||
# Save the cover image at the highest quality as a seperate jpg file
|
||||
keep_hires_cover = true
|
||||
save_artwork = true
|
||||
# If this is set to a value > 0, max(width, height) of the saved art will be set to this value in pixels
|
||||
# Proportions of the image will remain the same
|
||||
saved_max_width = -1
|
||||
|
||||
|
||||
[metadata]
|
||||
# Sets the value of the 'ALBUM' field in the metadata to the playlist's name.
|
||||
# This is useful if your music library software organizes tracks based on album name.
|
||||
set_playlist_to_album = true
|
||||
# Replaces the original track's tracknumber with it's position in the playlist
|
||||
new_playlist_tracknumbers = true
|
||||
# If part of a playlist, sets the `tracknumber` field in the metadata to the track's
|
||||
# position in the playlist instead of its position in its album
|
||||
renumber_playlist_tracks = true
|
||||
# The following metadata tags won't be applied
|
||||
# See https://github.com/nathom/streamrip/wiki/Metadata-Tag-Names for more info
|
||||
exclude = []
|
||||
|
|
@ -146,14 +158,16 @@ exclude = []
|
|||
# template
|
||||
add_singles_to_folder = false
|
||||
# Available keys: "albumartist", "title", "year", "bit_depth", "sampling_rate",
|
||||
# "container", "id", and "albumcomposer"
|
||||
# "id", and "albumcomposer"
|
||||
folder_format = "{albumartist} - {title} ({year}) [{container}] [{bit_depth}B-{sampling_rate}kHz]"
|
||||
# Available keys: "tracknumber", "artist", "albumartist", "composer", "title",
|
||||
# and "albumcomposer"
|
||||
track_format = "{tracknumber}. {artist} - {title}{explicit}"
|
||||
# and "albumcomposer", "explicit"
|
||||
track_format = "{tracknumber:02}. {artist} - {title}{explicit}"
|
||||
# Only allow printable ASCII characters in filenames.
|
||||
restrict_characters = false
|
||||
|
||||
# Truncate the filename if it is greater than this number of characters
|
||||
# Setting this to false may cause downloads to fail on some systems
|
||||
truncate_to = 120
|
||||
|
||||
# Last.fm playlists are downloaded by searching for the titles of the tracks
|
||||
[lastfm]
|
||||
|
|
@ -161,12 +175,18 @@ restrict_characters = false
|
|||
source = "qobuz"
|
||||
# If no results were found with the primary source, the item is searched for
|
||||
# on this one.
|
||||
fallback_source = "deezer"
|
||||
fallback_source = ""
|
||||
|
||||
[theme]
|
||||
# Options: "dainty" or "plain"
|
||||
progress_bar = "dainty"
|
||||
[cli]
|
||||
# Print "Downloading {Album name}" etc. to screen
|
||||
text_output = true
|
||||
# Show resolve, download progress bars
|
||||
progress_bars = true
|
||||
# The maximum number of search results to show in the interactive menu
|
||||
max_search_results = 100
|
||||
|
||||
[misc]
|
||||
# Metadata to identify this config file. Do not change.
|
||||
version = "1.9.2"
|
||||
version = "2.0.6"
|
||||
# Print a message if a new version of streamrip is available
|
||||
check_for_updates = true
|
||||
|
|
@ -0,0 +1,3 @@
|
|||
from rich.console import Console
|
||||
|
||||
console = Console()
|
||||
|
|
@ -1,193 +0,0 @@
|
|||
"""Constants that are kept in one place."""
|
||||
|
||||
import base64
|
||||
|
||||
import mutagen.id3 as id3
|
||||
|
||||
AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:83.0) Gecko/20100101 Firefox/83.0"
|
||||
|
||||
TIDAL_COVER_URL = "https://resources.tidal.com/images/{uuid}/{width}x{height}.jpg"
|
||||
# Get this from (base64encoded)
|
||||
# aHR0cHM6Ly9hLXYyLnNuZGNkbi5jb20vYXNzZXRzLzItYWIxYjg1NjguanM=
|
||||
# Don't know if this is a static url yet
|
||||
SOUNDCLOUD_CLIENT_ID = "qHsjZaNbdTcABbiIQnVfW07cEPGLNjIh"
|
||||
SOUNDCLOUD_USER_ID = "672320-86895-162383-801513"
|
||||
SOUNDCLOUD_APP_VERSION = "1630917744"
|
||||
|
||||
|
||||
QUALITY_DESC = {
|
||||
0: "128kbps",
|
||||
1: "320kbps",
|
||||
2: "16bit/44.1kHz",
|
||||
3: "24bit/96kHz",
|
||||
4: "24bit/192kHz",
|
||||
}
|
||||
|
||||
QOBUZ_FEATURED_KEYS = (
|
||||
"most-streamed",
|
||||
"recent-releases",
|
||||
"best-sellers",
|
||||
"press-awards",
|
||||
"ideal-discography",
|
||||
"editor-picks",
|
||||
"most-featured",
|
||||
"qobuzissims",
|
||||
"new-releases",
|
||||
"new-releases-full",
|
||||
"harmonia-mundi",
|
||||
"universal-classic",
|
||||
"universal-jazz",
|
||||
"universal-jeunesse",
|
||||
"universal-chanson",
|
||||
)
|
||||
|
||||
__MP4_KEYS = (
|
||||
"\xa9nam",
|
||||
"\xa9ART",
|
||||
"\xa9alb",
|
||||
r"aART",
|
||||
"\xa9day",
|
||||
"\xa9day",
|
||||
"\xa9cmt",
|
||||
"desc",
|
||||
"purd",
|
||||
"\xa9grp",
|
||||
"\xa9gen",
|
||||
"\xa9lyr",
|
||||
"\xa9too",
|
||||
"cprt",
|
||||
"cpil",
|
||||
"covr",
|
||||
"trkn",
|
||||
"disk",
|
||||
None,
|
||||
None,
|
||||
None,
|
||||
)
|
||||
|
||||
__MP3_KEYS = (
|
||||
id3.TIT2,
|
||||
id3.TPE1,
|
||||
id3.TALB,
|
||||
id3.TPE2,
|
||||
id3.TCOM,
|
||||
id3.TYER,
|
||||
id3.COMM,
|
||||
id3.TT1,
|
||||
id3.TT1,
|
||||
id3.GP1,
|
||||
id3.TCON,
|
||||
id3.USLT,
|
||||
id3.TEN,
|
||||
id3.TCOP,
|
||||
id3.TCMP,
|
||||
None,
|
||||
id3.TRCK,
|
||||
id3.TPOS,
|
||||
None,
|
||||
None,
|
||||
None,
|
||||
)
|
||||
|
||||
__METADATA_TYPES = (
|
||||
"title",
|
||||
"artist",
|
||||
"album",
|
||||
"albumartist",
|
||||
"composer",
|
||||
"year",
|
||||
"comment",
|
||||
"description",
|
||||
"purchase_date",
|
||||
"grouping",
|
||||
"genre",
|
||||
"lyrics",
|
||||
"encoder",
|
||||
"copyright",
|
||||
"compilation",
|
||||
"cover",
|
||||
"tracknumber",
|
||||
"discnumber",
|
||||
"tracktotal",
|
||||
"disctotal",
|
||||
"date",
|
||||
)
|
||||
|
||||
|
||||
FLAC_KEY = {v: v.upper() for v in __METADATA_TYPES}
|
||||
MP4_KEY = dict(zip(__METADATA_TYPES, __MP4_KEYS))
|
||||
MP3_KEY = dict(zip(__METADATA_TYPES, __MP3_KEYS))
|
||||
|
||||
COPYRIGHT = "\u2117"
|
||||
PHON_COPYRIGHT = "\u00a9"
|
||||
FLAC_MAX_BLOCKSIZE = 16777215 # 16.7 MB
|
||||
|
||||
# TODO: give these more descriptive names
|
||||
TRACK_KEYS = (
|
||||
"tracknumber",
|
||||
"artist",
|
||||
"albumartist",
|
||||
"composer",
|
||||
"title",
|
||||
"albumcomposer",
|
||||
"explicit",
|
||||
)
|
||||
ALBUM_KEYS = (
|
||||
"albumartist",
|
||||
"title",
|
||||
"year",
|
||||
"bit_depth",
|
||||
"sampling_rate",
|
||||
"container",
|
||||
"albumcomposer",
|
||||
"id",
|
||||
)
|
||||
# TODO: rename these to DEFAULT_FOLDER_FORMAT etc
|
||||
FOLDER_FORMAT = (
|
||||
"{albumartist} - {title} ({year}) [{container}] [{bit_depth}B-{sampling_rate}kHz]"
|
||||
)
|
||||
TRACK_FORMAT = "{tracknumber}. {artist} - {title}"
|
||||
|
||||
|
||||
TIDAL_MAX_Q = 7
|
||||
|
||||
TIDAL_Q_MAP = {
|
||||
"LOW": 0,
|
||||
"HIGH": 1,
|
||||
"LOSSLESS": 2,
|
||||
"HI_RES": 3,
|
||||
}
|
||||
|
||||
DEEZER_MAX_Q = 6
|
||||
DEEZER_FEATURED_KEYS = {"releases", "charts", "selection"}
|
||||
AVAILABLE_QUALITY_IDS = (0, 1, 2, 3, 4)
|
||||
DEEZER_FORMATS = {
|
||||
"AAC_64",
|
||||
"MP3_64",
|
||||
"MP3_128",
|
||||
"MP3_256",
|
||||
"MP3_320",
|
||||
"FLAC",
|
||||
}
|
||||
# video only for tidal
|
||||
MEDIA_TYPES = {"track", "album", "artist", "label", "playlist", "video"}
|
||||
|
||||
# used to homogenize cover size keys
|
||||
COVER_SIZES = ("thumbnail", "small", "large", "original")
|
||||
|
||||
TIDAL_CLIENT_INFO = {
|
||||
"id": base64.b64decode("elU0WEhWVmtjMnREUG80dA==").decode("iso-8859-1"),
|
||||
"secret": base64.b64decode(
|
||||
"VkpLaERGcUpQcXZzUFZOQlY2dWtYVEptd2x2YnR0UDd3bE1scmM3MnNlND0="
|
||||
).decode("iso-8859-1"),
|
||||
}
|
||||
|
||||
QOBUZ_BASE = "https://www.qobuz.com/api.json/0.2"
|
||||
|
||||
TIDAL_BASE = "https://api.tidalhifi.com/v1"
|
||||
TIDAL_AUTH_URL = "https://auth.tidal.com/v1/oauth2"
|
||||
|
||||
DEEZER_BASE = "https://api.deezer.com"
|
||||
DEEZER_DL = "http://dz.loaderapp.info/deezer"
|
||||
|
||||
SOUNDCLOUD_BASE = "https://api-v2.soundcloud.com"
|
||||
|
|
@ -1,11 +1,11 @@
|
|||
"""Wrapper classes over FFMPEG."""
|
||||
|
||||
import asyncio
|
||||
import logging
|
||||
import os
|
||||
import shutil
|
||||
import subprocess
|
||||
from tempfile import gettempdir
|
||||
from typing import Optional
|
||||
from typing import Final, Optional
|
||||
|
||||
from .exceptions import ConversionError
|
||||
|
||||
|
|
@ -48,7 +48,10 @@ class Converter:
|
|||
:param remove_source: Remove the source file after conversion.
|
||||
:type remove_source: bool
|
||||
"""
|
||||
logger.debug(locals())
|
||||
if shutil.which("ffmpeg") is None:
|
||||
raise Exception(
|
||||
"Could not find FFMPEG executable. Install it to convert audio files.",
|
||||
)
|
||||
|
||||
self.filename = filename
|
||||
self.final_fn = f"{os.path.splitext(filename)[0]}.{self.container}"
|
||||
|
|
@ -68,7 +71,7 @@ class Converter:
|
|||
|
||||
logger.debug("FFmpeg codec extra argument: %s", self.ffmpeg_arg)
|
||||
|
||||
def convert(self, custom_fn: Optional[str] = None):
|
||||
async def convert(self, custom_fn: Optional[str] = None):
|
||||
"""Convert the file.
|
||||
|
||||
:param custom_fn: Custom output filename (defaults to the original
|
||||
|
|
@ -81,8 +84,11 @@ class Converter:
|
|||
self.command = self._gen_command()
|
||||
logger.debug("Generated conversion command: %s", self.command)
|
||||
|
||||
process = subprocess.Popen(self.command, stderr=subprocess.PIPE)
|
||||
process.wait()
|
||||
process = await asyncio.create_subprocess_exec(
|
||||
*self.command,
|
||||
stderr=asyncio.subprocess.PIPE,
|
||||
)
|
||||
out, err = await process.communicate()
|
||||
if process.returncode == 0 and os.path.isfile(self.tempfile):
|
||||
if self.remove_source:
|
||||
os.remove(self.filename)
|
||||
|
|
@ -91,7 +97,7 @@ class Converter:
|
|||
shutil.move(self.tempfile, self.final_fn)
|
||||
logger.debug("Moved: %s -> %s", self.tempfile, self.final_fn)
|
||||
else:
|
||||
raise ConversionError(f"FFmpeg output:\n{process.communicate()[1]}")
|
||||
raise ConversionError(f"FFmpeg output:\n{out, err}")
|
||||
|
||||
def _gen_command(self):
|
||||
command = [
|
||||
|
|
@ -115,27 +121,35 @@ class Converter:
|
|||
command.extend(self.ffmpeg_arg.split())
|
||||
|
||||
if self.lossless:
|
||||
aformat = []
|
||||
|
||||
if isinstance(self.sampling_rate, int):
|
||||
sampling_rates = "|".join(
|
||||
sample_rates = "|".join(
|
||||
str(rate) for rate in SAMPLING_RATES if rate <= self.sampling_rate
|
||||
)
|
||||
command.extend(["-af", f"aformat=sample_rates={sampling_rates}"])
|
||||
|
||||
aformat.append(f"sample_rates={sample_rates}")
|
||||
elif self.sampling_rate is not None:
|
||||
raise TypeError(
|
||||
f"Sampling rate must be int, not {type(self.sampling_rate)}"
|
||||
)
|
||||
|
||||
if isinstance(self.bit_depth, int):
|
||||
if int(self.bit_depth) == 16:
|
||||
command.extend(["-sample_fmt", "s16"])
|
||||
elif int(self.bit_depth) in (24, 32):
|
||||
command.extend(["-sample_fmt", "s32p"])
|
||||
else:
|
||||
bit_depths = ["s16p", "s16"]
|
||||
|
||||
if self.bit_depth in (24, 32):
|
||||
bit_depths.extend(["s32p", "s32"])
|
||||
elif self.bit_depth != 16:
|
||||
raise ValueError("Bit depth must be 16, 24, or 32")
|
||||
|
||||
sample_fmts = "|".join(bit_depths)
|
||||
aformat.append(f"sample_fmts={sample_fmts}")
|
||||
elif self.bit_depth is not None:
|
||||
raise TypeError(f"Bit depth must be int, not {type(self.bit_depth)}")
|
||||
|
||||
if aformat:
|
||||
aformat_params = ":".join(aformat)
|
||||
command.extend(["-af", f"aformat={aformat_params}"])
|
||||
|
||||
# automatically overwrite
|
||||
command.extend(["-y", self.tempfile])
|
||||
|
||||
|
|
@ -148,7 +162,7 @@ class Converter:
|
|||
if self.ffmpeg_arg is not None and self.lossless:
|
||||
logger.debug(
|
||||
"Lossless codecs don't support extra arguments; "
|
||||
"the extra argument will be ignored"
|
||||
"the extra argument will be ignored",
|
||||
)
|
||||
self.ffmpeg_arg = self.default_ffmpeg_arg
|
||||
return
|
||||
|
|
@ -172,7 +186,7 @@ class LAME(Converter):
|
|||
https://trac.ffmpeg.org/wiki/Encode/MP3
|
||||
"""
|
||||
|
||||
__bitrate_map = {
|
||||
_bitrate_map: Final[dict[int, str]] = {
|
||||
320: "-b:a 320k",
|
||||
245: "-q:a 0",
|
||||
225: "-q:a 1",
|
||||
|
|
@ -192,7 +206,7 @@ class LAME(Converter):
|
|||
default_ffmpeg_arg = "-q:a 0" # V0
|
||||
|
||||
def get_quality_arg(self, rate):
|
||||
return self.__bitrate_map[rate]
|
||||
return self._bitrate_map[rate]
|
||||
|
||||
|
||||
class ALAC(Converter):
|
||||
|
|
@ -242,8 +256,8 @@ class OPUS(Converter):
|
|||
container = "opus"
|
||||
default_ffmpeg_arg = "-b:a 128k" # Transparent
|
||||
|
||||
def get_quality_arg(self, rate: int) -> str:
|
||||
pass
|
||||
def get_quality_arg(self, _: int) -> str:
|
||||
return ""
|
||||
|
||||
|
||||
class AAC(Converter):
|
||||
|
|
@ -260,5 +274,19 @@ class AAC(Converter):
|
|||
container = "m4a"
|
||||
default_ffmpeg_arg = "-b:a 256k"
|
||||
|
||||
def get_quality_arg(self, rate: int) -> str:
|
||||
pass
|
||||
def get_quality_arg(self, _: int) -> str:
|
||||
return ""
|
||||
|
||||
|
||||
def get(codec: str) -> type[Converter]:
|
||||
converter_classes = {
|
||||
"FLAC": FLAC,
|
||||
"ALAC": ALAC,
|
||||
"MP3": LAME,
|
||||
"OPUS": OPUS,
|
||||
"OGG": Vorbis,
|
||||
"VORBIS": Vorbis,
|
||||
"AAC": AAC,
|
||||
"M4A": AAC,
|
||||
}
|
||||
return converter_classes[codec.upper()]
|
||||
|
|
|
|||
|
|
@ -3,41 +3,76 @@
|
|||
import logging
|
||||
import os
|
||||
import sqlite3
|
||||
from typing import Tuple, Union
|
||||
from abc import ABC, abstractmethod
|
||||
from dataclasses import dataclass
|
||||
from typing import Final
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
|
||||
class Database:
|
||||
class DatabaseInterface(ABC):
|
||||
@abstractmethod
|
||||
def create(self):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def contains(self, **items) -> bool:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def add(self, kvs):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def remove(self, kvs):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def all(self) -> list:
|
||||
pass
|
||||
|
||||
|
||||
class Dummy(DatabaseInterface):
|
||||
"""This exists as a mock to use in case databases are disabled."""
|
||||
|
||||
def create(self):
|
||||
pass
|
||||
|
||||
def contains(self, **_):
|
||||
return False
|
||||
|
||||
def add(self, *_):
|
||||
pass
|
||||
|
||||
def remove(self, *_):
|
||||
pass
|
||||
|
||||
def all(self):
|
||||
return []
|
||||
|
||||
|
||||
class DatabaseBase(DatabaseInterface):
|
||||
"""A wrapper for an sqlite database."""
|
||||
|
||||
structure: dict
|
||||
name: str
|
||||
|
||||
def __init__(self, path, dummy=False):
|
||||
def __init__(self, path: str):
|
||||
"""Create a Database instance.
|
||||
|
||||
:param path: Path to the database file.
|
||||
:param dummy: Make the database empty.
|
||||
"""
|
||||
assert self.structure != []
|
||||
assert self.structure != {}
|
||||
assert self.name
|
||||
|
||||
if dummy or path is None:
|
||||
self.path = None
|
||||
self.is_dummy = True
|
||||
return
|
||||
self.is_dummy = False
|
||||
assert path
|
||||
|
||||
self.path = path
|
||||
|
||||
if not os.path.exists(self.path):
|
||||
self.create()
|
||||
|
||||
def create(self):
|
||||
"""Create a database."""
|
||||
if self.is_dummy:
|
||||
return
|
||||
|
||||
with sqlite3.connect(self.path) as conn:
|
||||
params = ", ".join(
|
||||
f"{key} {' '.join(map(str.upper, props))} NOT NULL"
|
||||
|
|
@ -59,9 +94,6 @@ class Database:
|
|||
:param items: a dict of column-name + expected value
|
||||
:rtype: bool
|
||||
"""
|
||||
if self.is_dummy:
|
||||
return False
|
||||
|
||||
allowed_keys = set(self.structure.keys())
|
||||
assert all(
|
||||
key in allowed_keys for key in items.keys()
|
||||
|
|
@ -77,44 +109,12 @@ class Database:
|
|||
|
||||
return bool(conn.execute(command, tuple(items.values())).fetchone()[0])
|
||||
|
||||
def __contains__(self, keys: Union[str, dict]) -> bool:
|
||||
"""Check whether a key-value pair exists in the database.
|
||||
|
||||
:param keys: Either a dict with the structure {key: value_to_search_for, ...},
|
||||
or if there is only one key in the table, value_to_search_for can be
|
||||
passed in by itself.
|
||||
:type keys: Union[str, dict]
|
||||
:rtype: bool
|
||||
"""
|
||||
if isinstance(keys, dict):
|
||||
return self.contains(**keys)
|
||||
|
||||
if isinstance(keys, str) and len(self.structure) == 1:
|
||||
only_key = tuple(self.structure.keys())[0]
|
||||
query = {only_key: keys}
|
||||
logger.debug("Searching for %s in database", query)
|
||||
return self.contains(**query)
|
||||
|
||||
raise TypeError(keys)
|
||||
|
||||
def add(self, items: Union[str, Tuple[str]]):
|
||||
def add(self, items: tuple[str]):
|
||||
"""Add a row to the table.
|
||||
|
||||
:param items: Column-name + value. Values must be provided for all cols.
|
||||
:type items: Tuple[str]
|
||||
"""
|
||||
if self.is_dummy:
|
||||
return
|
||||
|
||||
if isinstance(items, str):
|
||||
if len(self.structure) == 1:
|
||||
items = (items,)
|
||||
else:
|
||||
raise TypeError(
|
||||
"Only tables with 1 column can have string inputs. Use a list "
|
||||
"where len(list) == len(structure)."
|
||||
)
|
||||
|
||||
assert len(items) == len(self.structure)
|
||||
|
||||
params = ", ".join(self.structure.keys())
|
||||
|
|
@ -138,10 +138,6 @@ class Database:
|
|||
|
||||
:param items:
|
||||
"""
|
||||
# not in use currently
|
||||
if self.is_dummy:
|
||||
return
|
||||
|
||||
conditions = " AND ".join(f"{key}=?" for key in items.keys())
|
||||
command = f"DELETE FROM {self.name} WHERE {conditions}"
|
||||
|
||||
|
|
@ -149,13 +145,10 @@ class Database:
|
|||
logger.debug(command)
|
||||
conn.execute(command, tuple(items.values()))
|
||||
|
||||
def __iter__(self):
|
||||
def all(self):
|
||||
"""Iterate through the rows of the table."""
|
||||
if self.is_dummy:
|
||||
return ()
|
||||
|
||||
with sqlite3.connect(self.path) as conn:
|
||||
return conn.execute(f"SELECT * FROM {self.name}")
|
||||
return list(conn.execute(f"SELECT * FROM {self.name}"))
|
||||
|
||||
def reset(self):
|
||||
"""Delete the database file."""
|
||||
|
|
@ -165,24 +158,39 @@ class Database:
|
|||
pass
|
||||
|
||||
|
||||
class Downloads(Database):
|
||||
class Downloads(DatabaseBase):
|
||||
"""A table that stores the downloaded IDs."""
|
||||
|
||||
name = "downloads"
|
||||
structure = {
|
||||
structure: Final[dict] = {
|
||||
"id": ["text", "unique"],
|
||||
}
|
||||
|
||||
|
||||
class FailedDownloads(Database):
|
||||
class Failed(DatabaseBase):
|
||||
"""A table that stores information about failed downloads."""
|
||||
|
||||
name = "failed_downloads"
|
||||
structure = {
|
||||
structure: Final[dict] = {
|
||||
"source": ["text"],
|
||||
"media_type": ["text"],
|
||||
"id": ["text", "unique"],
|
||||
}
|
||||
|
||||
|
||||
CLASS_MAP = {db.name: db for db in (Downloads, FailedDownloads)}
|
||||
@dataclass(slots=True)
|
||||
class Database:
|
||||
downloads: DatabaseInterface
|
||||
failed: DatabaseInterface
|
||||
|
||||
def downloaded(self, item_id: str) -> bool:
|
||||
return self.downloads.contains(id=item_id)
|
||||
|
||||
def set_downloaded(self, item_id: str):
|
||||
self.downloads.add((item_id,))
|
||||
|
||||
def get_failed_downloads(self) -> list[tuple[str, str, str]]:
|
||||
return self.failed.all()
|
||||
|
||||
def set_failed(self, source: str, media_type: str, id: str):
|
||||
self.failed.add((source, media_type, id))
|
||||
|
|
@ -1,225 +0,0 @@
|
|||
import asyncio
|
||||
import functools
|
||||
import hashlib
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
from tempfile import gettempdir
|
||||
from typing import Callable, Dict, Iterator, List, Optional
|
||||
|
||||
import aiofiles
|
||||
import aiohttp
|
||||
from Cryptodome.Cipher import Blowfish
|
||||
|
||||
from .exceptions import NonStreamable
|
||||
from .utils import gen_threadsafe_session
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
|
||||
class DownloadStream:
|
||||
"""An iterator over chunks of a stream.
|
||||
|
||||
Usage:
|
||||
|
||||
>>> stream = DownloadStream('https://google.com', None)
|
||||
>>> with open('google.html', 'wb') as file:
|
||||
>>> for chunk in stream:
|
||||
>>> file.write(chunk)
|
||||
|
||||
"""
|
||||
|
||||
is_encrypted = re.compile("/m(?:obile|edia)/")
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
url: str,
|
||||
source: str = None,
|
||||
params: dict = None,
|
||||
headers: dict = None,
|
||||
item_id: str = None,
|
||||
):
|
||||
"""Create an iterable DownloadStream of a URL.
|
||||
|
||||
:param url: The url to download
|
||||
:type url: str
|
||||
:param source: Only applicable for Deezer
|
||||
:type source: str
|
||||
:param params: Parameters to pass in the request
|
||||
:type params: dict
|
||||
:param headers: Headers to pass in the request
|
||||
:type headers: dict
|
||||
:param item_id: (Only for Deezer) the ID of the track
|
||||
:type item_id: str
|
||||
"""
|
||||
self.source = source
|
||||
self.session = gen_threadsafe_session(headers=headers)
|
||||
|
||||
self.id = item_id
|
||||
if isinstance(self.id, int):
|
||||
self.id = str(self.id)
|
||||
|
||||
if params is None:
|
||||
params = {}
|
||||
|
||||
self.request = self.session.get(
|
||||
url, allow_redirects=True, stream=True, params=params
|
||||
)
|
||||
self.file_size = int(self.request.headers.get("Content-Length", 0))
|
||||
|
||||
if self.file_size < 20000 and not self.url.endswith(".jpg"):
|
||||
import json
|
||||
|
||||
try:
|
||||
info = self.request.json()
|
||||
try:
|
||||
# Usually happens with deezloader downloads
|
||||
raise NonStreamable(f"{info['error']} - {info['message']}")
|
||||
except KeyError:
|
||||
raise NonStreamable(info)
|
||||
|
||||
except json.JSONDecodeError:
|
||||
raise NonStreamable("File not found.")
|
||||
|
||||
def __iter__(self) -> Iterator:
|
||||
"""Iterate through chunks of the stream.
|
||||
|
||||
:rtype: Iterator
|
||||
"""
|
||||
if self.source == "deezer" and self.is_encrypted.search(self.url) is not None:
|
||||
assert isinstance(self.id, str), self.id
|
||||
|
||||
blowfish_key = self._generate_blowfish_key(self.id)
|
||||
# decryptor = self._create_deezer_decryptor(blowfish_key)
|
||||
CHUNK_SIZE = 2048 * 3
|
||||
return (
|
||||
# (decryptor.decrypt(chunk[:2048]) + chunk[2048:])
|
||||
(self._decrypt_chunk(blowfish_key, chunk[:2048]) + chunk[2048:])
|
||||
if len(chunk) >= 2048
|
||||
else chunk
|
||||
for chunk in self.request.iter_content(CHUNK_SIZE)
|
||||
)
|
||||
|
||||
return self.request.iter_content(chunk_size=1024)
|
||||
|
||||
@property
|
||||
def url(self):
|
||||
"""Return the requested url."""
|
||||
return self.request.url
|
||||
|
||||
def __len__(self) -> int:
|
||||
"""Return the value of the "Content-Length" header.
|
||||
|
||||
:rtype: int
|
||||
"""
|
||||
return self.file_size
|
||||
|
||||
def _create_deezer_decryptor(self, key) -> Blowfish:
|
||||
return Blowfish.new(key, Blowfish.MODE_CBC, b"\x00\x01\x02\x03\x04\x05\x06\x07")
|
||||
|
||||
@staticmethod
|
||||
def _generate_blowfish_key(track_id: str):
|
||||
"""Generate the blowfish key for Deezer downloads.
|
||||
|
||||
:param track_id:
|
||||
:type track_id: str
|
||||
"""
|
||||
SECRET = "g4el58wc0zvf9na1"
|
||||
md5_hash = hashlib.md5(track_id.encode()).hexdigest()
|
||||
# good luck :)
|
||||
return "".join(
|
||||
chr(functools.reduce(lambda x, y: x ^ y, map(ord, t)))
|
||||
for t in zip(md5_hash[:16], md5_hash[16:], SECRET)
|
||||
).encode()
|
||||
|
||||
@staticmethod
|
||||
def _decrypt_chunk(key, data):
|
||||
"""Decrypt a chunk of a Deezer stream.
|
||||
|
||||
:param key:
|
||||
:param data:
|
||||
"""
|
||||
return Blowfish.new(
|
||||
key,
|
||||
Blowfish.MODE_CBC,
|
||||
b"\x00\x01\x02\x03\x04\x05\x06\x07",
|
||||
).decrypt(data)
|
||||
|
||||
|
||||
class DownloadPool:
|
||||
"""Asynchronously download a set of urls."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
urls: Iterator,
|
||||
tempdir: str = None,
|
||||
chunk_callback: Optional[Callable] = None,
|
||||
):
|
||||
self.finished: bool = False
|
||||
# Enumerate urls to know the order
|
||||
self.urls = dict(enumerate(urls))
|
||||
self._downloaded_urls: List[str] = []
|
||||
# {url: path}
|
||||
self._paths: Dict[str, str] = {}
|
||||
self.task: Optional[asyncio.Task] = None
|
||||
|
||||
if tempdir is None:
|
||||
tempdir = gettempdir()
|
||||
self.tempdir = tempdir
|
||||
|
||||
async def getfn(self, url):
|
||||
path = os.path.join(self.tempdir, f"__streamrip_partial_{abs(hash(url))}")
|
||||
self._paths[url] = path
|
||||
return path
|
||||
|
||||
async def _download_urls(self):
|
||||
async with aiohttp.ClientSession() as session:
|
||||
tasks = [
|
||||
asyncio.ensure_future(self._download_url(session, url))
|
||||
for url in self.urls.values()
|
||||
]
|
||||
await asyncio.gather(*tasks)
|
||||
|
||||
async def _download_url(self, session, url):
|
||||
filename = await self.getfn(url)
|
||||
logger.debug("Downloading %s", url)
|
||||
async with session.get(url) as response, aiofiles.open(filename, "wb") as f:
|
||||
# without aiofiles 3.6632679780000004s
|
||||
# with aiofiles 2.504482839s
|
||||
await f.write(await response.content.read())
|
||||
|
||||
if self.callback:
|
||||
self.callback()
|
||||
|
||||
logger.debug("Finished %s", url)
|
||||
|
||||
def download(self, callback=None):
|
||||
self.callback = callback
|
||||
asyncio.run(self._download_urls())
|
||||
|
||||
@property
|
||||
def files(self):
|
||||
if len(self._paths) != len(self.urls):
|
||||
# Not all of them have downloaded
|
||||
raise Exception("Must run DownloadPool.download() before accessing files")
|
||||
|
||||
return [
|
||||
os.path.join(self.tempdir, self._paths[self.urls[i]])
|
||||
for i in range(len(self.urls))
|
||||
]
|
||||
|
||||
def __len__(self):
|
||||
return len(self.urls)
|
||||
|
||||
def __enter__(self):
|
||||
return self
|
||||
|
||||
def __exit__(self, exc_type, exc_val, exc_tb):
|
||||
logger.debug("Removing tempfiles %s", self._paths)
|
||||
for file in self._paths.values():
|
||||
try:
|
||||
os.remove(file)
|
||||
except FileNotFoundError:
|
||||
pass
|
||||
|
||||
return False
|
||||
|
|
@ -1,5 +1,4 @@
|
|||
"""Streamrip specific exceptions."""
|
||||
from typing import List
|
||||
|
||||
from click import echo, style
|
||||
|
||||
|
|
@ -8,7 +7,7 @@ class AuthenticationError(Exception):
|
|||
"""AuthenticationError."""
|
||||
|
||||
|
||||
class MissingCredentials(Exception):
|
||||
class MissingCredentialsError(Exception):
|
||||
"""MissingCredentials."""
|
||||
|
||||
|
||||
|
|
@ -27,11 +26,7 @@ class InvalidAppSecretError(Exception):
|
|||
"""InvalidAppSecretError."""
|
||||
|
||||
|
||||
class InvalidQuality(Exception):
|
||||
"""InvalidQuality."""
|
||||
|
||||
|
||||
class NonStreamable(Exception):
|
||||
class NonStreamableError(Exception):
|
||||
"""Item is not streamable.
|
||||
|
||||
A versatile error that can have many causes.
|
||||
|
|
@ -65,52 +60,11 @@ class NonStreamable(Exception):
|
|||
(
|
||||
style("Message:", fg="yellow"),
|
||||
style(self.message, fg="red"),
|
||||
)
|
||||
),
|
||||
)
|
||||
|
||||
return " ".join(base_msg)
|
||||
|
||||
|
||||
class InvalidContainerError(Exception):
|
||||
"""InvalidContainerError."""
|
||||
|
||||
|
||||
class InvalidSourceError(Exception):
|
||||
"""InvalidSourceError."""
|
||||
|
||||
|
||||
class ParsingError(Exception):
|
||||
"""ParsingError."""
|
||||
|
||||
|
||||
class TooLargeCoverArt(Exception):
|
||||
"""TooLargeCoverArt."""
|
||||
|
||||
|
||||
class BadEncoderOption(Exception):
|
||||
"""BadEncoderOption."""
|
||||
|
||||
|
||||
class ConversionError(Exception):
|
||||
"""ConversionError."""
|
||||
|
||||
|
||||
class NoResultsFound(Exception):
|
||||
"""NoResultsFound."""
|
||||
|
||||
|
||||
class ItemExists(Exception):
|
||||
"""ItemExists."""
|
||||
|
||||
|
||||
class PartialFailure(Exception):
|
||||
"""Raise if part of a tracklist fails to download."""
|
||||
|
||||
def __init__(self, failed_items: List):
|
||||
"""Create a PartialFailure exception.
|
||||
|
||||
:param failed_items:
|
||||
:type failed_items: List
|
||||
"""
|
||||
self.failed_items = failed_items
|
||||
super().__init__()
|
||||
|
|
|
|||
|
|
@ -0,0 +1,21 @@
|
|||
from string import printable
|
||||
|
||||
from pathvalidate import sanitize_filename, sanitize_filepath # type: ignore
|
||||
|
||||
ALLOWED_CHARS = set(printable)
|
||||
|
||||
|
||||
def clean_filename(fn: str, restrict: bool = False) -> str:
|
||||
path = str(sanitize_filename(fn))
|
||||
if restrict:
|
||||
path = "".join(c for c in path if c in ALLOWED_CHARS)
|
||||
|
||||
return path
|
||||
|
||||
|
||||
def clean_filepath(fn: str, restrict: bool = False) -> str:
|
||||
path = str(sanitize_filepath(fn))
|
||||
if restrict:
|
||||
path = "".join(c for c in path if c in ALLOWED_CHARS)
|
||||
|
||||
return path
|
||||
2380
streamrip/media.py
|
|
@ -0,0 +1,31 @@
|
|||
from .album import Album, PendingAlbum
|
||||
from .artist import Artist, PendingArtist
|
||||
from .artwork import remove_artwork_tempdirs
|
||||
from .label import Label, PendingLabel
|
||||
from .media import Media, Pending
|
||||
from .playlist import (
|
||||
PendingLastfmPlaylist,
|
||||
PendingPlaylist,
|
||||
PendingPlaylistTrack,
|
||||
Playlist,
|
||||
)
|
||||
from .track import PendingSingle, PendingTrack, Track
|
||||
|
||||
__all__ = [
|
||||
"Media",
|
||||
"Pending",
|
||||
"Album",
|
||||
"PendingAlbum",
|
||||
"Artist",
|
||||
"PendingArtist",
|
||||
"Label",
|
||||
"PendingLabel",
|
||||
"Playlist",
|
||||
"PendingPlaylist",
|
||||
"PendingLastfmPlaylist",
|
||||
"Track",
|
||||
"PendingTrack",
|
||||
"PendingPlaylistTrack",
|
||||
"PendingSingle",
|
||||
"remove_artwork_tempdirs",
|
||||
]
|
||||
|
|
@ -0,0 +1,109 @@
|
|||
import asyncio
|
||||
import logging
|
||||
import os
|
||||
from dataclasses import dataclass
|
||||
|
||||
from .. import progress
|
||||
from ..client import Client
|
||||
from ..config import Config
|
||||
from ..db import Database
|
||||
from ..exceptions import NonStreamableError
|
||||
from ..filepath_utils import clean_filepath
|
||||
from ..metadata import AlbumMetadata
|
||||
from ..metadata.util import get_album_track_ids
|
||||
from .artwork import download_artwork
|
||||
from .media import Media, Pending
|
||||
from .track import PendingTrack
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class Album(Media):
|
||||
meta: AlbumMetadata
|
||||
tracks: list[PendingTrack]
|
||||
config: Config
|
||||
# folder where the tracks will be downloaded
|
||||
folder: str
|
||||
db: Database
|
||||
|
||||
async def preprocess(self):
|
||||
progress.add_title(self.meta.album)
|
||||
|
||||
async def download(self):
|
||||
async def _resolve_and_download(pending: Pending):
|
||||
track = await pending.resolve()
|
||||
if track is None:
|
||||
return
|
||||
await track.rip()
|
||||
|
||||
await asyncio.gather(*[_resolve_and_download(p) for p in self.tracks])
|
||||
|
||||
async def postprocess(self):
|
||||
progress.remove_title(self.meta.album)
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class PendingAlbum(Pending):
|
||||
id: str
|
||||
client: Client
|
||||
config: Config
|
||||
db: Database
|
||||
|
||||
async def resolve(self) -> Album | None:
|
||||
try:
|
||||
resp = await self.client.get_metadata(self.id, "album")
|
||||
except NonStreamableError as e:
|
||||
logger.error(
|
||||
f"Album {self.id} not available to stream on {self.client.source} ({e})",
|
||||
)
|
||||
return None
|
||||
|
||||
try:
|
||||
meta = AlbumMetadata.from_album_resp(resp, self.client.source)
|
||||
except Exception as e:
|
||||
logger.error(f"Error building album metadata for {id=}: {e}")
|
||||
return None
|
||||
|
||||
if meta is None:
|
||||
logger.error(
|
||||
f"Album {self.id} not available to stream on {self.client.source}",
|
||||
)
|
||||
return None
|
||||
|
||||
tracklist = get_album_track_ids(self.client.source, resp)
|
||||
folder = self.config.session.downloads.folder
|
||||
album_folder = self._album_folder(folder, meta)
|
||||
os.makedirs(album_folder, exist_ok=True)
|
||||
embed_cover, _ = await download_artwork(
|
||||
self.client.session,
|
||||
album_folder,
|
||||
meta.covers,
|
||||
self.config.session.artwork,
|
||||
for_playlist=False,
|
||||
)
|
||||
pending_tracks = [
|
||||
PendingTrack(
|
||||
id,
|
||||
album=meta,
|
||||
client=self.client,
|
||||
config=self.config,
|
||||
folder=album_folder,
|
||||
db=self.db,
|
||||
cover_path=embed_cover,
|
||||
)
|
||||
for id in tracklist
|
||||
]
|
||||
logger.debug("Pending tracks: %s", pending_tracks)
|
||||
return Album(meta, pending_tracks, self.config, album_folder, self.db)
|
||||
|
||||
def _album_folder(self, parent: str, meta: AlbumMetadata) -> str:
|
||||
config = self.config.session
|
||||
if config.downloads.source_subdirectories:
|
||||
parent = os.path.join(parent, self.client.source.capitalize())
|
||||
formatter = config.filepaths.folder_format
|
||||
folder = clean_filepath(
|
||||
meta.format_folder_path(formatter), config.filepaths.restrict_characters
|
||||
)
|
||||
|
||||
return os.path.join(parent, folder)
|
||||
|
|
@ -0,0 +1,205 @@
|
|||
import asyncio
|
||||
import logging
|
||||
import re
|
||||
from dataclasses import dataclass
|
||||
|
||||
from ..client import Client
|
||||
from ..config import Config, QobuzDiscographyFilterConfig
|
||||
from ..console import console
|
||||
from ..db import Database
|
||||
from ..exceptions import NonStreamableError
|
||||
from ..metadata import ArtistMetadata
|
||||
from .album import Album, PendingAlbum
|
||||
from .media import Media, Pending
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
# Resolve only N albums at a time to avoid
|
||||
# initial latency of resolving ALL albums and tracks
|
||||
# before any downloads
|
||||
RESOLVE_CHUNK_SIZE = 10
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class Artist(Media):
|
||||
"""Represents a list of albums. Used by Artist and Label classes."""
|
||||
|
||||
name: str
|
||||
albums: list[PendingAlbum]
|
||||
client: Client
|
||||
config: Config
|
||||
|
||||
async def preprocess(self):
|
||||
pass
|
||||
|
||||
async def download(self):
|
||||
filter_conf = self.config.session.qobuz_filters
|
||||
if filter_conf.repeats:
|
||||
console.log(
|
||||
"Resolving [purple]ALL[/purple] artist albums to detect repeats. This may take a while."
|
||||
)
|
||||
await self._resolve_then_download(filter_conf)
|
||||
else:
|
||||
await self._download_async(filter_conf)
|
||||
|
||||
async def postprocess(self):
|
||||
pass
|
||||
|
||||
async def _resolve_then_download(self, filters: QobuzDiscographyFilterConfig):
|
||||
"""Resolve all artist albums, then download.
|
||||
|
||||
This is used if the repeat filter is turned on, since we need the titles
|
||||
of all albums to remove repeated items.
|
||||
"""
|
||||
resolved_or_none: list[Album | None] = await asyncio.gather(
|
||||
*[album.resolve() for album in self.albums]
|
||||
)
|
||||
resolved = [a for a in resolved_or_none if a is not None]
|
||||
filtered_albums = self._apply_filters(resolved, filters)
|
||||
batches = self.batch([a.rip() for a in filtered_albums], RESOLVE_CHUNK_SIZE)
|
||||
for batch in batches:
|
||||
await asyncio.gather(*batch)
|
||||
|
||||
async def _download_async(self, filters: QobuzDiscographyFilterConfig):
|
||||
async def _rip(item: PendingAlbum):
|
||||
album = await item.resolve()
|
||||
# Skip if album doesn't pass the filter
|
||||
if (
|
||||
album is None
|
||||
or (filters.extras and not self._extras(album))
|
||||
or (filters.features and not self._features(album))
|
||||
or (filters.non_studio_albums and not self._non_studio_albums(album))
|
||||
or (filters.non_remaster and not self._non_remaster(album))
|
||||
):
|
||||
return
|
||||
await album.rip()
|
||||
|
||||
batches = self.batch(
|
||||
[_rip(album) for album in self.albums],
|
||||
RESOLVE_CHUNK_SIZE,
|
||||
)
|
||||
for batch in batches:
|
||||
await asyncio.gather(*batch)
|
||||
|
||||
def _apply_filters(
|
||||
self, albums: list[Album], filt: QobuzDiscographyFilterConfig
|
||||
) -> list[Album]:
|
||||
_albums = albums
|
||||
if filt.repeats:
|
||||
_albums = self._filter_repeats(_albums)
|
||||
if filt.extras:
|
||||
_albums = filter(self._extras, _albums)
|
||||
if filt.features:
|
||||
_albums = filter(self._features, _albums)
|
||||
if filt.non_studio_albums:
|
||||
_albums = filter(self._non_studio_albums, _albums)
|
||||
if filt.non_remaster:
|
||||
_albums = filter(self._non_remaster, _albums)
|
||||
return list(_albums)
|
||||
|
||||
# Will not fail on any nonempty string
|
||||
_essence = re.compile(r"([^\(]+)(?:\s*[\(\[][^\)][\)\]])*")
|
||||
|
||||
def _filter_repeats(self, albums: list[Album]) -> list[Album]:
|
||||
"""When there are different versions of an album on the artist,
|
||||
choose the one with the best quality.
|
||||
|
||||
It determines that two albums are identical if they have the same title
|
||||
ignoring contents in brackets or parentheses.
|
||||
"""
|
||||
groups: dict[str, list[Album]] = {}
|
||||
for a in albums:
|
||||
match = self._essence.match(a.meta.album)
|
||||
assert match is not None
|
||||
title = match.group(1).strip().lower()
|
||||
items = groups.get(title, [])
|
||||
items.append(a)
|
||||
groups[title] = items
|
||||
|
||||
ret: list[Album] = []
|
||||
for group in groups.values():
|
||||
best = None
|
||||
max_bd, max_sr = 0, 0
|
||||
# assume that highest bd is always with highest sr
|
||||
for album in group:
|
||||
bd = album.meta.info.bit_depth or 0
|
||||
if bd > max_bd:
|
||||
max_bd = bd
|
||||
best = album
|
||||
|
||||
sr = album.meta.info.sampling_rate or 0
|
||||
if sr > max_sr:
|
||||
max_sr = sr
|
||||
best = album
|
||||
|
||||
assert best is not None # true because all g != []
|
||||
ret.append(best)
|
||||
|
||||
return ret
|
||||
|
||||
_extra_re = re.compile(
|
||||
r"(?i)(anniversary|deluxe|live|collector|demo|expanded|remix)"
|
||||
)
|
||||
|
||||
# ----- Filter predicates -----
|
||||
def _non_studio_albums(self, a: Album) -> bool:
|
||||
"""Filter out non studio albums."""
|
||||
return a.meta.albumartist != "Various Artists" and self._extras(a)
|
||||
|
||||
def _features(self, a: Album) -> bool:
|
||||
"""Filter out features."""
|
||||
return a.meta.albumartist == self.name
|
||||
|
||||
def _extras(self, a: Album) -> bool:
|
||||
"""Filter out extras.
|
||||
|
||||
See `_extra_re` for criteria.
|
||||
"""
|
||||
return self._extra_re.search(a.meta.album) is None
|
||||
|
||||
_remaster_re = re.compile(r"(?i)(re)?master(ed)?")
|
||||
|
||||
def _non_remaster(self, a: Album) -> bool:
|
||||
"""Filter out albums that are not remasters."""
|
||||
return self._remaster_re.search(a.meta.album) is not None
|
||||
|
||||
def _non_albums(self, a: Album) -> bool:
|
||||
"""Filter out singles."""
|
||||
return len(a.tracks) > 1
|
||||
|
||||
@staticmethod
|
||||
def batch(iterable, n=1):
|
||||
total = len(iterable)
|
||||
for ndx in range(0, total, n):
|
||||
yield iterable[ndx : min(ndx + n, total)]
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class PendingArtist(Pending):
|
||||
id: str
|
||||
client: Client
|
||||
config: Config
|
||||
db: Database
|
||||
|
||||
async def resolve(self) -> Artist | None:
|
||||
try:
|
||||
resp = await self.client.get_metadata(self.id, "artist")
|
||||
except NonStreamableError as e:
|
||||
logger.error(
|
||||
f"Artist {self.id} not available to stream on {self.client.source} ({e})",
|
||||
)
|
||||
return None
|
||||
|
||||
try:
|
||||
meta = ArtistMetadata.from_resp(resp, self.client.source)
|
||||
except Exception as e:
|
||||
logger.error(
|
||||
f"Error building artist metadata: {e}",
|
||||
)
|
||||
return None
|
||||
|
||||
albums = [
|
||||
PendingAlbum(album_id, self.client, self.config, self.db)
|
||||
for album_id in meta.album_ids()
|
||||
]
|
||||
return Artist(meta.name, albums, self.client, self.config)
|
||||
|
|
@ -0,0 +1,153 @@
|
|||
import asyncio
|
||||
import logging
|
||||
import os
|
||||
import shutil
|
||||
|
||||
import aiohttp
|
||||
from PIL import Image
|
||||
|
||||
from ..client import BasicDownloadable
|
||||
from ..config import ArtworkConfig
|
||||
from ..metadata import Covers
|
||||
|
||||
_artwork_tempdirs: set[str] = set()
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
|
||||
def remove_artwork_tempdirs():
|
||||
logger.debug("Removing dirs %s", _artwork_tempdirs)
|
||||
for path in _artwork_tempdirs:
|
||||
try:
|
||||
shutil.rmtree(path)
|
||||
except FileNotFoundError:
|
||||
pass
|
||||
|
||||
|
||||
async def download_artwork(
|
||||
session: aiohttp.ClientSession,
|
||||
folder: str,
|
||||
covers: Covers,
|
||||
config: ArtworkConfig,
|
||||
for_playlist: bool,
|
||||
) -> tuple[str | None, str | None]:
|
||||
"""Download artwork and update passed Covers object with filepaths.
|
||||
|
||||
If paths for the selected sizes already exist in `covers`, nothing will
|
||||
be downloaded.
|
||||
|
||||
If `for_playlist` is set, it will not download hires cover art regardless
|
||||
of the config setting.
|
||||
|
||||
Embedded artworks are put in a temporary directory under `folder` called
|
||||
"__embed" that can be deleted once a playlist or album is done downloading.
|
||||
|
||||
Hi-res (saved) artworks are kept in `folder` as "cover.jpg".
|
||||
|
||||
Args:
|
||||
----
|
||||
session (aiohttp.ClientSession):
|
||||
folder (str):
|
||||
covers (Covers):
|
||||
config (ArtworkConfig):
|
||||
for_playlist (bool): Set to disable saved hires covers.
|
||||
|
||||
Returns:
|
||||
-------
|
||||
(path to embedded artwork, path to hires artwork)
|
||||
"""
|
||||
save_artwork, embed = config.save_artwork, config.embed
|
||||
if for_playlist:
|
||||
save_artwork = False
|
||||
|
||||
if not (save_artwork or embed) or covers.empty():
|
||||
# No need to download anything
|
||||
return None, None
|
||||
|
||||
downloadables = []
|
||||
|
||||
_, l_url, saved_cover_path = covers.largest()
|
||||
if saved_cover_path is None and save_artwork:
|
||||
saved_cover_path = os.path.join(folder, "cover.jpg")
|
||||
assert l_url is not None
|
||||
downloadables.append(
|
||||
BasicDownloadable(session, l_url, "jpg").download(
|
||||
saved_cover_path,
|
||||
lambda _: None,
|
||||
),
|
||||
)
|
||||
|
||||
_, embed_url, embed_cover_path = covers.get_size(config.embed_size)
|
||||
if embed_cover_path is None and embed:
|
||||
assert embed_url is not None
|
||||
embed_dir = os.path.join(folder, "__artwork")
|
||||
os.makedirs(embed_dir, exist_ok=True)
|
||||
_artwork_tempdirs.add(embed_dir)
|
||||
embed_cover_path = os.path.join(embed_dir, f"cover{hash(embed_url)}.jpg")
|
||||
downloadables.append(
|
||||
BasicDownloadable(session, embed_url, "jpg").download(
|
||||
embed_cover_path,
|
||||
lambda _: None,
|
||||
),
|
||||
)
|
||||
|
||||
if len(downloadables) == 0:
|
||||
return embed_cover_path, saved_cover_path
|
||||
|
||||
try:
|
||||
await asyncio.gather(*downloadables)
|
||||
except Exception as e:
|
||||
logger.error(f"Error downloading artwork: {e}")
|
||||
return None, None
|
||||
|
||||
# Update `covers` to reflect the current download state
|
||||
if save_artwork:
|
||||
assert saved_cover_path is not None
|
||||
covers.set_largest_path(saved_cover_path)
|
||||
if config.saved_max_width > 0:
|
||||
downscale_image(saved_cover_path, config.saved_max_width)
|
||||
|
||||
if embed:
|
||||
assert embed_cover_path is not None
|
||||
covers.set_path(config.embed_size, embed_cover_path)
|
||||
if config.embed_max_width > 0:
|
||||
downscale_image(embed_cover_path, config.embed_max_width)
|
||||
|
||||
return embed_cover_path, saved_cover_path
|
||||
|
||||
|
||||
def downscale_image(input_image_path: str, max_dimension: int):
|
||||
"""Downscale an image in place given a maximum allowed dimension.
|
||||
|
||||
Args:
|
||||
----
|
||||
input_image_path (str): Path to image
|
||||
max_dimension (int): Maximum dimension allowed
|
||||
|
||||
Returns:
|
||||
-------
|
||||
|
||||
|
||||
"""
|
||||
# Open the image
|
||||
image = Image.open(input_image_path)
|
||||
|
||||
# Get the original width and height
|
||||
width, height = image.size
|
||||
|
||||
if max_dimension >= max(width, height):
|
||||
return
|
||||
|
||||
# Calculate the new dimensions while maintaining the aspect ratio
|
||||
if width > height:
|
||||
new_width = max_dimension
|
||||
new_height = int(height * (max_dimension / width))
|
||||
else:
|
||||
new_height = max_dimension
|
||||
new_width = int(width * (max_dimension / height))
|
||||
|
||||
# Resize the image with the new dimensions
|
||||
resized_image = image.resize((new_width, new_height))
|
||||
|
||||
# Save the resized image
|
||||
resized_image.save(input_image_path)
|
||||
|
|
@ -0,0 +1,80 @@
|
|||
import asyncio
|
||||
import logging
|
||||
from dataclasses import dataclass
|
||||
|
||||
from streamrip.exceptions import NonStreamableError
|
||||
|
||||
from ..client import Client
|
||||
from ..config import Config
|
||||
from ..db import Database
|
||||
from ..metadata import LabelMetadata
|
||||
from .album import PendingAlbum
|
||||
from .media import Media, Pending
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class Label(Media):
|
||||
"""Represents a list of albums. Used by Artist and Label classes."""
|
||||
|
||||
name: str
|
||||
albums: list[PendingAlbum]
|
||||
client: Client
|
||||
config: Config
|
||||
|
||||
async def preprocess(self):
|
||||
pass
|
||||
|
||||
async def download(self):
|
||||
# Resolve only 3 albums at a time to avoid
|
||||
# initial latency of resolving ALL albums and tracks
|
||||
# before any downloads
|
||||
album_resolve_chunk_size = 10
|
||||
|
||||
async def _resolve_download(item: PendingAlbum):
|
||||
album = await item.resolve()
|
||||
if album is None:
|
||||
return
|
||||
await album.rip()
|
||||
|
||||
batches = self.batch(
|
||||
[_resolve_download(album) for album in self.albums],
|
||||
album_resolve_chunk_size,
|
||||
)
|
||||
for batch in batches:
|
||||
await asyncio.gather(*batch)
|
||||
|
||||
async def postprocess(self):
|
||||
pass
|
||||
|
||||
@staticmethod
|
||||
def batch(iterable, n=1):
|
||||
total = len(iterable)
|
||||
for ndx in range(0, total, n):
|
||||
yield iterable[ndx : min(ndx + n, total)]
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class PendingLabel(Pending):
|
||||
id: str
|
||||
client: Client
|
||||
config: Config
|
||||
db: Database
|
||||
|
||||
async def resolve(self) -> Label | None:
|
||||
try:
|
||||
resp = await self.client.get_metadata(self.id, "label")
|
||||
except NonStreamableError as e:
|
||||
logger.error(f"Error resolving Label: {e}")
|
||||
return None
|
||||
try:
|
||||
meta = LabelMetadata.from_resp(resp, self.client.source)
|
||||
except Exception as e:
|
||||
logger.error(f"Error resolving Label: {e}")
|
||||
return None
|
||||
albums = [
|
||||
PendingAlbum(album_id, self.client, self.config, self.db)
|
||||
for album_id in meta.album_ids()
|
||||
]
|
||||
return Label(meta.name, albums, self.client, self.config)
|
||||
|
|
@ -0,0 +1,32 @@
|
|||
from abc import ABC, abstractmethod
|
||||
|
||||
|
||||
class Media(ABC):
|
||||
async def rip(self):
|
||||
await self.preprocess()
|
||||
await self.download()
|
||||
await self.postprocess()
|
||||
|
||||
@abstractmethod
|
||||
async def preprocess(self):
|
||||
"""Create directories, download cover art, etc."""
|
||||
raise NotImplementedError
|
||||
|
||||
@abstractmethod
|
||||
async def download(self):
|
||||
"""Download and tag the actual audio files in the correct directories."""
|
||||
raise NotImplementedError
|
||||
|
||||
@abstractmethod
|
||||
async def postprocess(self):
|
||||
"""Update database, run conversion, delete garbage files etc."""
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
class Pending(ABC):
|
||||
"""A request to download a `Media` whose metadata has not been fetched."""
|
||||
|
||||
@abstractmethod
|
||||
async def resolve(self) -> Media | None:
|
||||
"""Fetch metadata and resolve into a downloadable `Media` object."""
|
||||
raise NotImplementedError
|
||||
|
|
@ -0,0 +1,397 @@
|
|||
import asyncio
|
||||
import html
|
||||
import logging
|
||||
import os
|
||||
import random
|
||||
import re
|
||||
from contextlib import ExitStack
|
||||
from dataclasses import dataclass
|
||||
|
||||
import aiohttp
|
||||
from rich.text import Text
|
||||
|
||||
from .. import progress
|
||||
from ..client import Client
|
||||
from ..config import Config
|
||||
from ..console import console
|
||||
from ..db import Database
|
||||
from ..exceptions import NonStreamableError
|
||||
from ..filepath_utils import clean_filepath
|
||||
from ..metadata import (
|
||||
AlbumMetadata,
|
||||
Covers,
|
||||
PlaylistMetadata,
|
||||
SearchResults,
|
||||
TrackMetadata,
|
||||
)
|
||||
from .artwork import download_artwork
|
||||
from .media import Media, Pending
|
||||
from .track import Track
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class PendingPlaylistTrack(Pending):
|
||||
id: str
|
||||
client: Client
|
||||
config: Config
|
||||
folder: str
|
||||
playlist_name: str
|
||||
position: int
|
||||
db: Database
|
||||
|
||||
async def resolve(self) -> Track | None:
|
||||
if self.db.downloaded(self.id):
|
||||
logger.info(f"Track ({self.id}) already logged in database. Skipping.")
|
||||
return None
|
||||
try:
|
||||
resp = await self.client.get_metadata(self.id, "track")
|
||||
except NonStreamableError as e:
|
||||
logger.error(f"Could not stream track {self.id}: {e}")
|
||||
return None
|
||||
|
||||
album = AlbumMetadata.from_track_resp(resp, self.client.source)
|
||||
if album is None:
|
||||
logger.error(
|
||||
f"Track ({self.id}) not available for stream on {self.client.source}",
|
||||
)
|
||||
self.db.set_failed(self.client.source, "track", self.id)
|
||||
return None
|
||||
meta = TrackMetadata.from_resp(album, self.client.source, resp)
|
||||
if meta is None:
|
||||
logger.error(
|
||||
f"Track ({self.id}) not available for stream on {self.client.source}",
|
||||
)
|
||||
self.db.set_failed(self.client.source, "track", self.id)
|
||||
return None
|
||||
|
||||
c = self.config.session.metadata
|
||||
if c.renumber_playlist_tracks:
|
||||
meta.tracknumber = self.position
|
||||
if c.set_playlist_to_album:
|
||||
album.album = self.playlist_name
|
||||
|
||||
quality = self.config.session.get_source(self.client.source).quality
|
||||
try:
|
||||
embedded_cover_path, downloadable = await asyncio.gather(
|
||||
self._download_cover(album.covers, self.folder),
|
||||
self.client.get_downloadable(self.id, quality),
|
||||
)
|
||||
except NonStreamableError as e:
|
||||
logger.error("Error fetching download info for track: %s", e)
|
||||
self.db.set_failed(self.client.source, "track", self.id)
|
||||
return None
|
||||
|
||||
return Track(
|
||||
meta,
|
||||
downloadable,
|
||||
self.config,
|
||||
self.folder,
|
||||
embedded_cover_path,
|
||||
self.db,
|
||||
)
|
||||
|
||||
async def _download_cover(self, covers: Covers, folder: str) -> str | None:
|
||||
embed_path, _ = await download_artwork(
|
||||
self.client.session,
|
||||
folder,
|
||||
covers,
|
||||
self.config.session.artwork,
|
||||
for_playlist=True,
|
||||
)
|
||||
return embed_path
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class Playlist(Media):
|
||||
name: str
|
||||
config: Config
|
||||
client: Client
|
||||
tracks: list[PendingPlaylistTrack]
|
||||
|
||||
async def preprocess(self):
|
||||
progress.add_title(self.name)
|
||||
|
||||
async def postprocess(self):
|
||||
progress.remove_title(self.name)
|
||||
|
||||
async def download(self):
|
||||
track_resolve_chunk_size = 20
|
||||
|
||||
async def _resolve_download(item: PendingPlaylistTrack):
|
||||
track = await item.resolve()
|
||||
if track is None:
|
||||
return
|
||||
await track.rip()
|
||||
|
||||
batches = self.batch(
|
||||
[_resolve_download(track) for track in self.tracks],
|
||||
track_resolve_chunk_size,
|
||||
)
|
||||
for batch in batches:
|
||||
await asyncio.gather(*batch)
|
||||
|
||||
@staticmethod
|
||||
def batch(iterable, n=1):
|
||||
total = len(iterable)
|
||||
for ndx in range(0, total, n):
|
||||
yield iterable[ndx : min(ndx + n, total)]
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class PendingPlaylist(Pending):
|
||||
id: str
|
||||
client: Client
|
||||
config: Config
|
||||
db: Database
|
||||
|
||||
async def resolve(self) -> Playlist | None:
|
||||
try:
|
||||
resp = await self.client.get_metadata(self.id, "playlist")
|
||||
except NonStreamableError as e:
|
||||
logger.error(
|
||||
f"Playlist {self.id} not available to stream on {self.client.source} ({e})",
|
||||
)
|
||||
return None
|
||||
|
||||
try:
|
||||
meta = PlaylistMetadata.from_resp(resp, self.client.source)
|
||||
except Exception as e:
|
||||
logger.error(f"Error creating playlist: {e}")
|
||||
return None
|
||||
name = meta.name
|
||||
parent = self.config.session.downloads.folder
|
||||
folder = os.path.join(parent, clean_filepath(name))
|
||||
tracks = [
|
||||
PendingPlaylistTrack(
|
||||
id,
|
||||
self.client,
|
||||
self.config,
|
||||
folder,
|
||||
name,
|
||||
position + 1,
|
||||
self.db,
|
||||
)
|
||||
for position, id in enumerate(meta.ids())
|
||||
]
|
||||
return Playlist(name, self.config, self.client, tracks)
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class PendingLastfmPlaylist(Pending):
|
||||
lastfm_url: str
|
||||
client: Client
|
||||
fallback_client: Client | None
|
||||
config: Config
|
||||
db: Database
|
||||
|
||||
@dataclass(slots=True)
|
||||
class Status:
|
||||
found: int
|
||||
failed: int
|
||||
total: int
|
||||
|
||||
def text(self) -> Text:
|
||||
return Text.assemble(
|
||||
"Searching for last.fm tracks (",
|
||||
(f"{self.found} found", "bold green"),
|
||||
", ",
|
||||
(f"{self.failed} failed", "bold red"),
|
||||
", ",
|
||||
(f"{self.total} total", "bold"),
|
||||
")",
|
||||
)
|
||||
|
||||
async def resolve(self) -> Playlist | None:
|
||||
try:
|
||||
playlist_title, titles_artists = await self._parse_lastfm_playlist(
|
||||
self.lastfm_url,
|
||||
)
|
||||
except Exception as e:
|
||||
logger.error("Error occured while parsing last.fm page: %s", e)
|
||||
return None
|
||||
|
||||
requests = []
|
||||
|
||||
s = self.Status(0, 0, len(titles_artists))
|
||||
if self.config.session.cli.progress_bars:
|
||||
with console.status(s.text(), spinner="moon") as status:
|
||||
|
||||
def callback():
|
||||
status.update(s.text())
|
||||
|
||||
for title, artist in titles_artists:
|
||||
requests.append(self._make_query(f"{title} {artist}", s, callback))
|
||||
results: list[tuple[str | None, bool]] = await asyncio.gather(*requests)
|
||||
else:
|
||||
|
||||
def callback():
|
||||
pass
|
||||
|
||||
for title, artist in titles_artists:
|
||||
requests.append(self._make_query(f"{title} {artist}", s, callback))
|
||||
results: list[tuple[str | None, bool]] = await asyncio.gather(*requests)
|
||||
|
||||
parent = self.config.session.downloads.folder
|
||||
folder = os.path.join(parent, clean_filepath(playlist_title))
|
||||
|
||||
pending_tracks = []
|
||||
for pos, (id, from_fallback) in enumerate(results, start=1):
|
||||
if id is None:
|
||||
logger.warning(f"No results found for {titles_artists[pos-1]}")
|
||||
continue
|
||||
|
||||
if from_fallback:
|
||||
assert self.fallback_client is not None
|
||||
client = self.fallback_client
|
||||
else:
|
||||
client = self.client
|
||||
|
||||
pending_tracks.append(
|
||||
PendingPlaylistTrack(
|
||||
id,
|
||||
client,
|
||||
self.config,
|
||||
folder,
|
||||
playlist_title,
|
||||
pos,
|
||||
self.db,
|
||||
),
|
||||
)
|
||||
|
||||
return Playlist(playlist_title, self.config, self.client, pending_tracks)
|
||||
|
||||
async def _make_query(
|
||||
self,
|
||||
query: str,
|
||||
search_status: Status,
|
||||
callback,
|
||||
) -> tuple[str | None, bool]:
|
||||
"""Search for a track with the main source, and use fallback source
|
||||
if that fails.
|
||||
|
||||
Args:
|
||||
----
|
||||
query (str): Query to search
|
||||
s (Status):
|
||||
callback: function to call after each query completes
|
||||
|
||||
Returns: A 2-tuple, where the first element contains the ID if it was found,
|
||||
and the second element is True if the fallback source was used.
|
||||
"""
|
||||
with ExitStack() as stack:
|
||||
# ensure `callback` is always called
|
||||
stack.callback(callback)
|
||||
pages = await self.client.search("track", query, limit=1)
|
||||
if len(pages) > 0:
|
||||
logger.debug(f"Found result for {query} on {self.client.source}")
|
||||
search_status.found += 1
|
||||
return (
|
||||
SearchResults.from_pages(self.client.source, "track", pages)
|
||||
.results[0]
|
||||
.id
|
||||
), False
|
||||
|
||||
if self.fallback_client is None:
|
||||
logger.debug(f"No result found for {query} on {self.client.source}")
|
||||
search_status.failed += 1
|
||||
return None, False
|
||||
|
||||
pages = await self.fallback_client.search("track", query, limit=1)
|
||||
if len(pages) > 0:
|
||||
logger.debug(f"Found result for {query} on {self.client.source}")
|
||||
search_status.found += 1
|
||||
return (
|
||||
SearchResults.from_pages(
|
||||
self.fallback_client.source,
|
||||
"track",
|
||||
pages,
|
||||
)
|
||||
.results[0]
|
||||
.id
|
||||
), True
|
||||
|
||||
logger.debug(f"No result found for {query} on {self.client.source}")
|
||||
search_status.failed += 1
|
||||
return None, True
|
||||
|
||||
async def _parse_lastfm_playlist(
|
||||
self,
|
||||
playlist_url: str,
|
||||
) -> tuple[str, list[tuple[str, str]]]:
|
||||
"""From a last.fm url, return the playlist title, and a list of
|
||||
track titles and artist names.
|
||||
|
||||
Each page contains 50 results, so `num_tracks // 50 + 1` requests
|
||||
are sent per playlist.
|
||||
|
||||
:param url:
|
||||
:type url: str
|
||||
:rtype: tuple[str, list[tuple[str, str]]]
|
||||
"""
|
||||
logger.debug("Fetching lastfm playlist")
|
||||
|
||||
title_tags = re.compile(r'<a\s+href="[^"]+"\s+title="([^"]+)"')
|
||||
re_total_tracks = re.compile(r'data-playlisting-entry-count="(\d+)"')
|
||||
re_playlist_title_match = re.compile(
|
||||
r'<h1 class="playlisting-playlist-header-title">([^<]+)</h1>',
|
||||
)
|
||||
|
||||
def find_title_artist_pairs(page_text):
|
||||
info: list[tuple[str, str]] = []
|
||||
titles = title_tags.findall(page_text) # [2:]
|
||||
for i in range(0, len(titles) - 1, 2):
|
||||
info.append((html.unescape(titles[i]), html.unescape(titles[i + 1])))
|
||||
return info
|
||||
|
||||
async def fetch(session: aiohttp.ClientSession, url, **kwargs):
|
||||
async with session.get(url, **kwargs) as resp:
|
||||
return await resp.text("utf-8")
|
||||
|
||||
# Create new session so we're not bound by rate limit
|
||||
async with aiohttp.ClientSession() as session:
|
||||
page = await fetch(session, playlist_url)
|
||||
playlist_title_match = re_playlist_title_match.search(page)
|
||||
if playlist_title_match is None:
|
||||
raise Exception("Error finding title from response")
|
||||
|
||||
playlist_title: str = html.unescape(playlist_title_match.group(1))
|
||||
|
||||
title_artist_pairs: list[tuple[str, str]] = find_title_artist_pairs(page)
|
||||
|
||||
total_tracks_match = re_total_tracks.search(page)
|
||||
if total_tracks_match is None:
|
||||
raise Exception("Error parsing lastfm page: %s", page)
|
||||
total_tracks = int(total_tracks_match.group(1))
|
||||
|
||||
remaining_tracks = total_tracks - 50 # already got 50 from 1st page
|
||||
if remaining_tracks <= 0:
|
||||
return playlist_title, title_artist_pairs
|
||||
|
||||
last_page = (
|
||||
1 + int(remaining_tracks // 50) + int(remaining_tracks % 50 != 0)
|
||||
)
|
||||
requests = []
|
||||
for page in range(2, last_page + 1):
|
||||
requests.append(fetch(session, playlist_url, params={"page": page}))
|
||||
results = await asyncio.gather(*requests)
|
||||
|
||||
for page in results:
|
||||
title_artist_pairs.extend(find_title_artist_pairs(page))
|
||||
|
||||
return playlist_title, title_artist_pairs
|
||||
|
||||
async def _make_query_mock(
|
||||
self,
|
||||
_: str,
|
||||
s: Status,
|
||||
callback,
|
||||
) -> tuple[str | None, bool]:
|
||||
await asyncio.sleep(random.uniform(1, 20))
|
||||
if random.randint(0, 4) >= 1:
|
||||
s.found += 1
|
||||
else:
|
||||
s.failed += 1
|
||||
callback()
|
||||
return None, False
|
||||
|
|
@ -0,0 +1,40 @@
|
|||
import asyncio
|
||||
from contextlib import nullcontext
|
||||
|
||||
from ..config import DownloadsConfig
|
||||
|
||||
_unlimited = nullcontext()
|
||||
_global_semaphore: None | tuple[int, asyncio.Semaphore] = None
|
||||
|
||||
|
||||
def global_download_semaphore(c: DownloadsConfig) -> asyncio.Semaphore | nullcontext:
|
||||
"""A global semaphore that limit the number of total tracks being downloaded
|
||||
at once.
|
||||
|
||||
If concurrency is disabled in the config, the semaphore is set to 1.
|
||||
Otherwise it's set to `max_connections`.
|
||||
A negative `max_connections` value means there is no maximum and no semaphore is used.
|
||||
|
||||
Since it is global, only one value of `max_connections` is allowed per session.
|
||||
"""
|
||||
global _unlimited, _global_semaphore
|
||||
|
||||
if c.concurrency:
|
||||
max_connections = c.max_connections if c.max_connections > 0 else None
|
||||
else:
|
||||
max_connections = 1
|
||||
|
||||
if max_connections is None:
|
||||
return _unlimited
|
||||
|
||||
if max_connections <= 0:
|
||||
raise Exception(f"{max_connections = } too small")
|
||||
|
||||
if _global_semaphore is None:
|
||||
_global_semaphore = (max_connections, asyncio.Semaphore(max_connections))
|
||||
|
||||
assert (
|
||||
max_connections == _global_semaphore[0]
|
||||
), f"Already have other global semaphore {_global_semaphore}"
|
||||
|
||||
return _global_semaphore[1]
|
||||
|
|
@ -0,0 +1,262 @@
|
|||
import asyncio
|
||||
import logging
|
||||
import os
|
||||
from dataclasses import dataclass
|
||||
|
||||
from .. import converter
|
||||
from ..client import Client, Downloadable
|
||||
from ..config import Config
|
||||
from ..db import Database
|
||||
from ..exceptions import NonStreamableError
|
||||
from ..filepath_utils import clean_filename
|
||||
from ..metadata import AlbumMetadata, Covers, TrackMetadata, tag_file
|
||||
from ..progress import add_title, get_progress_callback, remove_title
|
||||
from .artwork import download_artwork
|
||||
from .media import Media, Pending
|
||||
from .semaphore import global_download_semaphore
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class Track(Media):
|
||||
meta: TrackMetadata
|
||||
downloadable: Downloadable
|
||||
config: Config
|
||||
folder: str
|
||||
# Is None if a cover doesn't exist for the track
|
||||
cover_path: str | None
|
||||
db: Database
|
||||
# change?
|
||||
download_path: str = ""
|
||||
is_single: bool = False
|
||||
|
||||
async def preprocess(self):
|
||||
self._set_download_path()
|
||||
os.makedirs(self.folder, exist_ok=True)
|
||||
if self.is_single:
|
||||
add_title(self.meta.title)
|
||||
|
||||
async def download(self):
|
||||
# TODO: progress bar description
|
||||
async with global_download_semaphore(self.config.session.downloads):
|
||||
with get_progress_callback(
|
||||
self.config.session.cli.progress_bars,
|
||||
await self.downloadable.size(),
|
||||
f"Track {self.meta.tracknumber}",
|
||||
) as callback:
|
||||
try:
|
||||
await self.downloadable.download(self.download_path, callback)
|
||||
retry = False
|
||||
except Exception as e:
|
||||
logger.error(
|
||||
f"Error downloading track '{self.meta.title}', retrying: {e}"
|
||||
)
|
||||
retry = True
|
||||
|
||||
if not retry:
|
||||
return
|
||||
|
||||
with get_progress_callback(
|
||||
self.config.session.cli.progress_bars,
|
||||
await self.downloadable.size(),
|
||||
f"Track {self.meta.tracknumber} (retry)",
|
||||
) as callback:
|
||||
try:
|
||||
await self.downloadable.download(self.download_path, callback)
|
||||
except Exception as e:
|
||||
logger.error(
|
||||
f"Persistent error downloading track '{self.meta.title}', skipping: {e}"
|
||||
)
|
||||
self.db.set_failed(
|
||||
self.downloadable.source, "track", self.meta.info.id
|
||||
)
|
||||
|
||||
async def postprocess(self):
|
||||
if self.is_single:
|
||||
remove_title(self.meta.title)
|
||||
|
||||
await tag_file(self.download_path, self.meta, self.cover_path)
|
||||
if self.config.session.conversion.enabled:
|
||||
await self._convert()
|
||||
|
||||
self.db.set_downloaded(self.meta.info.id)
|
||||
|
||||
async def _convert(self):
|
||||
c = self.config.session.conversion
|
||||
engine_class = converter.get(c.codec)
|
||||
engine = engine_class(
|
||||
filename=self.download_path,
|
||||
sampling_rate=c.sampling_rate,
|
||||
bit_depth=c.bit_depth,
|
||||
remove_source=True, # always going to delete the old file
|
||||
)
|
||||
await engine.convert()
|
||||
self.download_path = engine.final_fn # because the extension changed
|
||||
|
||||
def _set_download_path(self):
|
||||
c = self.config.session.filepaths
|
||||
formatter = c.track_format
|
||||
track_path = clean_filename(
|
||||
self.meta.format_track_path(formatter),
|
||||
restrict=c.restrict_characters,
|
||||
)
|
||||
if c.truncate_to > 0 and len(track_path) > c.truncate_to:
|
||||
track_path = track_path[: c.truncate_to]
|
||||
|
||||
self.download_path = os.path.join(
|
||||
self.folder,
|
||||
f"{track_path}.{self.downloadable.extension}",
|
||||
)
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class PendingTrack(Pending):
|
||||
id: str
|
||||
album: AlbumMetadata
|
||||
client: Client
|
||||
config: Config
|
||||
folder: str
|
||||
db: Database
|
||||
# cover_path is None <==> Artwork for this track doesn't exist in API
|
||||
cover_path: str | None
|
||||
|
||||
async def resolve(self) -> Track | None:
|
||||
if self.db.downloaded(self.id):
|
||||
logger.info(
|
||||
f"Skipping track {self.id}. Marked as downloaded in the database.",
|
||||
)
|
||||
return None
|
||||
|
||||
source = self.client.source
|
||||
try:
|
||||
resp = await self.client.get_metadata(self.id, "track")
|
||||
except NonStreamableError as e:
|
||||
logger.error(f"Track {self.id} not available for stream on {source}: {e}")
|
||||
return None
|
||||
|
||||
try:
|
||||
meta = TrackMetadata.from_resp(self.album, source, resp)
|
||||
except Exception as e:
|
||||
logger.error(f"Error building track metadata for {id=}: {e}")
|
||||
return None
|
||||
|
||||
if meta is None:
|
||||
logger.error(f"Track {self.id} not available for stream on {source}")
|
||||
self.db.set_failed(source, "track", self.id)
|
||||
return None
|
||||
|
||||
quality = self.config.session.get_source(source).quality
|
||||
downloadable = await self.client.get_downloadable(self.id, quality)
|
||||
|
||||
downloads_config = self.config.session.downloads
|
||||
if downloads_config.disc_subdirectories and self.album.disctotal > 1:
|
||||
folder = os.path.join(self.folder, f"Disc {meta.discnumber}")
|
||||
else:
|
||||
folder = self.folder
|
||||
|
||||
return Track(
|
||||
meta,
|
||||
downloadable,
|
||||
self.config,
|
||||
folder,
|
||||
self.cover_path,
|
||||
self.db,
|
||||
)
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class PendingSingle(Pending):
|
||||
"""Whereas PendingTrack is used in the context of an album, where the album metadata
|
||||
and cover have been resolved, PendingSingle is used when a single track is downloaded.
|
||||
|
||||
This resolves the Album metadata and downloads the cover to pass to the Track class.
|
||||
"""
|
||||
|
||||
id: str
|
||||
client: Client
|
||||
config: Config
|
||||
db: Database
|
||||
|
||||
async def resolve(self) -> Track | None:
|
||||
if self.db.downloaded(self.id):
|
||||
logger.info(
|
||||
f"Skipping track {self.id}. Marked as downloaded in the database.",
|
||||
)
|
||||
return None
|
||||
|
||||
try:
|
||||
resp = await self.client.get_metadata(self.id, "track")
|
||||
except NonStreamableError as e:
|
||||
logger.error(f"Error fetching track {self.id}: {e}")
|
||||
return None
|
||||
# Patch for soundcloud
|
||||
try:
|
||||
album = AlbumMetadata.from_track_resp(resp, self.client.source)
|
||||
except Exception as e:
|
||||
logger.error(f"Error building album metadata for track {id=}: {e}")
|
||||
return None
|
||||
|
||||
if album is None:
|
||||
self.db.set_failed(self.client.source, "track", self.id)
|
||||
logger.error(
|
||||
f"Cannot stream track (am) ({self.id}) on {self.client.source}",
|
||||
)
|
||||
return None
|
||||
|
||||
try:
|
||||
meta = TrackMetadata.from_resp(album, self.client.source, resp)
|
||||
except Exception as e:
|
||||
logger.error(f"Error building track metadata for track {id=}: {e}")
|
||||
return None
|
||||
|
||||
if meta is None:
|
||||
self.db.set_failed(self.client.source, "track", self.id)
|
||||
logger.error(
|
||||
f"Cannot stream track (tm) ({self.id}) on {self.client.source}",
|
||||
)
|
||||
return None
|
||||
|
||||
config = self.config.session
|
||||
quality = getattr(config, self.client.source).quality
|
||||
assert isinstance(quality, int)
|
||||
parent = config.downloads.folder
|
||||
if config.filepaths.add_singles_to_folder:
|
||||
folder = os.path.join(parent, self._format_folder(album))
|
||||
else:
|
||||
folder = parent
|
||||
|
||||
os.makedirs(folder, exist_ok=True)
|
||||
|
||||
embedded_cover_path, downloadable = await asyncio.gather(
|
||||
self._download_cover(album.covers, folder),
|
||||
self.client.get_downloadable(self.id, quality),
|
||||
)
|
||||
return Track(
|
||||
meta,
|
||||
downloadable,
|
||||
self.config,
|
||||
folder,
|
||||
embedded_cover_path,
|
||||
self.db,
|
||||
is_single=True,
|
||||
)
|
||||
|
||||
def _format_folder(self, meta: AlbumMetadata) -> str:
|
||||
c = self.config.session
|
||||
parent = c.downloads.folder
|
||||
formatter = c.filepaths.folder_format
|
||||
if c.downloads.source_subdirectories:
|
||||
parent = os.path.join(parent, self.client.source.capitalize())
|
||||
|
||||
return os.path.join(parent, meta.format_folder_path(formatter))
|
||||
|
||||
async def _download_cover(self, covers: Covers, folder: str) -> str | None:
|
||||
embed_path, _ = await download_artwork(
|
||||
self.client.session,
|
||||
folder,
|
||||
covers,
|
||||
self.config.session.artwork,
|
||||
for_playlist=False,
|
||||
)
|
||||
return embed_path
|
||||
|
|
@ -1,634 +0,0 @@
|
|||
"""Manages the information that will be embeded in the audio file."""
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import logging
|
||||
import re
|
||||
from collections import OrderedDict
|
||||
from typing import Generator, Hashable, Iterable, Optional, Union
|
||||
|
||||
from .constants import (
|
||||
ALBUM_KEYS,
|
||||
COPYRIGHT,
|
||||
FLAC_KEY,
|
||||
MP3_KEY,
|
||||
MP4_KEY,
|
||||
PHON_COPYRIGHT,
|
||||
TIDAL_Q_MAP,
|
||||
TRACK_KEYS,
|
||||
)
|
||||
from .exceptions import InvalidContainerError, InvalidSourceError
|
||||
from .utils import get_cover_urls, get_quality_id, safe_get
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
|
||||
class TrackMetadata:
|
||||
"""Contains all of the metadata needed to tag the file.
|
||||
|
||||
Tags contained:
|
||||
* title
|
||||
* artist
|
||||
* album
|
||||
* albumartist
|
||||
* composer
|
||||
* year
|
||||
* comment
|
||||
* description
|
||||
* purchase_date
|
||||
* grouping
|
||||
* genre
|
||||
* lyrics
|
||||
* encoder
|
||||
* copyright
|
||||
* compilation
|
||||
* cover
|
||||
* tracknumber
|
||||
* discnumber
|
||||
* tracktotal
|
||||
* disctotal
|
||||
"""
|
||||
|
||||
albumartist: str
|
||||
composer: Optional[str] = None
|
||||
albumcomposer: Optional[str] = None
|
||||
comment: Optional[str] = None
|
||||
description: Optional[str] = None
|
||||
purchase_date: Optional[str] = None
|
||||
date: Optional[str] = None
|
||||
grouping: Optional[str] = None
|
||||
lyrics: Optional[str] = None
|
||||
encoder: Optional[str] = None
|
||||
compilation: Optional[str] = None
|
||||
cover: Optional[str] = None
|
||||
tracktotal: Optional[int] = None
|
||||
tracknumber: Optional[int] = None
|
||||
discnumber: Optional[int] = None
|
||||
disctotal: Optional[int] = None
|
||||
|
||||
# not included in tags
|
||||
explicit: bool = False
|
||||
quality: Optional[int] = None
|
||||
sampling_rate: Optional[int] = None
|
||||
bit_depth: Optional[int] = None
|
||||
booklets = None
|
||||
cover_urls = Optional[OrderedDict]
|
||||
work: Optional[str]
|
||||
id: Optional[str]
|
||||
|
||||
# Internals
|
||||
_artist: Optional[str] = None
|
||||
_copyright: Optional[str] = None
|
||||
_genres: Optional[Iterable] = None
|
||||
_title: Optional[str]
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
track: Optional[Union[TrackMetadata, dict]] = None,
|
||||
album: Optional[Union[TrackMetadata, dict]] = None,
|
||||
source="qobuz",
|
||||
):
|
||||
"""Create a TrackMetadata object.
|
||||
|
||||
:param track: track dict from API
|
||||
:type track: Optional[dict]
|
||||
:param album: album dict from API
|
||||
:type album: Optional[dict]
|
||||
"""
|
||||
# embedded information
|
||||
# TODO: add this to static attrs
|
||||
self.__source = source
|
||||
|
||||
if isinstance(track, TrackMetadata):
|
||||
self.update(track)
|
||||
elif track is not None:
|
||||
self.add_track_meta(track)
|
||||
|
||||
if isinstance(album, TrackMetadata):
|
||||
self.update(album)
|
||||
elif album is not None:
|
||||
self.add_album_meta(album)
|
||||
|
||||
def update(self, meta: TrackMetadata):
|
||||
"""Update the attributes from another TrackMetadata object.
|
||||
|
||||
:param meta:
|
||||
:type meta: TrackMetadata
|
||||
"""
|
||||
assert isinstance(meta, TrackMetadata)
|
||||
|
||||
for k, v in meta.asdict().items():
|
||||
if v is not None:
|
||||
setattr(self, k, v)
|
||||
|
||||
def add_album_meta(self, resp: dict):
|
||||
"""Parse the metadata from an resp dict returned by the API.
|
||||
|
||||
:param dict resp: from API
|
||||
"""
|
||||
if self.__source == "qobuz":
|
||||
# Tags
|
||||
self.album = resp.get("title", "Unknown Album")
|
||||
self.tracktotal = resp.get("tracks_count", 1)
|
||||
self.genre = resp.get("genres_list") or resp.get("genre") or []
|
||||
self.date = resp.get("release_date_original") or resp.get("release_date")
|
||||
self.copyright = resp.get("copyright")
|
||||
|
||||
if artists := resp.get("artists"):
|
||||
self.albumartist = ", ".join(a["name"] for a in artists)
|
||||
else:
|
||||
self.albumartist = safe_get(resp, "artist", "name")
|
||||
|
||||
self.albumcomposer = safe_get(resp, "composer", "name")
|
||||
self.label = resp.get("label")
|
||||
self.description = resp.get("description")
|
||||
self.disctotal = (
|
||||
max(
|
||||
track.get("media_number", 1)
|
||||
for track in safe_get(resp, "tracks", "items", default=[{}])
|
||||
)
|
||||
or 1
|
||||
)
|
||||
self.explicit = resp.get("parental_warning", False)
|
||||
|
||||
if isinstance(self.label, dict):
|
||||
self.label = self.label.get("name")
|
||||
|
||||
# Non-embedded information
|
||||
self.version = resp.get("version")
|
||||
self.cover_urls = get_cover_urls(resp, self.__source)
|
||||
self.streamable = resp.get("streamable", False)
|
||||
self.bit_depth = resp.get("maximum_bit_depth")
|
||||
self.sampling_rate = resp.get("maximum_sampling_rate")
|
||||
self.quality = get_quality_id(self.bit_depth, self.sampling_rate)
|
||||
self.booklets = resp.get("goodies")
|
||||
self.id = resp.get("id")
|
||||
|
||||
if self.sampling_rate is not None:
|
||||
self.sampling_rate *= 1000
|
||||
|
||||
elif self.__source == "tidal":
|
||||
self.album = resp.get("title", "Unknown Album")
|
||||
self.tracktotal = resp.get("numberOfTracks", 1)
|
||||
# genre not returned by API
|
||||
self.date = resp.get("releaseDate")
|
||||
|
||||
self.copyright = resp.get("copyright")
|
||||
|
||||
if artists := resp.get("artists"):
|
||||
self.albumartist = ", ".join(a["name"] for a in artists)
|
||||
else:
|
||||
self.albumartist = safe_get(resp, "artist", "name")
|
||||
|
||||
self.disctotal = resp.get("numberOfVolumes", 1)
|
||||
self.isrc = resp.get("isrc")
|
||||
# label not returned by API
|
||||
|
||||
# non-embedded
|
||||
self.explicit = resp.get("explicit", False)
|
||||
# 80, 160, 320, 640, 1280
|
||||
self.cover_urls = get_cover_urls(resp, self.__source)
|
||||
self.streamable = resp.get("allowStreaming", False)
|
||||
self.id = resp.get("id")
|
||||
|
||||
if q := resp.get("audioQuality"): # for album entries in single tracks
|
||||
self._get_tidal_quality(q)
|
||||
|
||||
elif self.__source == "deezer":
|
||||
self.album = resp.get("title", "Unknown Album")
|
||||
self.tracktotal = resp.get("track_total", 0) or resp.get("nb_tracks", 0)
|
||||
self.disctotal = (
|
||||
max(track.get("disk_number") for track in resp.get("tracks", [{}])) or 1
|
||||
)
|
||||
self.genre = safe_get(resp, "genres", "data")
|
||||
self.date = resp.get("release_date")
|
||||
self.albumartist = safe_get(resp, "artist", "name")
|
||||
self.label = resp.get("label")
|
||||
self.url = resp.get("link")
|
||||
self.explicit = resp.get("parental_warning", False)
|
||||
|
||||
# not embedded
|
||||
self.quality = 2
|
||||
self.bit_depth = 16
|
||||
self.sampling_rate = 44100
|
||||
|
||||
self.cover_urls = get_cover_urls(resp, self.__source)
|
||||
self.streamable = True
|
||||
self.id = resp.get("id")
|
||||
|
||||
elif self.__source == "soundcloud":
|
||||
raise NotImplementedError
|
||||
else:
|
||||
raise InvalidSourceError(self.__source)
|
||||
|
||||
def add_track_meta(self, track: dict):
|
||||
"""Parse the metadata from a track dict returned by an API.
|
||||
|
||||
:param track:
|
||||
"""
|
||||
if self.__source == "qobuz":
|
||||
self.title = track["title"].strip()
|
||||
self._mod_title(track.get("version"), track.get("work"))
|
||||
self.composer = track.get("composer", {}).get("name")
|
||||
|
||||
self.tracknumber = track.get("track_number", 1)
|
||||
self.discnumber = track.get("media_number", 1)
|
||||
self.artist = safe_get(track, "performer", "name")
|
||||
|
||||
elif self.__source == "tidal":
|
||||
self.title = track["title"].strip()
|
||||
self._mod_title(track.get("version"), None)
|
||||
self.tracknumber = track.get("trackNumber", 1)
|
||||
self.discnumber = track.get("volumeNumber", 1)
|
||||
self.artist = track.get("artist", {}).get("name")
|
||||
self._get_tidal_quality(track["audioQuality"])
|
||||
|
||||
elif self.__source == "deezer":
|
||||
self.title = track["title"].strip()
|
||||
self._mod_title(track.get("version"), None)
|
||||
self.tracknumber = track.get("track_position", 1)
|
||||
self.discnumber = track.get("disk_number", 1)
|
||||
self.artist = safe_get(track, "artist", "name")
|
||||
|
||||
elif self.__source == "soundcloud":
|
||||
self.title = track["title"].strip()
|
||||
self.genre = track["genre"]
|
||||
self.artist = self.albumartist = track["user"]["username"]
|
||||
self.year = track["created_at"][:4]
|
||||
self.label = track["label_name"]
|
||||
self.description = track["description"]
|
||||
self.album = safe_get(track, "publisher_metadata", "album_title")
|
||||
self.copyright = safe_get(track, "publisher_metadata", "p_line")
|
||||
self.tracknumber = 0
|
||||
self.tracktotal = 0
|
||||
self.quality = 0
|
||||
self.cover_urls = get_cover_urls(track, "soundcloud")
|
||||
|
||||
else:
|
||||
raise ValueError(self.__source)
|
||||
|
||||
if track.get("album"):
|
||||
self.add_album_meta(track["album"])
|
||||
|
||||
def _mod_title(self, version: Optional[str], work: Optional[str]):
|
||||
"""Modify title using the version and work.
|
||||
|
||||
:param version:
|
||||
:type version: str
|
||||
:param work:
|
||||
:type work: str
|
||||
"""
|
||||
if version is not None and version not in self.title:
|
||||
self.title = f"{self.title} ({version})"
|
||||
if work is not None and work not in self.title:
|
||||
logger.debug("Work found: %s", work)
|
||||
self.title = f"{work}: {self.title}"
|
||||
|
||||
def _get_tidal_quality(self, q: str):
|
||||
self.quality = TIDAL_Q_MAP[q]
|
||||
if self.quality >= 2:
|
||||
self.bit_depth = 24 if self.get("quality") == 3 else 16
|
||||
self.sampling_rate = 44100
|
||||
|
||||
@property
|
||||
def title(self) -> Optional[str]:
|
||||
if not hasattr(self, "_title"):
|
||||
return None
|
||||
|
||||
# if self.explicit:
|
||||
# return f"{self._title} (Explicit)"
|
||||
|
||||
return self._title
|
||||
|
||||
@title.setter
|
||||
def title(self, new_title):
|
||||
self._title = new_title
|
||||
|
||||
@property
|
||||
def album(self) -> str:
|
||||
"""Return the album of the track.
|
||||
|
||||
:rtype: str
|
||||
"""
|
||||
assert hasattr(self, "_album"), "Must set album before accessing"
|
||||
|
||||
album = self._album
|
||||
|
||||
if self.get("version") and self["version"] not in album:
|
||||
album = f"{self._album} ({self.version})"
|
||||
|
||||
if self.get("work") and self["work"] not in album:
|
||||
album = f"{self.work}: {album}"
|
||||
|
||||
return album
|
||||
|
||||
@album.setter
|
||||
def album(self, val):
|
||||
"""Set the value of the album.
|
||||
|
||||
:param val:
|
||||
"""
|
||||
self._album = val
|
||||
|
||||
@property
|
||||
def artist(self) -> Optional[str]:
|
||||
"""Return the value to set for the artist tag.
|
||||
|
||||
Defaults to `self.albumartist` if there is no track artist.
|
||||
|
||||
:rtype: str
|
||||
"""
|
||||
if self._artist is not None:
|
||||
return self._artist
|
||||
|
||||
return None
|
||||
|
||||
@artist.setter
|
||||
def artist(self, val: str):
|
||||
"""Set the internal artist variable to val.
|
||||
|
||||
:param val:
|
||||
:type val: str
|
||||
"""
|
||||
self._artist = val
|
||||
|
||||
@property
|
||||
def genre(self) -> Optional[str]:
|
||||
"""Format the genre list returned by an API.
|
||||
|
||||
It cleans up the Qobuz Response:
|
||||
>>> meta.genre = ['Pop/Rock', 'Pop/Rock→Rock', 'Pop/Rock→Rock→Alternatif et Indé']
|
||||
>>> meta.genre
|
||||
'Pop, Rock, Alternatif et Indé'
|
||||
|
||||
:rtype: str
|
||||
"""
|
||||
if not self.get("_genres"):
|
||||
return None
|
||||
|
||||
if isinstance(self._genres, dict):
|
||||
self._genres = self._genres["name"]
|
||||
|
||||
if isinstance(self._genres, list):
|
||||
if self.__source == "qobuz":
|
||||
genres: Iterable = re.findall(r"([^\u2192\/]+)", "/".join(self._genres))
|
||||
genres = set(genres)
|
||||
elif self.__source == "deezer":
|
||||
genres = (g["name"] for g in self._genres)
|
||||
else:
|
||||
raise Exception
|
||||
|
||||
return ", ".join(genres)
|
||||
|
||||
elif isinstance(self._genres, str):
|
||||
return self._genres
|
||||
|
||||
raise TypeError(f"Genre must be list or str, not {type(self._genres)}")
|
||||
|
||||
@genre.setter
|
||||
def genre(self, val: Union[Iterable, dict]):
|
||||
"""Set the internal `genre` field to the given list.
|
||||
|
||||
It is not formatted until it is requested with `meta.genre`.
|
||||
|
||||
:param val:
|
||||
:type val: Union[str, list]
|
||||
"""
|
||||
self._genres = val
|
||||
|
||||
@property
|
||||
def copyright(self) -> Optional[str]:
|
||||
"""Format the copyright string to use unicode characters.
|
||||
|
||||
:rtype: str, None
|
||||
"""
|
||||
if hasattr(self, "_copyright"):
|
||||
if self._copyright is None:
|
||||
return None
|
||||
copyright: str = re.sub(r"(?i)\(P\)", PHON_COPYRIGHT, self._copyright)
|
||||
copyright = re.sub(r"(?i)\(C\)", COPYRIGHT, copyright)
|
||||
return copyright
|
||||
|
||||
logger.debug("Accessed copyright tag before setting, returning None")
|
||||
return None
|
||||
|
||||
@copyright.setter
|
||||
def copyright(self, val: Optional[str]):
|
||||
"""Set the internal copyright variable to the given value.
|
||||
|
||||
Only formatted when requested.
|
||||
|
||||
:param val:
|
||||
:type val: str
|
||||
"""
|
||||
self._copyright = val
|
||||
|
||||
@property
|
||||
def year(self) -> Optional[str]:
|
||||
"""Return the year published of the track.
|
||||
|
||||
:rtype: str
|
||||
"""
|
||||
if hasattr(self, "_year"):
|
||||
return self._year
|
||||
|
||||
if hasattr(self, "date") and isinstance(self.date, str):
|
||||
return self.date[:4]
|
||||
|
||||
return None
|
||||
|
||||
@year.setter
|
||||
def year(self, val):
|
||||
"""Set the internal year variable to val.
|
||||
|
||||
:param val:
|
||||
"""
|
||||
self._year = val
|
||||
|
||||
def get_formatter(self, max_quality: int) -> dict:
|
||||
"""Return a dict that is used to apply values to file format strings.
|
||||
|
||||
:rtype: dict
|
||||
"""
|
||||
# the keys in the tuple are the possible keys for format strings
|
||||
return {k: getattr(self, k) for k in TRACK_KEYS}
|
||||
|
||||
def get_album_formatter(self, max_quality: int) -> dict:
|
||||
"""Return a dict that is used to apply values to file format strings.
|
||||
|
||||
:param max_quality:
|
||||
:type max_quality: int
|
||||
:rtype: dict
|
||||
"""
|
||||
formatter = {k: self.get(k) for k in ALBUM_KEYS}
|
||||
formatter["container"] = "FLAC" if max_quality >= 2 else "MP3"
|
||||
formatter["sampling_rate"] /= 1000
|
||||
return formatter
|
||||
|
||||
def tags(self, container: str = "flac", exclude: Optional[set] = None) -> Generator:
|
||||
"""Create a generator of key, value pairs for use with mutagen.
|
||||
|
||||
The *_KEY dicts are organized in the format:
|
||||
|
||||
>>> {attribute_name: key_to_use_for_metadata}
|
||||
|
||||
They are then converted to the format
|
||||
|
||||
>>> {key_to_use_for_metadata: value_of_attribute}
|
||||
|
||||
so that they can be used like this:
|
||||
|
||||
>>> audio = MP4(path)
|
||||
>>> for k, v in meta.tags(container='MP4'):
|
||||
... audio[k] = v
|
||||
>>> audio.save()
|
||||
|
||||
:param container: the container format
|
||||
:type container: str
|
||||
:rtype: Generator
|
||||
"""
|
||||
if exclude is None:
|
||||
exclude = set()
|
||||
logger.debug("Excluded tags: %s", exclude)
|
||||
|
||||
container = container.lower()
|
||||
if container in ("flac", "vorbis"):
|
||||
return self.__gen_flac_tags(exclude)
|
||||
if container in ("mp3", "id3"):
|
||||
return self.__gen_mp3_tags(exclude)
|
||||
if container in ("alac", "m4a", "mp4", "aac"):
|
||||
return self.__gen_mp4_tags(exclude)
|
||||
|
||||
raise InvalidContainerError(f"Invalid container {container}")
|
||||
|
||||
def __gen_flac_tags(self, exclude: set) -> Generator:
|
||||
"""Generate key, value pairs to tag FLAC files.
|
||||
|
||||
:rtype: Tuple[str, str]
|
||||
"""
|
||||
for k, v in FLAC_KEY.items():
|
||||
logger.debug("attr: %s", k)
|
||||
if k in exclude:
|
||||
continue
|
||||
|
||||
tag = getattr(self, k)
|
||||
if tag:
|
||||
if k in {
|
||||
"tracknumber",
|
||||
"discnumber",
|
||||
"tracktotal",
|
||||
"disctotal",
|
||||
}:
|
||||
tag = f"{int(tag):02}"
|
||||
|
||||
logger.debug("Adding tag %s: %s", v, tag)
|
||||
yield (v, str(tag))
|
||||
|
||||
def __gen_mp3_tags(self, exclude: set) -> Generator:
|
||||
"""Generate key, value pairs to tag MP3 files.
|
||||
|
||||
:rtype: Tuple[str, str]
|
||||
"""
|
||||
for k, v in MP3_KEY.items():
|
||||
if k in exclude:
|
||||
continue
|
||||
|
||||
if k == "tracknumber":
|
||||
text = f"{self.tracknumber}/{self.tracktotal}"
|
||||
elif k == "discnumber":
|
||||
text = f"{self.discnumber}/{self.get('disctotal', 1)}"
|
||||
else:
|
||||
text = getattr(self, k)
|
||||
|
||||
if text is not None and v is not None:
|
||||
yield (v.__name__, v(encoding=3, text=text))
|
||||
|
||||
def __gen_mp4_tags(self, exclude: set) -> Generator:
|
||||
"""Generate key, value pairs to tag ALAC or AAC files.
|
||||
|
||||
:rtype: Tuple[str, str]
|
||||
"""
|
||||
for k, v in MP4_KEY.items():
|
||||
if k in exclude:
|
||||
continue
|
||||
|
||||
if k == "tracknumber":
|
||||
text = [(self.tracknumber, self.tracktotal)]
|
||||
elif k == "discnumber":
|
||||
text = [(self.discnumber, self.get("disctotal", 1))]
|
||||
else:
|
||||
text = getattr(self, k)
|
||||
|
||||
if v is not None and text is not None:
|
||||
yield (v, text)
|
||||
|
||||
def asdict(self) -> dict:
|
||||
"""Return a dict representation of self.
|
||||
|
||||
:rtype: dict
|
||||
"""
|
||||
ret = {}
|
||||
for attr in dir(self):
|
||||
if not attr.startswith("_") and not callable(getattr(self, attr)):
|
||||
ret[attr] = getattr(self, attr)
|
||||
|
||||
return ret
|
||||
|
||||
def __setitem__(self, key, val):
|
||||
"""Dict-like access for tags.
|
||||
|
||||
:param key:
|
||||
:param val:
|
||||
"""
|
||||
setattr(self, key, val)
|
||||
|
||||
def __getitem__(self, key):
|
||||
"""Dict-like access for tags.
|
||||
|
||||
:param key:
|
||||
"""
|
||||
return getattr(self, key)
|
||||
|
||||
def get(self, key, default=None):
|
||||
"""Return the requested attribute of the object, with a default value.
|
||||
|
||||
:param key:
|
||||
:param default:
|
||||
"""
|
||||
if hasattr(self, key):
|
||||
res = self.__getitem__(key)
|
||||
if res is not None:
|
||||
return res
|
||||
|
||||
return default
|
||||
|
||||
return default
|
||||
|
||||
def set(self, key, val) -> str:
|
||||
"""Set an attribute.
|
||||
|
||||
Equivalent to:
|
||||
>>> meta[key] = val
|
||||
|
||||
:param key:
|
||||
:param val:
|
||||
:rtype: str
|
||||
"""
|
||||
return self.__setitem__(key, val)
|
||||
|
||||
def __hash__(self) -> int:
|
||||
"""Get a hash of this.
|
||||
|
||||
Warning: slow.
|
||||
|
||||
:rtype: int
|
||||
"""
|
||||
return sum(hash(v) for v in self.asdict().values() if isinstance(v, Hashable))
|
||||
|
||||
def __repr__(self) -> str:
|
||||
"""Return the string representation of the metadata object.
|
||||
|
||||
:rtype: str
|
||||
"""
|
||||
# TODO: make a more readable repr
|
||||
return f"<TrackMetadata object {hex(hash(self))}>"
|
||||
|
|
@ -0,0 +1,39 @@
|
|||
"""Manages the information that will be embeded in the audio file."""
|
||||
|
||||
from . import util
|
||||
from .album import AlbumInfo, AlbumMetadata
|
||||
from .artist import ArtistMetadata
|
||||
from .covers import Covers
|
||||
from .label import LabelMetadata
|
||||
from .playlist import PlaylistMetadata
|
||||
from .search_results import (
|
||||
AlbumSummary,
|
||||
ArtistSummary,
|
||||
LabelSummary,
|
||||
PlaylistSummary,
|
||||
SearchResults,
|
||||
Summary,
|
||||
TrackSummary,
|
||||
)
|
||||
from .tagger import tag_file
|
||||
from .track import TrackInfo, TrackMetadata
|
||||
|
||||
__all__ = [
|
||||
"AlbumMetadata",
|
||||
"ArtistMetadata",
|
||||
"AlbumInfo",
|
||||
"TrackInfo",
|
||||
"LabelMetadata",
|
||||
"TrackMetadata",
|
||||
"PlaylistMetadata",
|
||||
"Covers",
|
||||
"tag_file",
|
||||
"util",
|
||||
"AlbumSummary",
|
||||
"ArtistSummary",
|
||||
"LabelSummary",
|
||||
"PlaylistSummary",
|
||||
"Summary",
|
||||
"TrackSummary",
|
||||
"SearchResults",
|
||||
]
|
||||
|
|
@ -0,0 +1,520 @@
|
|||
from __future__ import annotations
|
||||
|
||||
import logging
|
||||
import re
|
||||
from dataclasses import dataclass
|
||||
from typing import Optional
|
||||
|
||||
from ..filepath_utils import clean_filename
|
||||
from .covers import Covers
|
||||
from .util import get_quality_id, safe_get, typed
|
||||
|
||||
PHON_COPYRIGHT = "\u2117"
|
||||
COPYRIGHT = "\u00a9"
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
|
||||
genre_clean = re.compile(r"([^\u2192\/]+)")
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class AlbumInfo:
|
||||
id: str
|
||||
quality: int
|
||||
container: str
|
||||
label: Optional[str] = None
|
||||
explicit: bool = False
|
||||
sampling_rate: int | float | None = None
|
||||
bit_depth: int | None = None
|
||||
booklets: list[dict] | None = None
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class AlbumMetadata:
|
||||
info: AlbumInfo
|
||||
album: str
|
||||
albumartist: str
|
||||
year: str
|
||||
genre: list[str]
|
||||
covers: Covers
|
||||
tracktotal: int
|
||||
disctotal: int = 1
|
||||
albumcomposer: str | None = None
|
||||
comment: str | None = None
|
||||
compilation: str | None = None
|
||||
copyright: str | None = None
|
||||
date: str | None = None
|
||||
description: str | None = None
|
||||
encoder: str | None = None
|
||||
grouping: str | None = None
|
||||
lyrics: str | None = None
|
||||
purchase_date: str | None = None
|
||||
|
||||
def get_genres(self) -> str:
|
||||
return ", ".join(self.genre)
|
||||
|
||||
def get_copyright(self) -> str | None:
|
||||
if self.copyright is None:
|
||||
return None
|
||||
# Add special chars
|
||||
_copyright = re.sub(r"(?i)\(P\)", PHON_COPYRIGHT, self.copyright)
|
||||
_copyright = re.sub(r"(?i)\(C\)", COPYRIGHT, _copyright)
|
||||
return _copyright
|
||||
|
||||
def format_folder_path(self, formatter: str) -> str:
|
||||
# Available keys: "albumartist", "title", "year", "bit_depth", "sampling_rate",
|
||||
# "id", and "albumcomposer",
|
||||
|
||||
none_str = "Unknown"
|
||||
info: dict[str, str | int | float] = {
|
||||
"albumartist": clean_filename(self.albumartist),
|
||||
"albumcomposer": clean_filename(self.albumcomposer or "") or none_str,
|
||||
"bit_depth": self.info.bit_depth or none_str,
|
||||
"id": self.info.id,
|
||||
"sampling_rate": self.info.sampling_rate or none_str,
|
||||
"title": clean_filename(self.album),
|
||||
"year": self.year,
|
||||
"container": self.info.container,
|
||||
}
|
||||
|
||||
return formatter.format(**info)
|
||||
|
||||
@classmethod
|
||||
def from_qobuz(cls, resp: dict) -> AlbumMetadata:
|
||||
album = resp.get("title", "Unknown Album")
|
||||
tracktotal = resp.get("tracks_count", 1)
|
||||
genre = resp.get("genres_list") or resp.get("genre") or []
|
||||
genres = list(set(genre_clean.findall("/".join(genre))))
|
||||
date = resp.get("release_date_original") or resp.get("release_date")
|
||||
year = date[:4] if date is not None else "Unknown"
|
||||
|
||||
_copyright = resp.get("copyright", "")
|
||||
|
||||
if artists := resp.get("artists"):
|
||||
albumartist = ", ".join(a["name"] for a in artists)
|
||||
else:
|
||||
albumartist = typed(safe_get(resp, "artist", "name"), str)
|
||||
|
||||
albumcomposer = typed(safe_get(resp, "composer", "name", default=""), str)
|
||||
_label = resp.get("label")
|
||||
if isinstance(_label, dict):
|
||||
_label = _label["name"]
|
||||
label = typed(_label or "", str)
|
||||
description = typed(resp.get("description", ""), str)
|
||||
disctotal = typed(
|
||||
max(
|
||||
track.get("media_number", 1)
|
||||
for track in safe_get(resp, "tracks", "items", default=[{}]) # type: ignore
|
||||
)
|
||||
or 1,
|
||||
int,
|
||||
)
|
||||
explicit = typed(resp.get("parental_warning", False), bool)
|
||||
|
||||
# Non-embedded information
|
||||
cover_urls = Covers.from_qobuz(resp)
|
||||
|
||||
bit_depth = typed(resp.get("maximum_bit_depth", -1), int)
|
||||
sampling_rate = typed(resp.get("maximum_sampling_rate", -1.0), int | float)
|
||||
quality = get_quality_id(bit_depth, sampling_rate)
|
||||
# Make sure it is non-empty list
|
||||
booklets = typed(resp.get("goodies", None) or None, list | None)
|
||||
item_id = str(resp.get("qobuz_id"))
|
||||
|
||||
if sampling_rate and bit_depth:
|
||||
container = "FLAC"
|
||||
else:
|
||||
container = "MP3"
|
||||
|
||||
info = AlbumInfo(
|
||||
id=item_id,
|
||||
quality=quality,
|
||||
container=container,
|
||||
label=label,
|
||||
explicit=explicit,
|
||||
sampling_rate=sampling_rate,
|
||||
bit_depth=bit_depth,
|
||||
booklets=booklets,
|
||||
)
|
||||
return AlbumMetadata(
|
||||
info,
|
||||
album,
|
||||
albumartist,
|
||||
year,
|
||||
genre=genres,
|
||||
covers=cover_urls,
|
||||
albumcomposer=albumcomposer,
|
||||
comment=None,
|
||||
compilation=None,
|
||||
copyright=_copyright,
|
||||
date=date,
|
||||
description=description,
|
||||
disctotal=disctotal,
|
||||
encoder=None,
|
||||
grouping=None,
|
||||
lyrics=None,
|
||||
purchase_date=None,
|
||||
tracktotal=tracktotal,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_deezer(cls, resp: dict) -> AlbumMetadata | None:
|
||||
album = resp.get("title", "Unknown Album")
|
||||
tracktotal = typed(resp.get("track_total", 0) or resp.get("nb_tracks", 0), int)
|
||||
disctotal = typed(resp["tracks"][-1]["disk_number"], int)
|
||||
genres = [typed(g["name"], str) for g in resp["genres"]["data"]]
|
||||
|
||||
date = typed(resp["release_date"], str)
|
||||
year = date[:4]
|
||||
_copyright = None
|
||||
description = None
|
||||
albumartist = typed(safe_get(resp, "artist", "name"), str)
|
||||
albumcomposer = None
|
||||
label = resp.get("label")
|
||||
booklets = None
|
||||
explicit = typed(
|
||||
resp.get("parental_warning", False) or resp.get("explicit_lyrics", False),
|
||||
bool,
|
||||
)
|
||||
|
||||
# not embedded
|
||||
quality = 2
|
||||
bit_depth = 16
|
||||
sampling_rate = 44100
|
||||
container = "FLAC"
|
||||
|
||||
cover_urls = Covers.from_deezer(resp)
|
||||
item_id = str(resp["id"])
|
||||
|
||||
info = AlbumInfo(
|
||||
id=item_id,
|
||||
quality=quality,
|
||||
container=container,
|
||||
label=label,
|
||||
explicit=explicit,
|
||||
sampling_rate=sampling_rate,
|
||||
bit_depth=bit_depth,
|
||||
booklets=booklets,
|
||||
)
|
||||
return AlbumMetadata(
|
||||
info,
|
||||
album,
|
||||
albumartist,
|
||||
year,
|
||||
genre=genres,
|
||||
covers=cover_urls,
|
||||
albumcomposer=albumcomposer,
|
||||
comment=None,
|
||||
compilation=None,
|
||||
copyright=_copyright,
|
||||
date=date,
|
||||
description=description,
|
||||
disctotal=disctotal,
|
||||
encoder=None,
|
||||
grouping=None,
|
||||
lyrics=None,
|
||||
purchase_date=None,
|
||||
tracktotal=tracktotal,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_soundcloud(cls, resp) -> AlbumMetadata:
|
||||
track = resp
|
||||
track_id = track["id"]
|
||||
bit_depth, sampling_rate = None, None
|
||||
explicit = typed(
|
||||
safe_get(track, "publisher_metadata", "explicit", default=False),
|
||||
bool,
|
||||
)
|
||||
genre = typed(track.get("genre"), str | None)
|
||||
genres = [genre] if genre is not None else []
|
||||
artist = typed(safe_get(track, "publisher_metadata", "artist"), str | None)
|
||||
artist = artist or typed(track["user"]["username"], str)
|
||||
albumartist = artist
|
||||
date = typed(track.get("created_at"), str)
|
||||
year = date[:4]
|
||||
label = typed(track.get("label_name"), str | None)
|
||||
description = typed(track.get("description"), str | None)
|
||||
album_title = typed(
|
||||
safe_get(track, "publisher_metadata", "album_title"),
|
||||
str | None,
|
||||
)
|
||||
album_title = album_title or "Unknown album"
|
||||
copyright = typed(safe_get(track, "publisher_metadata", "p_line"), str | None)
|
||||
tracktotal = 1
|
||||
disctotal = 1
|
||||
quality = 0
|
||||
covers = Covers.from_soundcloud(resp)
|
||||
|
||||
info = AlbumInfo(
|
||||
# There are no albums in soundcloud, so we just identify them by a track ID
|
||||
id=track_id,
|
||||
quality=quality,
|
||||
container="MP3",
|
||||
label=label,
|
||||
explicit=explicit,
|
||||
sampling_rate=sampling_rate,
|
||||
bit_depth=bit_depth,
|
||||
booklets=None,
|
||||
)
|
||||
return AlbumMetadata(
|
||||
info,
|
||||
album_title,
|
||||
albumartist,
|
||||
year,
|
||||
genre=genres,
|
||||
covers=covers,
|
||||
albumcomposer=None,
|
||||
comment=None,
|
||||
compilation=None,
|
||||
copyright=copyright,
|
||||
date=date,
|
||||
description=description,
|
||||
disctotal=disctotal,
|
||||
encoder=None,
|
||||
grouping=None,
|
||||
lyrics=None,
|
||||
purchase_date=None,
|
||||
tracktotal=tracktotal,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_tidal(cls, resp) -> AlbumMetadata | None:
|
||||
"""
|
||||
|
||||
Args:
|
||||
----
|
||||
resp: API response containing album metadata.
|
||||
|
||||
Returns: AlbumMetadata instance if the album is streamable, otherwise None.
|
||||
|
||||
|
||||
"""
|
||||
streamable = resp.get("allowStreaming", False)
|
||||
if not streamable:
|
||||
return None
|
||||
|
||||
item_id = str(resp["id"])
|
||||
album = typed(resp.get("title", "Unknown Album"), str)
|
||||
tracktotal = typed(resp.get("numberOfTracks", 1), int)
|
||||
# genre not returned by API
|
||||
date = typed(resp.get("releaseDate"), str)
|
||||
year = date[:4]
|
||||
_copyright = typed(resp.get("copyright", ""), str)
|
||||
|
||||
artists = typed(resp.get("artists", []), list)
|
||||
albumartist = ", ".join(a["name"] for a in artists)
|
||||
if not albumartist:
|
||||
albumartist = typed(safe_get(resp, "artist", "name", default=""), str)
|
||||
|
||||
disctotal = typed(resp.get("numberOfVolumes", 1), int)
|
||||
# label not returned by API
|
||||
|
||||
# non-embedded
|
||||
explicit = typed(resp.get("explicit", False), bool)
|
||||
covers = Covers.from_tidal(resp)
|
||||
if covers is None:
|
||||
covers = Covers()
|
||||
|
||||
quality_map: dict[str, int] = {
|
||||
"LOW": 0,
|
||||
"HIGH": 1,
|
||||
"LOSSLESS": 2,
|
||||
"HI_RES": 3,
|
||||
}
|
||||
|
||||
tidal_quality = resp.get("audioQuality", "LOW")
|
||||
quality = quality_map[tidal_quality]
|
||||
if quality >= 2:
|
||||
sampling_rate = 44100
|
||||
if quality == 3:
|
||||
bit_depth = 24
|
||||
else:
|
||||
bit_depth = 16
|
||||
else:
|
||||
sampling_rate = None
|
||||
bit_depth = None
|
||||
|
||||
info = AlbumInfo(
|
||||
id=item_id,
|
||||
quality=quality,
|
||||
container="MP4",
|
||||
label=None,
|
||||
explicit=explicit,
|
||||
sampling_rate=sampling_rate,
|
||||
bit_depth=bit_depth,
|
||||
booklets=None,
|
||||
)
|
||||
return AlbumMetadata(
|
||||
info,
|
||||
album,
|
||||
albumartist,
|
||||
year,
|
||||
genre=[],
|
||||
covers=covers,
|
||||
albumcomposer=None,
|
||||
comment=None,
|
||||
compilation=None,
|
||||
copyright=_copyright,
|
||||
date=date,
|
||||
description=None,
|
||||
disctotal=disctotal,
|
||||
encoder=None,
|
||||
grouping=None,
|
||||
lyrics=None,
|
||||
purchase_date=None,
|
||||
tracktotal=tracktotal,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_tidal_playlist_track_resp(cls, resp: dict) -> AlbumMetadata | None:
|
||||
album_resp = resp["album"]
|
||||
streamable = resp.get("allowStreaming", False)
|
||||
if not streamable:
|
||||
return None
|
||||
|
||||
item_id = str(resp["id"])
|
||||
album = typed(album_resp.get("title", "Unknown Album"), str)
|
||||
tracktotal = 1
|
||||
# genre not returned by API
|
||||
date = typed(resp.get("streamStartDate"), str | None)
|
||||
if date is not None:
|
||||
year = date[:4]
|
||||
else:
|
||||
year = "Unknown Year"
|
||||
|
||||
_copyright = typed(resp.get("copyright", ""), str)
|
||||
artists = typed(resp.get("artists", []), list)
|
||||
albumartist = ", ".join(a["name"] for a in artists)
|
||||
if not albumartist:
|
||||
albumartist = typed(
|
||||
safe_get(resp, "artist", "name", default="Unknown Albumbartist"), str
|
||||
)
|
||||
|
||||
disctotal = typed(resp.get("volumeNumber", 1), int)
|
||||
# label not returned by API
|
||||
|
||||
# non-embedded
|
||||
explicit = typed(resp.get("explicit", False), bool)
|
||||
covers = Covers.from_tidal(album_resp)
|
||||
if covers is None:
|
||||
covers = Covers()
|
||||
|
||||
quality_map: dict[str, int] = {
|
||||
"LOW": 0,
|
||||
"HIGH": 1,
|
||||
"LOSSLESS": 2,
|
||||
"HI_RES": 3,
|
||||
}
|
||||
|
||||
tidal_quality = resp.get("audioQuality", "LOW")
|
||||
quality = quality_map[tidal_quality]
|
||||
if quality >= 2:
|
||||
sampling_rate = 44100
|
||||
if quality == 3:
|
||||
bit_depth = 24
|
||||
else:
|
||||
bit_depth = 16
|
||||
else:
|
||||
sampling_rate = None
|
||||
bit_depth = None
|
||||
|
||||
info = AlbumInfo(
|
||||
id=item_id,
|
||||
quality=quality,
|
||||
container="MP4",
|
||||
label=None,
|
||||
explicit=explicit,
|
||||
sampling_rate=sampling_rate,
|
||||
bit_depth=bit_depth,
|
||||
booklets=None,
|
||||
)
|
||||
return AlbumMetadata(
|
||||
info,
|
||||
album,
|
||||
albumartist,
|
||||
year,
|
||||
genre=[],
|
||||
covers=covers,
|
||||
albumcomposer=None,
|
||||
comment=None,
|
||||
compilation=None,
|
||||
copyright=_copyright,
|
||||
date=date,
|
||||
description=None,
|
||||
disctotal=disctotal,
|
||||
encoder=None,
|
||||
grouping=None,
|
||||
lyrics=None,
|
||||
purchase_date=None,
|
||||
tracktotal=tracktotal,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_incomplete_deezer_track_resp(cls, resp: dict) -> AlbumMetadata | None:
|
||||
album_resp = resp["album"]
|
||||
album_id = album_resp["id"]
|
||||
album = album_resp["title"]
|
||||
covers = Covers.from_deezer(album_resp)
|
||||
date = album_resp["release_date"]
|
||||
year = date[:4]
|
||||
albumartist = ", ".join(a["name"] for a in resp["contributors"])
|
||||
explicit = resp.get("explicit_lyrics", False)
|
||||
|
||||
info = AlbumInfo(
|
||||
id=album_id,
|
||||
quality=2,
|
||||
container="MP4",
|
||||
label=None,
|
||||
explicit=explicit,
|
||||
sampling_rate=None,
|
||||
bit_depth=None,
|
||||
booklets=None,
|
||||
)
|
||||
return AlbumMetadata(
|
||||
info,
|
||||
album,
|
||||
albumartist,
|
||||
year,
|
||||
genre=[],
|
||||
covers=covers,
|
||||
albumcomposer=None,
|
||||
comment=None,
|
||||
compilation=None,
|
||||
copyright=None,
|
||||
date=date,
|
||||
description=None,
|
||||
disctotal=1,
|
||||
encoder=None,
|
||||
grouping=None,
|
||||
lyrics=None,
|
||||
purchase_date=None,
|
||||
tracktotal=1,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_track_resp(cls, resp: dict, source: str) -> AlbumMetadata | None:
|
||||
if source == "qobuz":
|
||||
return cls.from_qobuz(resp["album"])
|
||||
if source == "tidal":
|
||||
return cls.from_tidal_playlist_track_resp(resp)
|
||||
if source == "soundcloud":
|
||||
return cls.from_soundcloud(resp)
|
||||
if source == "deezer":
|
||||
if "tracks" not in resp["album"]:
|
||||
return cls.from_incomplete_deezer_track_resp(resp)
|
||||
return cls.from_deezer(resp["album"])
|
||||
raise Exception("Invalid source")
|
||||
|
||||
@classmethod
|
||||
def from_album_resp(cls, resp: dict, source: str) -> AlbumMetadata | None:
|
||||
if source == "qobuz":
|
||||
return cls.from_qobuz(resp)
|
||||
if source == "tidal":
|
||||
return cls.from_tidal(resp)
|
||||
if source == "soundcloud":
|
||||
return cls.from_soundcloud(resp)
|
||||
if source == "deezer":
|
||||
return cls.from_deezer(resp)
|
||||
raise Exception("Invalid source")
|
||||
|
|
@ -0,0 +1,27 @@
|
|||
from __future__ import annotations
|
||||
|
||||
import logging
|
||||
from dataclasses import dataclass
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class ArtistMetadata:
|
||||
name: str
|
||||
ids: list[str]
|
||||
|
||||
def album_ids(self):
|
||||
return self.ids
|
||||
|
||||
@classmethod
|
||||
def from_resp(cls, resp: dict, source: str) -> ArtistMetadata:
|
||||
logger.debug(resp)
|
||||
if source == "qobuz":
|
||||
return cls(resp["name"], [a["id"] for a in resp["albums"]["items"]])
|
||||
elif source == "tidal":
|
||||
return cls(resp["name"], [a["id"] for a in resp["albums"]])
|
||||
elif source == "deezer":
|
||||
return cls(resp["name"], [a["id"] for a in resp["albums"]])
|
||||
else:
|
||||
raise NotImplementedError
|
||||
|
|
@ -0,0 +1,128 @@
|
|||
TIDAL_COVER_URL = "https://resources.tidal.com/images/{uuid}/{width}x{height}.jpg"
|
||||
|
||||
|
||||
class Covers:
|
||||
COVER_SIZES = ("thumbnail", "small", "large", "original")
|
||||
CoverEntry = tuple[str, str | None, str | None]
|
||||
_covers: list[CoverEntry]
|
||||
|
||||
def __init__(self):
|
||||
# ordered from largest to smallest
|
||||
self._covers = [
|
||||
("original", None, None),
|
||||
("large", None, None),
|
||||
("small", None, None),
|
||||
("thumbnail", None, None),
|
||||
]
|
||||
|
||||
def set_cover(self, size: str, url: str | None, path: str | None):
|
||||
i = self._indexof(size)
|
||||
self._covers[i] = (size, url, path)
|
||||
|
||||
def set_cover_url(self, size: str, url: str):
|
||||
self.set_cover(size, url, None)
|
||||
|
||||
@staticmethod
|
||||
def _indexof(size: str) -> int:
|
||||
if size == "original":
|
||||
return 0
|
||||
if size == "large":
|
||||
return 1
|
||||
if size == "small":
|
||||
return 2
|
||||
if size == "thumbnail":
|
||||
return 3
|
||||
raise Exception(f"Invalid {size = }")
|
||||
|
||||
def empty(self) -> bool:
|
||||
return all(url is None for _, url, _ in self._covers)
|
||||
|
||||
def set_largest_path(self, path: str):
|
||||
for size, url, _ in self._covers:
|
||||
if url is not None:
|
||||
self.set_cover(size, url, path)
|
||||
return
|
||||
raise Exception(f"No covers found in {self}")
|
||||
|
||||
def set_path(self, size: str, path: str):
|
||||
i = self._indexof(size)
|
||||
size, url, _ = self._covers[i]
|
||||
self._covers[i] = (size, url, path)
|
||||
|
||||
def largest(self) -> CoverEntry:
|
||||
for s, u, p in self._covers:
|
||||
if u is not None:
|
||||
return (s, u, p)
|
||||
|
||||
raise Exception(f"No covers found in {self}")
|
||||
|
||||
@classmethod
|
||||
def from_qobuz(cls, resp):
|
||||
img = resp["image"]
|
||||
|
||||
c = cls()
|
||||
c.set_cover_url("original", "org".join(img["large"].rsplit("600", 1)))
|
||||
c.set_cover_url("large", img["large"])
|
||||
c.set_cover_url("small", img["small"])
|
||||
c.set_cover_url("thumbnail", img["thumbnail"])
|
||||
return c
|
||||
|
||||
@classmethod
|
||||
def from_deezer(cls, resp):
|
||||
c = cls()
|
||||
c.set_cover_url("original", resp["cover_xl"])
|
||||
c.set_cover_url("large", resp["cover_big"])
|
||||
c.set_cover_url("small", resp["cover_medium"])
|
||||
c.set_cover_url("thumbnail", resp["cover_small"])
|
||||
return c
|
||||
|
||||
@classmethod
|
||||
def from_soundcloud(cls, resp):
|
||||
c = cls()
|
||||
cover_url = (resp["artwork_url"] or resp["user"].get("avatar_url")).replace(
|
||||
"large",
|
||||
"t500x500",
|
||||
)
|
||||
c.set_cover_url("large", cover_url)
|
||||
return c
|
||||
|
||||
@classmethod
|
||||
def from_tidal(cls, resp):
|
||||
uuid = resp["cover"]
|
||||
if not uuid:
|
||||
return None
|
||||
|
||||
c = cls()
|
||||
for size_name, dimension in zip(cls.COVER_SIZES, (160, 320, 640, 1280)):
|
||||
c.set_cover_url(size_name, cls._get_tidal_cover_url(uuid, dimension))
|
||||
return c
|
||||
|
||||
def get_size(self, size: str) -> CoverEntry:
|
||||
i = self._indexof(size)
|
||||
size, url, path = self._covers[i]
|
||||
if url is not None:
|
||||
return (size, url, path)
|
||||
if i + 1 < len(self._covers):
|
||||
for s, u, p in self._covers[i + 1 :]:
|
||||
if u is not None:
|
||||
return (s, u, p)
|
||||
raise Exception(f"Cover not found for {size = }. Available: {self}")
|
||||
|
||||
@staticmethod
|
||||
def _get_tidal_cover_url(uuid, size):
|
||||
"""Generate a tidal cover url.
|
||||
|
||||
:param uuid: VALID uuid string
|
||||
:param size:
|
||||
"""
|
||||
possibles = (80, 160, 320, 640, 1280)
|
||||
assert size in possibles, f"size must be in {possibles}"
|
||||
return TIDAL_COVER_URL.format(
|
||||
uuid=uuid.replace("-", "/"),
|
||||
height=size,
|
||||
width=size,
|
||||
)
|
||||
|
||||
def __repr__(self):
|
||||
covers = "\n".join(map(repr, self._covers))
|
||||
return f"Covers({covers})"
|
||||
|
|
@ -0,0 +1,27 @@
|
|||
from __future__ import annotations
|
||||
|
||||
import logging
|
||||
from dataclasses import dataclass
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class LabelMetadata:
|
||||
name: str
|
||||
ids: list[str]
|
||||
|
||||
def album_ids(self):
|
||||
return self.ids
|
||||
|
||||
@classmethod
|
||||
def from_resp(cls, resp: dict, source: str) -> LabelMetadata:
|
||||
logger.debug(resp)
|
||||
if source == "qobuz":
|
||||
return cls(resp["name"], [a["id"] for a in resp["albums"]["items"]])
|
||||
elif source == "tidal":
|
||||
return cls(resp["name"], [a["id"] for a in resp["albums"]])
|
||||
elif source == "deezer":
|
||||
return cls(resp["name"], [a["id"] for a in resp["albums"]])
|
||||
else:
|
||||
raise NotImplementedError
|
||||
|
|
@ -0,0 +1,120 @@
|
|||
import logging
|
||||
from dataclasses import dataclass
|
||||
|
||||
from .album import AlbumMetadata
|
||||
from .track import TrackMetadata
|
||||
from .util import typed
|
||||
|
||||
NON_STREAMABLE = "_non_streamable"
|
||||
ORIGINAL_DOWNLOAD = "_original_download"
|
||||
NOT_RESOLVED = "_not_resolved"
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
|
||||
def get_soundcloud_id(resp: dict) -> str:
|
||||
item_id = resp["id"]
|
||||
if "media" not in resp:
|
||||
return f"{item_id}|{NOT_RESOLVED}"
|
||||
|
||||
if not resp["streamable"] or resp["policy"] == "BLOCK":
|
||||
return f"{item_id}|{NON_STREAMABLE}"
|
||||
|
||||
if resp["downloadable"] and resp["has_downloads_left"]:
|
||||
return f"{item_id}|{ORIGINAL_DOWNLOAD}"
|
||||
|
||||
url = None
|
||||
for tc in resp["media"]["transcodings"]:
|
||||
fmt = tc["format"]
|
||||
if fmt["protocol"] == "hls" and fmt["mime_type"] == "audio/mpeg":
|
||||
url = tc["url"]
|
||||
break
|
||||
|
||||
assert url is not None
|
||||
return f"{item_id}|{url}"
|
||||
|
||||
|
||||
def parse_soundcloud_id(item_id: str) -> tuple[str, str]:
|
||||
info = item_id.split("|")
|
||||
assert len(info) == 2
|
||||
return (info[0], info[1])
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class PlaylistMetadata:
|
||||
name: str
|
||||
tracks: list[TrackMetadata] | list[str]
|
||||
|
||||
@classmethod
|
||||
def from_qobuz(cls, resp: dict):
|
||||
logger.debug(resp)
|
||||
name = typed(resp["name"], str)
|
||||
tracks = []
|
||||
|
||||
for i, track in enumerate(resp["tracks"]["items"]):
|
||||
meta = TrackMetadata.from_qobuz(
|
||||
AlbumMetadata.from_qobuz(track["album"]),
|
||||
track,
|
||||
)
|
||||
if meta is None:
|
||||
logger.error(f"Track {i+1} in playlist {name} not available for stream")
|
||||
continue
|
||||
tracks.append(meta)
|
||||
|
||||
return cls(name, tracks)
|
||||
|
||||
@classmethod
|
||||
def from_soundcloud(cls, resp: dict):
|
||||
"""Convert a (modified) soundcloud API response to PlaylistMetadata.
|
||||
|
||||
Args:
|
||||
----
|
||||
resp (dict): The response, except there should not be any partially resolved items
|
||||
in the playlist.
|
||||
|
||||
e.g. If soundcloud only returns the full metadata of 5 of them, the rest of the
|
||||
elements in resp['tracks'] should be replaced with their full metadata.
|
||||
|
||||
Returns:
|
||||
-------
|
||||
PlaylistMetadata object.
|
||||
"""
|
||||
name = typed(resp["title"], str)
|
||||
tracks = [
|
||||
TrackMetadata.from_soundcloud(AlbumMetadata.from_soundcloud(track), track)
|
||||
for track in resp["tracks"]
|
||||
]
|
||||
return cls(name, tracks)
|
||||
|
||||
@classmethod
|
||||
def from_deezer(cls, resp: dict):
|
||||
name = typed(resp["title"], str)
|
||||
tracks = [str(track["id"]) for track in resp["tracks"]]
|
||||
return cls(name, tracks)
|
||||
|
||||
@classmethod
|
||||
def from_tidal(cls, resp: dict):
|
||||
name = typed(resp["title"], str)
|
||||
tracks = [str(track["id"]) for track in resp["tracks"]]
|
||||
return cls(name, tracks)
|
||||
|
||||
def ids(self) -> list[str]:
|
||||
if len(self.tracks) == 0:
|
||||
return []
|
||||
if isinstance(self.tracks[0], str):
|
||||
return self.tracks # type: ignore
|
||||
|
||||
return [track.info.id for track in self.tracks] # type: ignore
|
||||
|
||||
@classmethod
|
||||
def from_resp(cls, resp: dict, source: str):
|
||||
if source == "qobuz":
|
||||
return cls.from_qobuz(resp)
|
||||
elif source == "soundcloud":
|
||||
return cls.from_soundcloud(resp)
|
||||
elif source == "deezer":
|
||||
return cls.from_deezer(resp)
|
||||
elif source == "tidal":
|
||||
return cls.from_tidal(resp)
|
||||
else:
|
||||
raise NotImplementedError(source)
|
||||
|
|
@ -0,0 +1,299 @@
|
|||
import os
|
||||
import re
|
||||
import textwrap
|
||||
from abc import ABC, abstractmethod
|
||||
from dataclasses import dataclass
|
||||
|
||||
|
||||
class Summary(ABC):
|
||||
id: str
|
||||
|
||||
@abstractmethod
|
||||
def summarize(self) -> str:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def preview(self) -> str:
|
||||
pass
|
||||
|
||||
@classmethod
|
||||
@abstractmethod
|
||||
def from_item(cls, item: dict) -> str:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def media_type(self) -> str:
|
||||
pass
|
||||
|
||||
def __str__(self):
|
||||
return self.summarize()
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class ArtistSummary(Summary):
|
||||
id: str
|
||||
name: str
|
||||
num_albums: str
|
||||
|
||||
def media_type(self):
|
||||
return "artist"
|
||||
|
||||
def summarize(self) -> str:
|
||||
return clean(self.name)
|
||||
|
||||
def preview(self) -> str:
|
||||
return f"{self.num_albums} Albums\n\nID: {self.id}"
|
||||
|
||||
@classmethod
|
||||
def from_item(cls, item: dict):
|
||||
id = str(item["id"])
|
||||
name = (
|
||||
item.get("name")
|
||||
or item.get("performer", {}).get("name")
|
||||
or item.get("artist")
|
||||
or item.get("artist", {}).get("name")
|
||||
or (
|
||||
item.get("publisher_metadata")
|
||||
and item["publisher_metadata"].get("artist")
|
||||
)
|
||||
or "Unknown"
|
||||
)
|
||||
num_albums = item.get("albums_count") or "Unknown"
|
||||
return cls(id, name, num_albums)
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class TrackSummary(Summary):
|
||||
id: str
|
||||
name: str
|
||||
artist: str
|
||||
date_released: str | None
|
||||
|
||||
def media_type(self):
|
||||
return "track"
|
||||
|
||||
def summarize(self) -> str:
|
||||
# This char breaks the menu for some reason
|
||||
return f"{clean(self.name)} by {clean(self.artist)}"
|
||||
|
||||
def preview(self) -> str:
|
||||
return f"Released on:\n{self.date_released}\n\nID: {self.id}"
|
||||
|
||||
@classmethod
|
||||
def from_item(cls, item: dict):
|
||||
id = str(item["id"])
|
||||
name = item.get("title") or item.get("name") or "Unknown"
|
||||
artist = (
|
||||
item.get("performer", {}).get("name")
|
||||
or item.get("artist")
|
||||
or item.get("artist", {}).get("name")
|
||||
or (
|
||||
item.get("publisher_metadata")
|
||||
and item["publisher_metadata"].get("artist")
|
||||
)
|
||||
or "Unknown"
|
||||
)
|
||||
if isinstance(artist, dict) and "name" in artist:
|
||||
artist = artist["name"]
|
||||
|
||||
date_released = (
|
||||
item.get("release_date")
|
||||
or item.get("streamStartDate")
|
||||
or item.get("album", {}).get("release_date_original")
|
||||
or item.get("display_date")
|
||||
or item.get("date")
|
||||
or item.get("year")
|
||||
or "Unknown"
|
||||
)
|
||||
return cls(id, name.strip(), artist, date_released) # type: ignore
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class AlbumSummary(Summary):
|
||||
id: str
|
||||
name: str
|
||||
artist: str
|
||||
num_tracks: str
|
||||
date_released: str | None
|
||||
|
||||
def media_type(self):
|
||||
return "album"
|
||||
|
||||
def summarize(self) -> str:
|
||||
return f"{clean(self.name)} by {clean(self.artist)}"
|
||||
|
||||
def preview(self) -> str:
|
||||
return f"Date released:\n{self.date_released}\n\n{self.num_tracks} Tracks\n\nID: {self.id}"
|
||||
|
||||
@classmethod
|
||||
def from_item(cls, item: dict):
|
||||
id = str(item["id"])
|
||||
name = item.get("title") or "Unknown Title"
|
||||
artist = (
|
||||
item.get("performer", {}).get("name")
|
||||
or item.get("artist", {}).get("name")
|
||||
or item.get("artist")
|
||||
or (
|
||||
item.get("publisher_metadata")
|
||||
and item["publisher_metadata"].get("artist")
|
||||
)
|
||||
or "Unknown"
|
||||
)
|
||||
num_tracks = (
|
||||
item.get("tracks_count", 0)
|
||||
or item.get("numberOfTracks", 0)
|
||||
or len(
|
||||
item.get("tracks", []) or item.get("items", []),
|
||||
)
|
||||
)
|
||||
|
||||
date_released = (
|
||||
item.get("release_date_original")
|
||||
or item.get("release_date")
|
||||
or item.get("releaseDate")
|
||||
or item.get("display_date")
|
||||
or item.get("date")
|
||||
or item.get("year")
|
||||
or "Unknown"
|
||||
)
|
||||
return cls(id, name, artist, str(num_tracks), date_released)
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class LabelSummary(Summary):
|
||||
id: str
|
||||
name: str
|
||||
|
||||
def media_type(self):
|
||||
return "label"
|
||||
|
||||
def summarize(self) -> str:
|
||||
return str(self)
|
||||
|
||||
def preview(self) -> str:
|
||||
return str(self)
|
||||
|
||||
@classmethod
|
||||
def from_item(cls, item: dict):
|
||||
id = str(item["id"])
|
||||
name = item["name"]
|
||||
return cls(id, name)
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class PlaylistSummary(Summary):
|
||||
id: str
|
||||
name: str
|
||||
creator: str
|
||||
num_tracks: int
|
||||
description: str
|
||||
|
||||
def summarize(self) -> str:
|
||||
name = clean(self.name)
|
||||
creator = clean(self.creator)
|
||||
return f"{name} by {creator}"
|
||||
|
||||
def preview(self) -> str:
|
||||
desc = clean(self.description, trunc=False)
|
||||
wrapped = "\n".join(
|
||||
textwrap.wrap(desc, os.get_terminal_size().columns - 4 or 70),
|
||||
)
|
||||
return f"{self.num_tracks} tracks\n\nDescription:\n{wrapped}\n\nID: {self.id}"
|
||||
|
||||
def media_type(self):
|
||||
return "playlist"
|
||||
|
||||
@classmethod
|
||||
def from_item(cls, item: dict):
|
||||
id = item.get("id") or item.get("uuid") or "Unknown"
|
||||
name = item.get("name") or item.get("title") or "Unknown"
|
||||
creator = (
|
||||
(item.get("publisher_metadata") and item["publisher_metadata"]["artist"])
|
||||
or item.get("owner", {}).get("name")
|
||||
or item.get("user", {}).get("username")
|
||||
or item.get("user", {}).get("name")
|
||||
or "Unknown"
|
||||
)
|
||||
num_tracks = (
|
||||
item.get("tracks_count")
|
||||
or item.get("nb_tracks")
|
||||
or item.get("numberOfTracks")
|
||||
or len(item.get("tracks", []))
|
||||
or -1
|
||||
)
|
||||
description = item.get("description") or "No description"
|
||||
return cls(id, name, creator, num_tracks, description)
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class SearchResults:
|
||||
results: list[Summary]
|
||||
|
||||
@classmethod
|
||||
def from_pages(cls, source: str, media_type: str, pages: list[dict]):
|
||||
if media_type == "track":
|
||||
summary_type = TrackSummary
|
||||
elif media_type == "album":
|
||||
summary_type = AlbumSummary
|
||||
elif media_type == "label":
|
||||
summary_type = LabelSummary
|
||||
elif media_type == "artist":
|
||||
summary_type = ArtistSummary
|
||||
elif media_type == "playlist":
|
||||
summary_type = PlaylistSummary
|
||||
else:
|
||||
raise Exception(f"invalid media type {media_type}")
|
||||
|
||||
results = []
|
||||
for page in pages:
|
||||
if source == "soundcloud":
|
||||
items = page["collection"]
|
||||
for item in items:
|
||||
results.append(summary_type.from_item(item))
|
||||
elif source == "qobuz":
|
||||
key = media_type + "s"
|
||||
for item in page[key]["items"]:
|
||||
results.append(summary_type.from_item(item))
|
||||
elif source == "deezer":
|
||||
for item in page["data"]:
|
||||
results.append(summary_type.from_item(item))
|
||||
elif source == "tidal":
|
||||
for item in page["items"]:
|
||||
results.append(summary_type.from_item(item))
|
||||
else:
|
||||
raise NotImplementedError
|
||||
|
||||
return cls(results)
|
||||
|
||||
def summaries(self) -> list[str]:
|
||||
return [f"{i+1}. {r.summarize()}" for i, r in enumerate(self.results)]
|
||||
|
||||
def get_choices(self, inds: tuple[int, ...] | int):
|
||||
if isinstance(inds, int):
|
||||
inds = (inds,)
|
||||
return [self.results[i] for i in inds]
|
||||
|
||||
def preview(self, s: str) -> str:
|
||||
ind = re.match(r"^\d+", s)
|
||||
assert ind is not None
|
||||
i = int(ind.group(0))
|
||||
return self.results[i - 1].preview()
|
||||
|
||||
def as_list(self, source: str) -> list[dict[str, str]]:
|
||||
return [
|
||||
{
|
||||
"source": source,
|
||||
"media_type": i.media_type(),
|
||||
"id": i.id,
|
||||
"desc": i.summarize(),
|
||||
}
|
||||
for i in self.results
|
||||
]
|
||||
|
||||
|
||||
def clean(s: str, trunc=True) -> str:
|
||||
s = s.replace("|", "").replace("\n", "")
|
||||
if trunc:
|
||||
max_chars = 50
|
||||
return s[:max_chars]
|
||||
return s
|
||||
|
|
@ -0,0 +1,257 @@
|
|||
import logging
|
||||
import os
|
||||
from enum import Enum
|
||||
|
||||
import aiofiles
|
||||
from mutagen import id3
|
||||
from mutagen.flac import FLAC, Picture
|
||||
from mutagen.id3 import (
|
||||
APIC, # type: ignore
|
||||
ID3,
|
||||
ID3NoHeaderError,
|
||||
)
|
||||
from mutagen.mp4 import MP4, MP4Cover
|
||||
|
||||
from .track import TrackMetadata
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
FLAC_MAX_BLOCKSIZE = 16777215 # 16.7 MB
|
||||
|
||||
MP4_KEYS = (
|
||||
"\xa9nam",
|
||||
"\xa9ART",
|
||||
"\xa9alb",
|
||||
r"aART",
|
||||
"\xa9day",
|
||||
"\xa9day",
|
||||
"\xa9cmt",
|
||||
"desc",
|
||||
"purd",
|
||||
"\xa9grp",
|
||||
"\xa9gen",
|
||||
"\xa9lyr",
|
||||
"\xa9too",
|
||||
"cprt",
|
||||
"cpil",
|
||||
"trkn",
|
||||
"disk",
|
||||
None,
|
||||
None,
|
||||
None,
|
||||
"----:com.apple.iTunes:ISRC",
|
||||
)
|
||||
|
||||
MP3_KEYS = (
|
||||
id3.TIT2, # type: ignore
|
||||
id3.TPE1, # type: ignore
|
||||
id3.TALB, # type: ignore
|
||||
id3.TPE2, # type: ignore
|
||||
id3.TCOM, # type: ignore
|
||||
id3.TYER, # type: ignore
|
||||
id3.COMM, # type: ignore
|
||||
id3.TT1, # type: ignore
|
||||
id3.TT1, # type: ignore
|
||||
id3.GP1, # type: ignore
|
||||
id3.TCON, # type: ignore
|
||||
id3.USLT, # type: ignore
|
||||
id3.TEN, # type: ignore
|
||||
id3.TCOP, # type: ignore
|
||||
id3.TCMP, # type: ignore
|
||||
id3.TRCK, # type: ignore
|
||||
id3.TPOS, # type: ignore
|
||||
None,
|
||||
None,
|
||||
None,
|
||||
id3.TSRC,
|
||||
)
|
||||
|
||||
METADATA_TYPES = (
|
||||
"title",
|
||||
"artist",
|
||||
"album",
|
||||
"albumartist",
|
||||
"composer",
|
||||
"year",
|
||||
"comment",
|
||||
"description",
|
||||
"purchase_date",
|
||||
"grouping",
|
||||
"genre",
|
||||
"lyrics",
|
||||
"encoder",
|
||||
"copyright",
|
||||
"compilation",
|
||||
"tracknumber",
|
||||
"discnumber",
|
||||
"tracktotal",
|
||||
"disctotal",
|
||||
"date",
|
||||
"isrc",
|
||||
)
|
||||
|
||||
|
||||
FLAC_KEY = {v: v.upper() for v in METADATA_TYPES}
|
||||
MP4_KEY = dict(zip(METADATA_TYPES, MP4_KEYS))
|
||||
MP3_KEY = dict(zip(METADATA_TYPES, MP3_KEYS))
|
||||
|
||||
|
||||
class Container(Enum):
|
||||
FLAC = 1
|
||||
AAC = 2
|
||||
MP3 = 3
|
||||
|
||||
def get_mutagen_class(self, path: str):
|
||||
if self == Container.FLAC:
|
||||
return FLAC(path)
|
||||
elif self == Container.AAC:
|
||||
return MP4(path)
|
||||
elif self == Container.MP3:
|
||||
try:
|
||||
return ID3(path)
|
||||
except ID3NoHeaderError:
|
||||
return ID3()
|
||||
# unreachable
|
||||
return {}
|
||||
|
||||
def get_tag_pairs(self, meta) -> list[tuple]:
|
||||
if self == Container.FLAC:
|
||||
return self._tag_flac(meta)
|
||||
elif self == Container.MP3:
|
||||
return self._tag_mp3(meta)
|
||||
elif self == Container.AAC:
|
||||
return self._tag_mp4(meta)
|
||||
# unreachable
|
||||
return []
|
||||
|
||||
def _tag_flac(self, meta: TrackMetadata) -> list[tuple]:
|
||||
out = []
|
||||
for k, v in FLAC_KEY.items():
|
||||
tag = self._attr_from_meta(meta, k)
|
||||
if tag:
|
||||
if k in {
|
||||
"tracknumber",
|
||||
"discnumber",
|
||||
"tracktotal",
|
||||
"disctotal",
|
||||
}:
|
||||
tag = f"{int(tag):02}"
|
||||
|
||||
out.append((v, str(tag)))
|
||||
return out
|
||||
|
||||
def _tag_mp3(self, meta: TrackMetadata):
|
||||
out = []
|
||||
for k, v in MP3_KEY.items():
|
||||
if k == "tracknumber":
|
||||
text = f"{meta.tracknumber}/{meta.album.tracktotal}"
|
||||
elif k == "discnumber":
|
||||
text = f"{meta.discnumber}/{meta.album.disctotal}"
|
||||
else:
|
||||
text = self._attr_from_meta(meta, k)
|
||||
|
||||
if text is not None and v is not None:
|
||||
out.append((v.__name__, v(encoding=3, text=text)))
|
||||
return out
|
||||
|
||||
def _tag_mp4(self, meta: TrackMetadata):
|
||||
out = []
|
||||
for k, v in MP4_KEY.items():
|
||||
if k == "tracknumber":
|
||||
text = [(meta.tracknumber, meta.album.tracktotal)]
|
||||
elif k == "discnumber":
|
||||
text = [(meta.discnumber, meta.album.disctotal)]
|
||||
elif k == "isrc" and meta.isrc is not None:
|
||||
# because ISRC is an mp4 freeform value (not supported natively)
|
||||
# we have to pass in the actual bytes to mutagen
|
||||
# See mutagen.MP4Tags.__render_freeform
|
||||
text = meta.isrc.encode("utf-8")
|
||||
else:
|
||||
text = self._attr_from_meta(meta, k)
|
||||
|
||||
if v is not None and text is not None:
|
||||
out.append((v, text))
|
||||
return out
|
||||
|
||||
def _attr_from_meta(self, meta: TrackMetadata, attr: str) -> str | None:
|
||||
# TODO: verify this works
|
||||
in_trackmetadata = {
|
||||
"title",
|
||||
"album",
|
||||
"artist",
|
||||
"tracknumber",
|
||||
"discnumber",
|
||||
"composer",
|
||||
"isrc",
|
||||
}
|
||||
if attr in in_trackmetadata:
|
||||
if attr == "album":
|
||||
return meta.album.album
|
||||
val = getattr(meta, attr)
|
||||
if val is None:
|
||||
return None
|
||||
return str(val)
|
||||
else:
|
||||
if attr == "genre":
|
||||
return meta.album.get_genres()
|
||||
elif attr == "copyright":
|
||||
return meta.album.get_copyright()
|
||||
val = getattr(meta.album, attr)
|
||||
if val is None:
|
||||
return None
|
||||
return str(val)
|
||||
|
||||
def tag_audio(self, audio, tags: list[tuple]):
|
||||
for k, v in tags:
|
||||
audio[k] = v
|
||||
|
||||
async def embed_cover(self, audio, cover_path):
|
||||
if self == Container.FLAC:
|
||||
size = os.path.getsize(cover_path)
|
||||
if size > FLAC_MAX_BLOCKSIZE:
|
||||
raise Exception("Cover art too big for FLAC")
|
||||
cover = Picture()
|
||||
cover.type = 3
|
||||
cover.mime = "image/jpeg"
|
||||
async with aiofiles.open(cover_path, "rb") as img:
|
||||
cover.data = await img.read()
|
||||
audio.add_picture(cover)
|
||||
elif self == Container.MP3:
|
||||
cover = APIC()
|
||||
cover.type = 3
|
||||
cover.mime = "image/jpeg"
|
||||
async with aiofiles.open(cover_path, "rb") as img:
|
||||
cover.data = await img.read()
|
||||
audio.add(cover)
|
||||
elif self == Container.AAC:
|
||||
async with aiofiles.open(cover_path, "rb") as img:
|
||||
cover = MP4Cover(await img.read(), imageformat=MP4Cover.FORMAT_JPEG)
|
||||
audio["covr"] = [cover]
|
||||
|
||||
def save_audio(self, audio, path):
|
||||
if self == Container.FLAC:
|
||||
audio.save()
|
||||
elif self == Container.AAC:
|
||||
audio.save()
|
||||
elif self == Container.MP3:
|
||||
audio.save(path, "v2_version=3")
|
||||
|
||||
|
||||
async def tag_file(path: str, meta: TrackMetadata, cover_path: str | None):
|
||||
ext = path.split(".")[-1].lower()
|
||||
if ext == "flac":
|
||||
container = Container.FLAC
|
||||
elif ext == "m4a":
|
||||
container = Container.AAC
|
||||
elif ext == "mp3":
|
||||
container = Container.MP3
|
||||
else:
|
||||
raise Exception(f"Invalid extension {ext}")
|
||||
|
||||
audio = container.get_mutagen_class(path)
|
||||
tags = container.get_tag_pairs(meta)
|
||||
logger.debug("Tagging with %s", tags)
|
||||
container.tag_audio(audio, tags)
|
||||
if cover_path is not None:
|
||||
await container.embed_cover(audio, cover_path)
|
||||
container.save_audio(audio, path)
|
||||
|
|
@ -0,0 +1,239 @@
|
|||
from __future__ import annotations
|
||||
|
||||
import logging
|
||||
from dataclasses import dataclass
|
||||
from typing import Optional
|
||||
|
||||
from .album import AlbumMetadata
|
||||
from .util import safe_get, typed
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class TrackInfo:
|
||||
id: str
|
||||
quality: int
|
||||
|
||||
bit_depth: Optional[int] = None
|
||||
explicit: bool = False
|
||||
sampling_rate: Optional[int | float] = None
|
||||
work: Optional[str] = None
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class TrackMetadata:
|
||||
info: TrackInfo
|
||||
|
||||
title: str
|
||||
album: AlbumMetadata
|
||||
artist: str
|
||||
tracknumber: int
|
||||
discnumber: int
|
||||
composer: str | None
|
||||
isrc: str | None = None
|
||||
|
||||
@classmethod
|
||||
def from_qobuz(cls, album: AlbumMetadata, resp: dict) -> TrackMetadata | None:
|
||||
title = typed(resp["title"].strip(), str)
|
||||
isrc = typed(resp["isrc"], str)
|
||||
streamable = typed(resp.get("streamable", False), bool)
|
||||
|
||||
if not streamable:
|
||||
return None
|
||||
|
||||
version = typed(resp.get("version"), str | None)
|
||||
work = typed(resp.get("work"), str | None)
|
||||
if version is not None and version not in title:
|
||||
title = f"{title} ({version})"
|
||||
if work is not None and work not in title:
|
||||
title = f"{work}: {title}"
|
||||
|
||||
composer = typed(resp.get("composer", {}).get("name"), str | None)
|
||||
tracknumber = typed(resp.get("track_number", 1), int)
|
||||
discnumber = typed(resp.get("media_number", 1), int)
|
||||
artist = typed(
|
||||
safe_get(
|
||||
resp,
|
||||
"performer",
|
||||
"name",
|
||||
),
|
||||
str,
|
||||
)
|
||||
track_id = str(resp["id"])
|
||||
bit_depth = typed(resp.get("maximum_bit_depth"), int | None)
|
||||
sampling_rate = typed(resp.get("maximum_sampling_rate"), int | float | None)
|
||||
# Is the info included?
|
||||
explicit = False
|
||||
|
||||
info = TrackInfo(
|
||||
id=track_id,
|
||||
quality=album.info.quality,
|
||||
bit_depth=bit_depth,
|
||||
explicit=explicit,
|
||||
sampling_rate=sampling_rate,
|
||||
work=work,
|
||||
)
|
||||
return cls(
|
||||
info=info,
|
||||
title=title,
|
||||
album=album,
|
||||
artist=artist,
|
||||
tracknumber=tracknumber,
|
||||
discnumber=discnumber,
|
||||
composer=composer,
|
||||
isrc=isrc,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_deezer(cls, album: AlbumMetadata, resp) -> TrackMetadata | None:
|
||||
track_id = str(resp["id"])
|
||||
isrc = typed(resp["isrc"], str)
|
||||
bit_depth = 16
|
||||
sampling_rate = 44.1
|
||||
explicit = typed(resp["explicit_lyrics"], bool)
|
||||
work = None
|
||||
title = typed(resp["title"], str)
|
||||
artist = typed(resp["artist"]["name"], str)
|
||||
tracknumber = typed(resp["track_position"], int)
|
||||
discnumber = typed(resp["disk_number"], int)
|
||||
composer = None
|
||||
info = TrackInfo(
|
||||
id=track_id,
|
||||
quality=album.info.quality,
|
||||
bit_depth=bit_depth,
|
||||
explicit=explicit,
|
||||
sampling_rate=sampling_rate,
|
||||
work=work,
|
||||
)
|
||||
return cls(
|
||||
info=info,
|
||||
title=title,
|
||||
album=album,
|
||||
artist=artist,
|
||||
tracknumber=tracknumber,
|
||||
discnumber=discnumber,
|
||||
composer=composer,
|
||||
isrc=isrc,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_soundcloud(cls, album: AlbumMetadata, resp: dict) -> TrackMetadata:
|
||||
track = resp
|
||||
track_id = track["id"]
|
||||
isrc = typed(safe_get(track, "publisher_metadata", "isrc"), str | None)
|
||||
bit_depth, sampling_rate = None, None
|
||||
explicit = typed(
|
||||
safe_get(track, "publisher_metadata", "explicit", default=False),
|
||||
bool,
|
||||
)
|
||||
|
||||
title = typed(track["title"].strip(), str)
|
||||
artist = typed(track["user"]["username"], str)
|
||||
tracknumber = 1
|
||||
|
||||
info = TrackInfo(
|
||||
id=track_id,
|
||||
quality=album.info.quality,
|
||||
bit_depth=bit_depth,
|
||||
explicit=explicit,
|
||||
sampling_rate=sampling_rate,
|
||||
work=None,
|
||||
)
|
||||
return cls(
|
||||
info=info,
|
||||
title=title,
|
||||
album=album,
|
||||
artist=artist,
|
||||
tracknumber=tracknumber,
|
||||
discnumber=0,
|
||||
composer=None,
|
||||
isrc=isrc,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_tidal(cls, album: AlbumMetadata, track) -> TrackMetadata:
|
||||
title = typed(track["title"], str).strip()
|
||||
item_id = str(track["id"])
|
||||
isrc = typed(track["isrc"], str)
|
||||
version = track.get("version")
|
||||
explicit = track.get("explicit", False)
|
||||
if version:
|
||||
title = f"{title} ({version})"
|
||||
|
||||
tracknumber = typed(track.get("trackNumber", 1), int)
|
||||
discnumber = typed(track.get("volumeNumber", 1), int)
|
||||
|
||||
artists = track.get("artists")
|
||||
if len(artists) > 0:
|
||||
artist = ", ".join(a["name"] for a in artists)
|
||||
else:
|
||||
artist = track["artist"]["name"]
|
||||
|
||||
quality_map: dict[str, int] = {
|
||||
"LOW": 0,
|
||||
"HIGH": 1,
|
||||
"LOSSLESS": 2,
|
||||
"HI_RES": 3,
|
||||
}
|
||||
|
||||
tidal_quality = track.get("audioQuality")
|
||||
if tidal_quality is not None:
|
||||
quality = quality_map[tidal_quality]
|
||||
else:
|
||||
quality = 0
|
||||
|
||||
if quality >= 2:
|
||||
sampling_rate = 44100
|
||||
if quality == 3:
|
||||
bit_depth = 24
|
||||
else:
|
||||
bit_depth = 16
|
||||
else:
|
||||
sampling_rate = bit_depth = None
|
||||
|
||||
info = TrackInfo(
|
||||
id=item_id,
|
||||
quality=quality,
|
||||
bit_depth=bit_depth,
|
||||
explicit=explicit,
|
||||
sampling_rate=sampling_rate,
|
||||
work=None,
|
||||
)
|
||||
return cls(
|
||||
info=info,
|
||||
title=title,
|
||||
album=album,
|
||||
artist=artist,
|
||||
tracknumber=tracknumber,
|
||||
discnumber=discnumber,
|
||||
composer=None,
|
||||
isrc=isrc,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_resp(cls, album: AlbumMetadata, source, resp) -> TrackMetadata | None:
|
||||
if source == "qobuz":
|
||||
return cls.from_qobuz(album, resp)
|
||||
if source == "tidal":
|
||||
return cls.from_tidal(album, resp)
|
||||
if source == "soundcloud":
|
||||
return cls.from_soundcloud(album, resp)
|
||||
if source == "deezer":
|
||||
return cls.from_deezer(album, resp)
|
||||
raise Exception
|
||||
|
||||
def format_track_path(self, format_string: str) -> str:
|
||||
# Available keys: "tracknumber", "artist", "albumartist", "composer", "title",
|
||||
# and "explicit", "albumcomposer"
|
||||
none_text = "Unknown"
|
||||
info = {
|
||||
"title": self.title,
|
||||
"tracknumber": self.tracknumber,
|
||||
"artist": self.artist,
|
||||
"albumartist": self.album.albumartist,
|
||||
"albumcomposer": self.album.albumcomposer or none_text,
|
||||
"composer": self.composer or none_text,
|
||||
"explicit": " (Explicit) " if self.info.explicit else "",
|
||||
}
|
||||
return format_string.format(**info)
|
||||
|
|
@ -0,0 +1,52 @@
|
|||
import functools
|
||||
from typing import Optional, Type, TypeVar
|
||||
|
||||
|
||||
def get_album_track_ids(source: str, resp) -> list[str]:
|
||||
tracklist = resp["tracks"]
|
||||
if source == "qobuz":
|
||||
tracklist = tracklist["items"]
|
||||
return [track["id"] for track in tracklist]
|
||||
|
||||
|
||||
def safe_get(dictionary, *keys, default=None):
|
||||
return functools.reduce(
|
||||
lambda d, key: d.get(key, default) if isinstance(d, dict) else default,
|
||||
keys,
|
||||
dictionary,
|
||||
)
|
||||
|
||||
|
||||
T = TypeVar("T")
|
||||
|
||||
|
||||
def typed(thing, expected_type: Type[T]) -> T:
|
||||
assert isinstance(thing, expected_type)
|
||||
return thing
|
||||
|
||||
|
||||
def get_quality_id(
|
||||
bit_depth: Optional[int],
|
||||
sampling_rate: Optional[int | float],
|
||||
) -> int:
|
||||
"""Get the universal quality id from bit depth and sampling rate.
|
||||
|
||||
:param bit_depth:
|
||||
:type bit_depth: Optional[int]
|
||||
:param sampling_rate: In kHz
|
||||
:type sampling_rate: Optional[int]
|
||||
"""
|
||||
# XXX: Should `0` quality be supported?
|
||||
if bit_depth is None or sampling_rate is None: # is lossy
|
||||
return 1
|
||||
|
||||
if bit_depth == 16:
|
||||
return 2
|
||||
|
||||
if bit_depth == 24:
|
||||
if sampling_rate <= 96:
|
||||
return 3
|
||||
|
||||
return 4
|
||||
|
||||
raise Exception(f"Invalid {bit_depth = }")
|
||||
|
|
@ -0,0 +1,113 @@
|
|||
from dataclasses import dataclass
|
||||
from typing import Callable
|
||||
|
||||
from rich.console import Group
|
||||
from rich.live import Live
|
||||
from rich.progress import (
|
||||
BarColumn,
|
||||
Progress,
|
||||
TextColumn,
|
||||
TimeRemainingColumn,
|
||||
TransferSpeedColumn,
|
||||
)
|
||||
from rich.rule import Rule
|
||||
from rich.text import Text
|
||||
|
||||
from .console import console
|
||||
|
||||
|
||||
class ProgressManager:
|
||||
def __init__(self):
|
||||
self.started = False
|
||||
self.progress = Progress(console=console)
|
||||
self.progress = Progress(
|
||||
TextColumn("[cyan]{task.description}"),
|
||||
BarColumn(bar_width=None),
|
||||
"[progress.percentage]{task.percentage:>3.1f}%",
|
||||
"•",
|
||||
TransferSpeedColumn(),
|
||||
"•",
|
||||
TimeRemainingColumn(),
|
||||
console=console,
|
||||
)
|
||||
|
||||
self.task_titles = []
|
||||
self.prefix = Text.assemble(("Downloading ", "bold cyan"), overflow="ellipsis")
|
||||
self._text_cache = self.gen_title_text()
|
||||
self.live = Live(Group(self._text_cache, self.progress), refresh_per_second=10)
|
||||
|
||||
def get_callback(self, total: int, desc: str):
|
||||
if not self.started:
|
||||
self.live.start()
|
||||
self.started = True
|
||||
|
||||
task = self.progress.add_task(f"[cyan]{desc}", total=total)
|
||||
|
||||
def _callback_update(x: int):
|
||||
self.progress.update(task, advance=x)
|
||||
self.live.update(Group(self.get_title_text(), self.progress))
|
||||
|
||||
def _callback_done():
|
||||
self.progress.update(task, visible=False)
|
||||
|
||||
return Handle(_callback_update, _callback_done)
|
||||
|
||||
def cleanup(self):
|
||||
if self.started:
|
||||
self.live.stop()
|
||||
|
||||
def add_title(self, title: str):
|
||||
self.task_titles.append(title.strip())
|
||||
self._text_cache = self.gen_title_text()
|
||||
|
||||
def remove_title(self, title: str):
|
||||
self.task_titles.remove(title.strip())
|
||||
self._text_cache = self.gen_title_text()
|
||||
|
||||
def gen_title_text(self) -> Rule:
|
||||
titles = ", ".join(self.task_titles[:3])
|
||||
if len(self.task_titles) > 3:
|
||||
titles += "..."
|
||||
t = self.prefix + Text(titles)
|
||||
return Rule(t)
|
||||
|
||||
def get_title_text(self) -> Rule:
|
||||
return self._text_cache
|
||||
|
||||
|
||||
@dataclass(slots=True)
|
||||
class Handle:
|
||||
update: Callable[[int], None]
|
||||
done: Callable[[], None]
|
||||
|
||||
def __enter__(self):
|
||||
return self.update
|
||||
|
||||
def __exit__(self, *_):
|
||||
self.done()
|
||||
|
||||
|
||||
# global instance
|
||||
_p = ProgressManager()
|
||||
|
||||
|
||||
def get_progress_callback(enabled: bool, total: int, desc: str) -> Handle:
|
||||
global _p
|
||||
if not enabled:
|
||||
return Handle(lambda _: None, lambda: None)
|
||||
return _p.get_callback(total, desc)
|
||||
|
||||
|
||||
def add_title(title: str):
|
||||
global _p
|
||||
_p.add_title(title)
|
||||
|
||||
|
||||
def remove_title(title: str):
|
||||
global _p
|
||||
_p.remove_title(title)
|
||||
|
||||
|
||||
def clear_progress():
|
||||
global _p
|
||||
_p.cleanup()
|
||||
|
|
@ -0,0 +1,3 @@
|
|||
from .cli import rip
|
||||
|
||||
__all__ = ["rip"]
|
||||
|
|
@ -0,0 +1,439 @@
|
|||
import asyncio
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
import shutil
|
||||
import subprocess
|
||||
from functools import wraps
|
||||
from typing import Any
|
||||
|
||||
import aiofiles
|
||||
import aiohttp
|
||||
import click
|
||||
from click_help_colors import HelpColorsGroup # type: ignore
|
||||
from rich.logging import RichHandler
|
||||
from rich.markdown import Markdown
|
||||
from rich.prompt import Confirm
|
||||
from rich.traceback import install
|
||||
|
||||
from .. import __version__, db
|
||||
from ..config import DEFAULT_CONFIG_PATH, Config, OutdatedConfigError, set_user_defaults
|
||||
from ..console import console
|
||||
from .main import Main
|
||||
|
||||
|
||||
def coro(f):
|
||||
@wraps(f)
|
||||
def wrapper(*args, **kwargs):
|
||||
return asyncio.run(f(*args, **kwargs))
|
||||
|
||||
return wrapper
|
||||
|
||||
|
||||
@click.group(
|
||||
cls=HelpColorsGroup,
|
||||
help_headers_color="yellow",
|
||||
help_options_color="green",
|
||||
)
|
||||
@click.version_option(version=__version__)
|
||||
@click.option(
|
||||
"--config-path",
|
||||
default=DEFAULT_CONFIG_PATH,
|
||||
help="Path to the configuration file",
|
||||
type=click.Path(readable=True, writable=True),
|
||||
)
|
||||
@click.option(
|
||||
"-f",
|
||||
"--folder",
|
||||
help="The folder to download items into.",
|
||||
type=click.Path(file_okay=False, dir_okay=True),
|
||||
)
|
||||
@click.option(
|
||||
"-ndb",
|
||||
"--no-db",
|
||||
help="Download items even if they have been logged in the database",
|
||||
default=False,
|
||||
is_flag=True,
|
||||
)
|
||||
@click.option(
|
||||
"-q",
|
||||
"--quality",
|
||||
help="The maximum quality allowed to download",
|
||||
type=click.IntRange(min=0, max=4),
|
||||
)
|
||||
@click.option(
|
||||
"-c",
|
||||
"--codec",
|
||||
help="Convert the downloaded files to an audio codec (ALAC, FLAC, MP3, AAC, or OGG)",
|
||||
)
|
||||
@click.option(
|
||||
"--no-progress",
|
||||
help="Do not show progress bars",
|
||||
is_flag=True,
|
||||
default=False,
|
||||
)
|
||||
@click.option(
|
||||
"-v",
|
||||
"--verbose",
|
||||
help="Enable verbose output (debug mode)",
|
||||
is_flag=True,
|
||||
)
|
||||
@click.pass_context
|
||||
def rip(ctx, config_path, folder, no_db, quality, codec, no_progress, verbose):
|
||||
"""Streamrip: the all in one music downloader."""
|
||||
global logger
|
||||
logging.basicConfig(
|
||||
level="INFO",
|
||||
format="%(message)s",
|
||||
datefmt="[%X]",
|
||||
handlers=[RichHandler()],
|
||||
)
|
||||
logger = logging.getLogger("streamrip")
|
||||
if verbose:
|
||||
install(
|
||||
console=console,
|
||||
suppress=[
|
||||
click,
|
||||
],
|
||||
show_locals=True,
|
||||
locals_hide_sunder=False,
|
||||
)
|
||||
logger.setLevel(logging.DEBUG)
|
||||
logger.debug("Showing all debug logs")
|
||||
else:
|
||||
install(console=console, suppress=[click, asyncio], max_frames=1)
|
||||
logger.setLevel(logging.INFO)
|
||||
|
||||
if not os.path.isfile(config_path):
|
||||
console.print(
|
||||
f"No file found at [bold cyan]{config_path}[/bold cyan], creating default config.",
|
||||
)
|
||||
set_user_defaults(config_path)
|
||||
|
||||
# pass to subcommands
|
||||
ctx.ensure_object(dict)
|
||||
ctx.obj["config_path"] = config_path
|
||||
|
||||
try:
|
||||
c = Config(config_path)
|
||||
except OutdatedConfigError as e:
|
||||
console.print(e)
|
||||
console.print("Auto-updating config file...")
|
||||
Config.update_file(config_path)
|
||||
c = Config(config_path)
|
||||
except Exception as e:
|
||||
console.print(
|
||||
f"Error loading config from [bold cyan]{config_path}[/bold cyan]: {e}\n"
|
||||
"Try running [bold]rip config reset[/bold]",
|
||||
)
|
||||
ctx.obj["config"] = None
|
||||
return
|
||||
|
||||
# set session config values to command line args
|
||||
if no_db:
|
||||
c.session.database.downloads_enabled = False
|
||||
if folder is not None:
|
||||
c.session.downloads.folder = folder
|
||||
|
||||
if quality is not None:
|
||||
c.session.qobuz.quality = quality
|
||||
c.session.tidal.quality = quality
|
||||
c.session.deezer.quality = quality
|
||||
c.session.soundcloud.quality = quality
|
||||
|
||||
if codec is not None:
|
||||
c.session.conversion.enabled = True
|
||||
assert codec.upper() in ("ALAC", "FLAC", "OGG", "MP3", "AAC")
|
||||
c.session.conversion.codec = codec.upper()
|
||||
|
||||
if no_progress:
|
||||
c.session.cli.progress_bars = False
|
||||
|
||||
ctx.obj["config"] = c
|
||||
|
||||
|
||||
@rip.command()
|
||||
@click.argument("urls", nargs=-1, required=True)
|
||||
@click.pass_context
|
||||
@coro
|
||||
async def url(ctx, urls):
|
||||
"""Download content from URLs."""
|
||||
if ctx.obj["config"] is None:
|
||||
return
|
||||
with ctx.obj["config"] as cfg:
|
||||
cfg: Config
|
||||
updates = cfg.session.misc.check_for_updates
|
||||
if updates:
|
||||
# Run in background
|
||||
version_coro = asyncio.create_task(latest_streamrip_version())
|
||||
else:
|
||||
version_coro = None
|
||||
|
||||
async with Main(cfg) as main:
|
||||
await main.add_all(urls)
|
||||
await main.resolve()
|
||||
await main.rip()
|
||||
|
||||
if version_coro is not None:
|
||||
latest_version, notes = await version_coro
|
||||
if latest_version != __version__:
|
||||
console.print(
|
||||
f"\n[green]A new version of streamrip [cyan]v{latest_version}[/cyan]"
|
||||
" is available! Run [white][bold]pip3 install streamrip --upgrade[/bold][/white]"
|
||||
" to update.[/green]\n"
|
||||
)
|
||||
|
||||
console.print(Markdown(notes))
|
||||
|
||||
|
||||
@rip.command()
|
||||
@click.argument(
|
||||
"path",
|
||||
required=True,
|
||||
type=click.Path(exists=True, readable=True, file_okay=True, dir_okay=False),
|
||||
)
|
||||
@click.pass_context
|
||||
@coro
|
||||
async def file(ctx, path):
|
||||
"""Download content from URLs in a file.
|
||||
|
||||
Example usage:
|
||||
|
||||
rip file urls.txt
|
||||
"""
|
||||
with ctx.obj["config"] as cfg:
|
||||
async with Main(cfg) as main:
|
||||
async with aiofiles.open(path, "r") as f:
|
||||
content = await f.read()
|
||||
try:
|
||||
items: Any = json.loads(content)
|
||||
loaded = True
|
||||
except json.JSONDecodeError:
|
||||
items = content.split()
|
||||
loaded = False
|
||||
if loaded:
|
||||
console.print(
|
||||
f"Detected json file. Loading [yellow]{len(items)}[/yellow] items"
|
||||
)
|
||||
await main.add_all_by_id(
|
||||
[(i["source"], i["media_type"], i["id"]) for i in items]
|
||||
)
|
||||
else:
|
||||
s = set(items)
|
||||
if len(s) < len(items):
|
||||
console.print(
|
||||
f"Found [orange]{len(items)-len(s)}[/orange] repeated URLs!"
|
||||
)
|
||||
items = list(s)
|
||||
console.print(
|
||||
f"Detected list of urls. Loading [yellow]{len(items)}[/yellow] items"
|
||||
)
|
||||
await main.add_all(items)
|
||||
|
||||
await main.resolve()
|
||||
await main.rip()
|
||||
|
||||
|
||||
@rip.group()
|
||||
def config():
|
||||
"""Manage configuration files."""
|
||||
|
||||
|
||||
@config.command("open")
|
||||
@click.option("-v", "--vim", help="Open in (Neo)Vim", is_flag=True)
|
||||
@click.pass_context
|
||||
def config_open(ctx, vim):
|
||||
"""Open the config file in a text editor."""
|
||||
config_path = ctx.obj["config_path"]
|
||||
|
||||
console.print(f"Opening file at [bold cyan]{config_path}")
|
||||
if vim:
|
||||
if shutil.which("nvim") is not None:
|
||||
subprocess.run(["nvim", config_path])
|
||||
elif shutil.which("vim") is not None:
|
||||
subprocess.run(["vim", config_path])
|
||||
else:
|
||||
logger.error("Could not find nvim or vim. Using default launcher.")
|
||||
click.launch(config_path)
|
||||
else:
|
||||
click.launch(config_path)
|
||||
|
||||
|
||||
@config.command("reset")
|
||||
@click.option("-y", "--yes", help="Don't ask for confirmation.", is_flag=True)
|
||||
@click.pass_context
|
||||
def config_reset(ctx, yes):
|
||||
"""Reset the config file."""
|
||||
config_path = ctx.obj["config_path"]
|
||||
if not yes:
|
||||
if not Confirm.ask(
|
||||
f"Are you sure you want to reset the config file at {config_path}?",
|
||||
):
|
||||
console.print("[green]Reset aborted")
|
||||
return
|
||||
|
||||
set_user_defaults(config_path)
|
||||
console.print(f"Reset the config file at [bold cyan]{config_path}!")
|
||||
|
||||
|
||||
@config.command("path")
|
||||
@click.pass_context
|
||||
def config_path(ctx):
|
||||
"""Display the path of the config file."""
|
||||
config_path = ctx.obj["config_path"]
|
||||
console.print(f"Config path: [bold cyan]'{config_path}'")
|
||||
|
||||
|
||||
@rip.group()
|
||||
def database():
|
||||
"""View and modify the downloads and failed downloads databases."""
|
||||
|
||||
|
||||
@database.command("browse")
|
||||
@click.argument("table")
|
||||
@click.pass_context
|
||||
def database_browse(ctx, table):
|
||||
"""Browse the contents of a table.
|
||||
|
||||
Available tables:
|
||||
|
||||
* Downloads
|
||||
|
||||
* Failed
|
||||
"""
|
||||
from rich.table import Table
|
||||
|
||||
cfg: Config = ctx.obj["config"]
|
||||
|
||||
if table.lower() == "downloads":
|
||||
downloads = db.Downloads(cfg.session.database.downloads_path)
|
||||
t = Table(title="Downloads database")
|
||||
t.add_column("Row")
|
||||
t.add_column("ID")
|
||||
for i, row in enumerate(downloads.all()):
|
||||
t.add_row(f"{i:02}", *row)
|
||||
console.print(t)
|
||||
|
||||
elif table.lower() == "failed":
|
||||
failed = db.Failed(cfg.session.database.failed_downloads_path)
|
||||
t = Table(title="Failed downloads database")
|
||||
t.add_column("Source")
|
||||
t.add_column("Media Type")
|
||||
t.add_column("ID")
|
||||
for i, row in enumerate(failed.all()):
|
||||
t.add_row(f"{i:02}", *row)
|
||||
console.print(t)
|
||||
|
||||
else:
|
||||
console.print(
|
||||
f"[red]Invalid database[/red] [bold]{table}[/bold]. [red]Choose[/red] [bold]downloads "
|
||||
"[red]or[/red] failed[/bold].",
|
||||
)
|
||||
|
||||
|
||||
@rip.command()
|
||||
@click.option(
|
||||
"-f",
|
||||
"--first",
|
||||
help="Automatically download the first search result without showing the menu.",
|
||||
is_flag=True,
|
||||
)
|
||||
@click.option(
|
||||
"-o",
|
||||
"--output-file",
|
||||
help="Write search results to a file instead of showing interactive menu.",
|
||||
type=click.Path(writable=True),
|
||||
)
|
||||
@click.option(
|
||||
"-n",
|
||||
"--num-results",
|
||||
help="Maximum number of search results to show",
|
||||
default=100,
|
||||
type=click.IntRange(min=1),
|
||||
)
|
||||
@click.argument("source", required=True)
|
||||
@click.argument("media-type", required=True)
|
||||
@click.argument("query", required=True)
|
||||
@click.pass_context
|
||||
@coro
|
||||
async def search(ctx, first, output_file, num_results, source, media_type, query):
|
||||
"""Search for content using a specific source.
|
||||
|
||||
Example:
|
||||
|
||||
rip search qobuz album 'rumours'
|
||||
"""
|
||||
if first and output_file:
|
||||
console.print("Cannot choose --first and --output-file!")
|
||||
return
|
||||
with ctx.obj["config"] as cfg:
|
||||
async with Main(cfg) as main:
|
||||
if first:
|
||||
await main.search_take_first(source, media_type, query)
|
||||
elif output_file:
|
||||
await main.search_output_file(
|
||||
source, media_type, query, output_file, num_results
|
||||
)
|
||||
else:
|
||||
await main.search_interactive(source, media_type, query)
|
||||
await main.resolve()
|
||||
await main.rip()
|
||||
|
||||
|
||||
@rip.command()
|
||||
@click.option("-s", "--source", help="The source to search tracks on.")
|
||||
@click.option(
|
||||
"-fs",
|
||||
"--fallback-source",
|
||||
help="The source to search tracks on if no results were found with the main source.",
|
||||
)
|
||||
@click.argument("url", required=True)
|
||||
@click.pass_context
|
||||
@coro
|
||||
async def lastfm(ctx, source, fallback_source, url):
|
||||
"""Download tracks from a last.fm playlist."""
|
||||
config = ctx.obj["config"]
|
||||
if source is not None:
|
||||
config.session.lastfm.source = source
|
||||
if fallback_source is not None:
|
||||
config.session.lastfm.fallback_source = fallback_source
|
||||
with config as cfg:
|
||||
async with Main(cfg) as main:
|
||||
await main.resolve_lastfm(url)
|
||||
await main.rip()
|
||||
|
||||
|
||||
@rip.command()
|
||||
@click.argument("source")
|
||||
@click.argument("media-type")
|
||||
@click.argument("id")
|
||||
@click.pass_context
|
||||
@coro
|
||||
async def id(ctx, source, media_type, id):
|
||||
"""Download an item by ID."""
|
||||
with ctx.obj["config"] as cfg:
|
||||
async with Main(cfg) as main:
|
||||
await main.add_by_id(source, media_type, id)
|
||||
await main.resolve()
|
||||
await main.rip()
|
||||
|
||||
|
||||
async def latest_streamrip_version() -> tuple[str, str | None]:
|
||||
async with aiohttp.ClientSession() as s:
|
||||
async with s.get("https://pypi.org/pypi/streamrip/json") as resp:
|
||||
data = await resp.json()
|
||||
version = data["info"]["version"]
|
||||
|
||||
if version == __version__:
|
||||
return version, None
|
||||
|
||||
async with s.get(
|
||||
"https://api.github.com/repos/nathom/streamrip/releases/latest"
|
||||
) as resp:
|
||||
json = await resp.json()
|
||||
notes = json["body"]
|
||||
return version, notes
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
rip()
|
||||
|
|
@ -0,0 +1,289 @@
|
|||
import asyncio
|
||||
import json
|
||||
import logging
|
||||
import platform
|
||||
|
||||
import aiofiles
|
||||
|
||||
from .. import db
|
||||
from ..client import Client, DeezerClient, QobuzClient, SoundcloudClient, TidalClient
|
||||
from ..config import Config
|
||||
from ..console import console
|
||||
from ..media import (
|
||||
Media,
|
||||
Pending,
|
||||
PendingAlbum,
|
||||
PendingArtist,
|
||||
PendingLabel,
|
||||
PendingLastfmPlaylist,
|
||||
PendingPlaylist,
|
||||
PendingSingle,
|
||||
remove_artwork_tempdirs,
|
||||
)
|
||||
from ..metadata import SearchResults
|
||||
from ..progress import clear_progress
|
||||
from .parse_url import parse_url
|
||||
from .prompter import get_prompter
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
|
||||
class Main:
|
||||
"""Provides all of the functionality called into by the CLI.
|
||||
|
||||
* Logs in to Clients and prompts for credentials
|
||||
* Handles output logging
|
||||
* Handles downloading Media
|
||||
* Handles interactive search
|
||||
|
||||
User input (urls) -> Main --> Download files & Output messages to terminal
|
||||
"""
|
||||
|
||||
def __init__(self, config: Config):
|
||||
# Data pipeline:
|
||||
# input URL -> (URL) -> (Pending) -> (Media) -> (Downloadable) -> audio file
|
||||
self.pending: list[Pending] = []
|
||||
self.media: list[Media] = []
|
||||
self.config = config
|
||||
self.clients: dict[str, Client] = {
|
||||
"qobuz": QobuzClient(config),
|
||||
"tidal": TidalClient(config),
|
||||
"deezer": DeezerClient(config),
|
||||
"soundcloud": SoundcloudClient(config),
|
||||
}
|
||||
|
||||
self.database: db.Database
|
||||
|
||||
c = self.config.session.database
|
||||
if c.downloads_enabled:
|
||||
downloads_db = db.Downloads(c.downloads_path)
|
||||
else:
|
||||
downloads_db = db.Dummy()
|
||||
|
||||
if c.failed_downloads_enabled:
|
||||
failed_downloads_db = db.Failed(c.failed_downloads_path)
|
||||
else:
|
||||
failed_downloads_db = db.Dummy()
|
||||
|
||||
self.database = db.Database(downloads_db, failed_downloads_db)
|
||||
|
||||
async def add(self, url: str):
|
||||
"""Add url as a pending item.
|
||||
|
||||
Do not `asyncio.gather` calls to this! Use `add_all` for concurrency.
|
||||
"""
|
||||
parsed = parse_url(url)
|
||||
if parsed is None:
|
||||
raise Exception(f"Unable to parse url {url}")
|
||||
|
||||
client = await self.get_logged_in_client(parsed.source)
|
||||
self.pending.append(
|
||||
await parsed.into_pending(client, self.config, self.database),
|
||||
)
|
||||
logger.debug("Added url=%s", url)
|
||||
|
||||
async def add_by_id(self, source: str, media_type: str, id: str):
|
||||
client = await self.get_logged_in_client(source)
|
||||
self._add_by_id_client(client, media_type, id)
|
||||
|
||||
async def add_all_by_id(self, info: list[tuple[str, str, str]]):
|
||||
sources = set(s for s, _, _ in info)
|
||||
clients = {s: await self.get_logged_in_client(s) for s in sources}
|
||||
for source, media_type, id in info:
|
||||
self._add_by_id_client(clients[source], media_type, id)
|
||||
|
||||
def _add_by_id_client(self, client: Client, media_type: str, id: str):
|
||||
if media_type == "track":
|
||||
item = PendingSingle(id, client, self.config, self.database)
|
||||
elif media_type == "album":
|
||||
item = PendingAlbum(id, client, self.config, self.database)
|
||||
elif media_type == "playlist":
|
||||
item = PendingPlaylist(id, client, self.config, self.database)
|
||||
elif media_type == "label":
|
||||
item = PendingLabel(id, client, self.config, self.database)
|
||||
elif media_type == "artist":
|
||||
item = PendingArtist(id, client, self.config, self.database)
|
||||
else:
|
||||
raise Exception(media_type)
|
||||
|
||||
self.pending.append(item)
|
||||
|
||||
async def add_all(self, urls: list[str]):
|
||||
"""Add multiple urls concurrently as pending items."""
|
||||
parsed = [parse_url(url) for url in urls]
|
||||
url_client_pairs = []
|
||||
for i, p in enumerate(parsed):
|
||||
if p is None:
|
||||
console.print(
|
||||
f"[red]Found invalid url [cyan]{urls[i]}[/cyan], skipping.",
|
||||
)
|
||||
continue
|
||||
url_client_pairs.append((p, await self.get_logged_in_client(p.source)))
|
||||
|
||||
pendings = await asyncio.gather(
|
||||
*[
|
||||
url.into_pending(client, self.config, self.database)
|
||||
for url, client in url_client_pairs
|
||||
],
|
||||
)
|
||||
self.pending.extend(pendings)
|
||||
|
||||
async def get_logged_in_client(self, source: str):
|
||||
"""Return a functioning client instance for `source`."""
|
||||
client = self.clients.get(source)
|
||||
if client is None:
|
||||
raise Exception(
|
||||
f"No client named {source} available. Only have {self.clients.keys()}",
|
||||
)
|
||||
if not client.logged_in:
|
||||
prompter = get_prompter(client, self.config)
|
||||
if not prompter.has_creds():
|
||||
# Get credentials from user and log into client
|
||||
await prompter.prompt_and_login()
|
||||
prompter.save()
|
||||
else:
|
||||
with console.status(f"[cyan]Logging into {source}", spinner="dots"):
|
||||
# Log into client using credentials from config
|
||||
await client.login()
|
||||
|
||||
assert client.logged_in
|
||||
return client
|
||||
|
||||
async def resolve(self):
|
||||
"""Resolve all currently pending items."""
|
||||
with console.status("Resolving URLs...", spinner="dots"):
|
||||
coros = [p.resolve() for p in self.pending]
|
||||
new_media: list[Media] = [
|
||||
m for m in await asyncio.gather(*coros) if m is not None
|
||||
]
|
||||
|
||||
self.media.extend(new_media)
|
||||
self.pending.clear()
|
||||
|
||||
async def rip(self):
|
||||
"""Download all resolved items."""
|
||||
await asyncio.gather(*[item.rip() for item in self.media])
|
||||
|
||||
async def search_interactive(self, source: str, media_type: str, query: str):
|
||||
client = await self.get_logged_in_client(source)
|
||||
|
||||
with console.status(f"[bold]Searching {source}", spinner="dots"):
|
||||
pages = await client.search(media_type, query, limit=100)
|
||||
if len(pages) == 0:
|
||||
console.print(f"[red]No search results found for query {query}")
|
||||
return
|
||||
search_results = SearchResults.from_pages(source, media_type, pages)
|
||||
|
||||
if platform.system() == "Windows": # simple term menu not supported for windows
|
||||
from pick import pick
|
||||
|
||||
choices = pick(
|
||||
search_results.results,
|
||||
title=(
|
||||
f"{source.capitalize()} {media_type} search.\n"
|
||||
"Press SPACE to select, RETURN to download, CTRL-C to exit."
|
||||
),
|
||||
multiselect=True,
|
||||
min_selection_count=1,
|
||||
)
|
||||
assert isinstance(choices, list)
|
||||
|
||||
await self.add_all_by_id(
|
||||
[(source, media_type, item.id) for item, _ in choices],
|
||||
)
|
||||
|
||||
else:
|
||||
from simple_term_menu import TerminalMenu
|
||||
|
||||
menu = TerminalMenu(
|
||||
search_results.summaries(),
|
||||
preview_command=search_results.preview,
|
||||
preview_size=0.5,
|
||||
title=(
|
||||
f"Results for {media_type} '{query}' from {source.capitalize()}\n"
|
||||
"SPACE - select, ENTER - download, ESC - exit"
|
||||
),
|
||||
cycle_cursor=True,
|
||||
clear_screen=True,
|
||||
multi_select=True,
|
||||
)
|
||||
chosen_ind = menu.show()
|
||||
if chosen_ind is None:
|
||||
console.print("[yellow]No items chosen. Exiting.")
|
||||
else:
|
||||
choices = search_results.get_choices(chosen_ind)
|
||||
await self.add_all_by_id(
|
||||
[(source, item.media_type(), item.id) for item in choices],
|
||||
)
|
||||
|
||||
async def search_take_first(self, source: str, media_type: str, query: str):
|
||||
client = await self.get_logged_in_client(source)
|
||||
with console.status(f"[bold]Searching {source}", spinner="dots"):
|
||||
pages = await client.search(media_type, query, limit=1)
|
||||
|
||||
if len(pages) == 0:
|
||||
console.print(f"[red]No search results found for query {query}")
|
||||
return
|
||||
|
||||
search_results = SearchResults.from_pages(source, media_type, pages)
|
||||
assert len(search_results.results) > 0
|
||||
first = search_results.results[0]
|
||||
await self.add_by_id(source, first.media_type(), first.id)
|
||||
|
||||
async def search_output_file(
|
||||
self, source: str, media_type: str, query: str, filepath: str, limit: int
|
||||
):
|
||||
client = await self.get_logged_in_client(source)
|
||||
with console.status(f"[bold]Searching {source}", spinner="dots"):
|
||||
pages = await client.search(media_type, query, limit=limit)
|
||||
|
||||
if len(pages) == 0:
|
||||
console.print(f"[red]No search results found for query {query}")
|
||||
return
|
||||
|
||||
search_results = SearchResults.from_pages(source, media_type, pages)
|
||||
file_contents = json.dumps(search_results.as_list(source), indent=4)
|
||||
async with aiofiles.open(filepath, "w") as f:
|
||||
await f.write(file_contents)
|
||||
|
||||
console.print(
|
||||
f"Wrote [purple]{len(search_results.results)}[/purple] results to [cyan]{filepath} as JSON!"
|
||||
)
|
||||
|
||||
async def resolve_lastfm(self, playlist_url: str):
|
||||
"""Resolve a last.fm playlist."""
|
||||
c = self.config.session.lastfm
|
||||
client = await self.get_logged_in_client(c.source)
|
||||
|
||||
if len(c.fallback_source) > 0:
|
||||
fallback_client = await self.get_logged_in_client(c.fallback_source)
|
||||
else:
|
||||
fallback_client = None
|
||||
|
||||
pending_playlist = PendingLastfmPlaylist(
|
||||
playlist_url,
|
||||
client,
|
||||
fallback_client,
|
||||
self.config,
|
||||
self.database,
|
||||
)
|
||||
playlist = await pending_playlist.resolve()
|
||||
|
||||
if playlist is not None:
|
||||
self.media.append(playlist)
|
||||
|
||||
async def __aenter__(self):
|
||||
return self
|
||||
|
||||
async def __aexit__(self, *_):
|
||||
# Ensure all client sessions are closed
|
||||
for client in self.clients.values():
|
||||
if hasattr(client, "session"):
|
||||
await client.session.close()
|
||||
|
||||
# close global progress bar manager
|
||||
clear_progress()
|
||||
# We remove artwork tempdirs here because multiple singles
|
||||
# may be able to share downloaded artwork in the same `rip` session
|
||||
# We don't know that a cover will not be used again until end of execution
|
||||
remove_artwork_tempdirs()
|
||||
|
|
@ -0,0 +1,237 @@
|
|||
from __future__ import annotations
|
||||
|
||||
import logging
|
||||
import re
|
||||
from abc import ABC, abstractmethod
|
||||
|
||||
from ..client import Client, SoundcloudClient
|
||||
from ..config import Config
|
||||
from ..db import Database
|
||||
from ..media import (
|
||||
Pending,
|
||||
PendingAlbum,
|
||||
PendingArtist,
|
||||
PendingLabel,
|
||||
PendingPlaylist,
|
||||
PendingSingle,
|
||||
)
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
URL_REGEX = re.compile(
|
||||
r"https?://(?:www|open|play|listen)?\.?(qobuz|tidal|deezer)\.com(?:(?:/(album|artist|track|playlist|video|label))|(?:\/[-\w]+?))+\/([-\w]+)",
|
||||
)
|
||||
SOUNDCLOUD_URL_REGEX = re.compile(r"https://soundcloud.com/[-\w:/]+")
|
||||
LASTFM_URL_REGEX = re.compile(r"https://www.last.fm/user/\w+/playlists/\w+")
|
||||
QOBUZ_INTERPRETER_URL_REGEX = re.compile(
|
||||
r"https?://www\.qobuz\.com/\w\w-\w\w/interpreter/[-\w]+/([-\w]+)",
|
||||
)
|
||||
YOUTUBE_URL_REGEX = re.compile(r"https://www\.youtube\.com/watch\?v=[-\w]+")
|
||||
|
||||
|
||||
class URL(ABC):
|
||||
match: re.Match
|
||||
source: str
|
||||
|
||||
def __init__(self, match: re.Match, source: str):
|
||||
self.match = match
|
||||
self.source = source
|
||||
|
||||
@classmethod
|
||||
@abstractmethod
|
||||
def from_str(cls, url: str) -> URL | None:
|
||||
raise NotImplementedError
|
||||
|
||||
@abstractmethod
|
||||
async def into_pending(
|
||||
self,
|
||||
client: Client,
|
||||
config: Config,
|
||||
db: Database,
|
||||
) -> Pending:
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
class GenericURL(URL):
|
||||
@classmethod
|
||||
def from_str(cls, url: str) -> URL | None:
|
||||
generic_url = URL_REGEX.match(url)
|
||||
if generic_url is None:
|
||||
return None
|
||||
|
||||
source, media_type, item_id = generic_url.groups()
|
||||
if source is None or media_type is None or item_id is None:
|
||||
return None
|
||||
|
||||
return cls(generic_url, source)
|
||||
|
||||
async def into_pending(
|
||||
self,
|
||||
client: Client,
|
||||
config: Config,
|
||||
db: Database,
|
||||
) -> Pending:
|
||||
source, media_type, item_id = self.match.groups()
|
||||
assert client.source == source
|
||||
|
||||
if media_type == "track":
|
||||
return PendingSingle(item_id, client, config, db)
|
||||
elif media_type == "album":
|
||||
return PendingAlbum(item_id, client, config, db)
|
||||
elif media_type == "playlist":
|
||||
return PendingPlaylist(item_id, client, config, db)
|
||||
elif media_type == "artist":
|
||||
return PendingArtist(item_id, client, config, db)
|
||||
elif media_type == "label":
|
||||
return PendingLabel(item_id, client, config, db)
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
class QobuzInterpreterURL(URL):
|
||||
interpreter_artist_regex = re.compile(r"getSimilarArtist\(\s*'(\w+)'")
|
||||
|
||||
@classmethod
|
||||
def from_str(cls, url: str) -> URL | None:
|
||||
qobuz_interpreter_url = QOBUZ_INTERPRETER_URL_REGEX.match(url)
|
||||
if qobuz_interpreter_url is None:
|
||||
return None
|
||||
|
||||
return cls(qobuz_interpreter_url, "qobuz")
|
||||
|
||||
async def into_pending(
|
||||
self,
|
||||
client: Client,
|
||||
config: Config,
|
||||
db: Database,
|
||||
) -> Pending:
|
||||
url = self.match.group(0)
|
||||
possible_id = self.match.group(1)
|
||||
if possible_id.isdigit():
|
||||
logger.debug("Found artist ID %s in interpreter url %s", possible_id, url)
|
||||
artist_id = possible_id
|
||||
else:
|
||||
artist_id = await self.extract_interpreter_url(url, client)
|
||||
return PendingArtist(artist_id, client, config, db)
|
||||
|
||||
@staticmethod
|
||||
async def extract_interpreter_url(url: str, client: Client) -> str:
|
||||
"""Extract artist ID from a Qobuz interpreter url.
|
||||
|
||||
:param url: Urls of the form "https://www.qobuz.com/us-en/interpreter/{artist}/download-streaming-albums"
|
||||
:type url: str
|
||||
:rtype: str
|
||||
"""
|
||||
async with client.session.get(url) as resp:
|
||||
match = QobuzInterpreterURL.interpreter_artist_regex.search(
|
||||
await resp.text(),
|
||||
)
|
||||
|
||||
if match:
|
||||
return match.group(1)
|
||||
|
||||
raise Exception(
|
||||
"Unable to extract artist id from interpreter url. Use a "
|
||||
"url that contains an artist id.",
|
||||
)
|
||||
|
||||
|
||||
class DeezerDynamicURL(URL):
|
||||
standard_link_re = re.compile(
|
||||
r"https://www\.deezer\.com/[a-z]{2}/(album|artist|playlist|track)/(\d+)"
|
||||
)
|
||||
dynamic_link_re = re.compile(r"https://deezer\.page\.link/\w+")
|
||||
|
||||
@classmethod
|
||||
def from_str(cls, url: str) -> URL | None:
|
||||
match = cls.dynamic_link_re.match(url)
|
||||
if match is None:
|
||||
return None
|
||||
|
||||
return cls(match, "deezer")
|
||||
|
||||
async def into_pending(
|
||||
self,
|
||||
client: Client,
|
||||
config: Config,
|
||||
db: Database,
|
||||
) -> Pending:
|
||||
url = self.match.group(0) # entire dynamic link
|
||||
media_type, item_id = await self._extract_info_from_dynamic_link(url, client)
|
||||
if media_type == "track":
|
||||
return PendingSingle(item_id, client, config, db)
|
||||
elif media_type == "album":
|
||||
return PendingAlbum(item_id, client, config, db)
|
||||
elif media_type == "playlist":
|
||||
return PendingPlaylist(item_id, client, config, db)
|
||||
elif media_type == "artist":
|
||||
return PendingArtist(item_id, client, config, db)
|
||||
elif media_type == "label":
|
||||
return PendingLabel(item_id, client, config, db)
|
||||
raise NotImplementedError
|
||||
|
||||
@classmethod
|
||||
async def _extract_info_from_dynamic_link(
|
||||
cls, url: str, client: Client
|
||||
) -> tuple[str, str]:
|
||||
"""Extract the item's type and ID from a dynamic link.
|
||||
|
||||
:param url:
|
||||
:type url: str
|
||||
:rtype: Tuple[str, str] (media type, item id)
|
||||
"""
|
||||
async with client.session.get(url) as resp:
|
||||
match = cls.standard_link_re.search(await resp.text())
|
||||
|
||||
if match:
|
||||
return match.group(1), match.group(2)
|
||||
|
||||
raise Exception("Unable to extract Deezer dynamic link.")
|
||||
|
||||
|
||||
class SoundcloudURL(URL):
|
||||
source = "soundcloud"
|
||||
|
||||
def __init__(self, url: str):
|
||||
self.url = url
|
||||
|
||||
async def into_pending(
|
||||
self,
|
||||
client: SoundcloudClient,
|
||||
config: Config,
|
||||
db: Database,
|
||||
) -> Pending:
|
||||
resolved = await client.resolve_url(self.url)
|
||||
media_type = resolved["kind"]
|
||||
item_id = str(resolved["id"])
|
||||
if media_type == "track":
|
||||
return PendingSingle(item_id, client, config, db)
|
||||
elif media_type == "playlist":
|
||||
return PendingPlaylist(item_id, client, config, db)
|
||||
else:
|
||||
raise NotImplementedError(media_type)
|
||||
|
||||
@classmethod
|
||||
def from_str(cls, url: str):
|
||||
soundcloud_url = SOUNDCLOUD_URL_REGEX.match(url)
|
||||
if soundcloud_url is None:
|
||||
return None
|
||||
return cls(soundcloud_url.group(0))
|
||||
|
||||
|
||||
def parse_url(url: str) -> URL | None:
|
||||
"""Return a URL type given a url string.
|
||||
|
||||
Args:
|
||||
----
|
||||
url (str): Url to parse
|
||||
|
||||
Returns: A URL type, or None if nothing matched.
|
||||
"""
|
||||
url = url.strip()
|
||||
parsed_urls: list[URL | None] = [
|
||||
GenericURL.from_str(url),
|
||||
QobuzInterpreterURL.from_str(url),
|
||||
SoundcloudURL.from_str(url),
|
||||
DeezerDynamicURL.from_str(url),
|
||||
# TODO: the rest of the url types
|
||||
]
|
||||
return next((u for u in parsed_urls if u is not None), None)
|
||||
|
|
@ -0,0 +1,218 @@
|
|||
import asyncio
|
||||
import hashlib
|
||||
import logging
|
||||
import time
|
||||
from abc import ABC, abstractmethod
|
||||
|
||||
from click import launch
|
||||
from rich.prompt import Prompt
|
||||
|
||||
from ..client import Client, DeezerClient, QobuzClient, SoundcloudClient, TidalClient
|
||||
from ..config import Config
|
||||
from ..console import console
|
||||
from ..exceptions import AuthenticationError, MissingCredentialsError
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
|
||||
class CredentialPrompter(ABC):
|
||||
client: Client
|
||||
|
||||
def __init__(self, config: Config, client: Client):
|
||||
self.config = config
|
||||
self.client = self.type_check_client(client)
|
||||
|
||||
@abstractmethod
|
||||
def has_creds(self) -> bool:
|
||||
raise NotImplementedError
|
||||
|
||||
@abstractmethod
|
||||
async def prompt_and_login(self):
|
||||
"""Prompt for credentials in the appropriate way,
|
||||
and save them to the configuration.
|
||||
"""
|
||||
raise NotImplementedError
|
||||
|
||||
@abstractmethod
|
||||
def save(self):
|
||||
"""Save current config to file"""
|
||||
raise NotImplementedError
|
||||
|
||||
@abstractmethod
|
||||
def type_check_client(self, client: Client):
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
class QobuzPrompter(CredentialPrompter):
|
||||
client: QobuzClient
|
||||
|
||||
def has_creds(self) -> bool:
|
||||
c = self.config.session.qobuz
|
||||
return c.email_or_userid != "" and c.password_or_token != ""
|
||||
|
||||
async def prompt_and_login(self):
|
||||
if not self.has_creds():
|
||||
self._prompt_creds_and_set_session_config()
|
||||
|
||||
while True:
|
||||
try:
|
||||
await self.client.login()
|
||||
break
|
||||
except AuthenticationError:
|
||||
console.print("[yellow]Invalid credentials, try again.")
|
||||
self._prompt_creds_and_set_session_config()
|
||||
except MissingCredentialsError:
|
||||
self._prompt_creds_and_set_session_config()
|
||||
|
||||
def _prompt_creds_and_set_session_config(self):
|
||||
email = Prompt.ask("Enter your Qobuz email")
|
||||
pwd_input = Prompt.ask("Enter your Qobuz password (invisible)", password=True)
|
||||
|
||||
pwd = hashlib.md5(pwd_input.encode("utf-8")).hexdigest()
|
||||
console.print(
|
||||
f"[green]Credentials saved to config file at [bold cyan]{self.config.path}",
|
||||
)
|
||||
c = self.config.session.qobuz
|
||||
c.use_auth_token = False
|
||||
c.email_or_userid = email
|
||||
c.password_or_token = pwd
|
||||
|
||||
def save(self):
|
||||
c = self.config.session.qobuz
|
||||
cf = self.config.file.qobuz
|
||||
cf.use_auth_token = False
|
||||
cf.email_or_userid = c.email_or_userid
|
||||
cf.password_or_token = c.password_or_token
|
||||
self.config.file.set_modified()
|
||||
|
||||
def type_check_client(self, client) -> QobuzClient:
|
||||
assert isinstance(client, QobuzClient)
|
||||
return client
|
||||
|
||||
|
||||
class TidalPrompter(CredentialPrompter):
|
||||
timeout_s: int = 600 # 5 mins to login
|
||||
client: TidalClient
|
||||
|
||||
def has_creds(self) -> bool:
|
||||
return len(self.config.session.tidal.access_token) > 0
|
||||
|
||||
async def prompt_and_login(self):
|
||||
device_code, uri = await self.client._get_device_code()
|
||||
login_link = f"https://{uri}"
|
||||
|
||||
console.print(
|
||||
f"Go to [blue underline]{login_link}[/blue underline] to log into Tidal within 5 minutes.",
|
||||
)
|
||||
launch(login_link)
|
||||
|
||||
start = time.time()
|
||||
elapsed = 0.0
|
||||
info = {}
|
||||
while elapsed < self.timeout_s:
|
||||
elapsed = time.time() - start
|
||||
status, info = await self.client._get_auth_status(device_code)
|
||||
if status == 2:
|
||||
# pending
|
||||
await asyncio.sleep(4)
|
||||
continue
|
||||
elif status == 0:
|
||||
# successful
|
||||
break
|
||||
else:
|
||||
raise Exception
|
||||
|
||||
c = self.config.session.tidal
|
||||
c.user_id = info["user_id"] # type: ignore
|
||||
c.country_code = info["country_code"] # type: ignore
|
||||
c.access_token = info["access_token"] # type: ignore
|
||||
c.refresh_token = info["refresh_token"] # type: ignore
|
||||
c.token_expiry = info["token_expiry"] # type: ignore
|
||||
|
||||
self.client._update_authorization_from_config()
|
||||
self.client.logged_in = True
|
||||
self.save()
|
||||
|
||||
def type_check_client(self, client) -> TidalClient:
|
||||
assert isinstance(client, TidalClient)
|
||||
return client
|
||||
|
||||
def save(self):
|
||||
c = self.config.session.tidal
|
||||
cf = self.config.file.tidal
|
||||
cf.user_id = c.user_id
|
||||
cf.country_code = c.country_code
|
||||
cf.access_token = c.access_token
|
||||
cf.refresh_token = c.refresh_token
|
||||
cf.token_expiry = c.token_expiry
|
||||
self.config.file.set_modified()
|
||||
|
||||
|
||||
class DeezerPrompter(CredentialPrompter):
|
||||
client: DeezerClient
|
||||
|
||||
def has_creds(self):
|
||||
c = self.config.session.deezer
|
||||
return c.arl != ""
|
||||
|
||||
async def prompt_and_login(self):
|
||||
if not self.has_creds():
|
||||
self._prompt_creds_and_set_session_config()
|
||||
while True:
|
||||
try:
|
||||
await self.client.login()
|
||||
break
|
||||
except AuthenticationError:
|
||||
console.print("[yellow]Invalid arl, try again.")
|
||||
self._prompt_creds_and_set_session_config()
|
||||
self.save()
|
||||
|
||||
def _prompt_creds_and_set_session_config(self):
|
||||
console.print(
|
||||
"If you're not sure how to find the ARL cookie, see the instructions at ",
|
||||
"[blue underline]https://github.com/nathom/streamrip/wiki/Finding-your-Deezer-ARL-Cookie",
|
||||
)
|
||||
c = self.config.session.deezer
|
||||
c.arl = Prompt.ask("Enter your [bold]ARL")
|
||||
|
||||
def save(self):
|
||||
c = self.config.session.deezer
|
||||
cf = self.config.file.deezer
|
||||
cf.arl = c.arl
|
||||
self.config.file.set_modified()
|
||||
console.print(
|
||||
f"[green]Credentials saved to config file at [bold cyan]{self.config.path}",
|
||||
)
|
||||
|
||||
def type_check_client(self, client) -> DeezerClient:
|
||||
assert isinstance(client, DeezerClient)
|
||||
return client
|
||||
|
||||
|
||||
class SoundcloudPrompter(CredentialPrompter):
|
||||
def has_creds(self) -> bool:
|
||||
return True
|
||||
|
||||
async def prompt_and_login(self):
|
||||
pass
|
||||
|
||||
def save(self):
|
||||
pass
|
||||
|
||||
def type_check_client(self, client) -> SoundcloudClient:
|
||||
assert isinstance(client, SoundcloudClient)
|
||||
return client
|
||||
|
||||
|
||||
PROMPTERS = {
|
||||
"qobuz": QobuzPrompter,
|
||||
"deezer": DeezerPrompter,
|
||||
"tidal": TidalPrompter,
|
||||
"soundcloud": SoundcloudPrompter,
|
||||
}
|
||||
|
||||
|
||||
def get_prompter(client: Client, config: Config) -> CredentialPrompter:
|
||||
"""Return an instance of a prompter."""
|
||||
p = PROMPTERS[client.source]
|
||||
return p(config, client)
|
||||
|
|
@ -0,0 +1,20 @@
|
|||
import os
|
||||
from pathlib import Path
|
||||
|
||||
from appdirs import user_config_dir
|
||||
|
||||
APPNAME = "streamrip"
|
||||
APP_DIR = user_config_dir(APPNAME)
|
||||
HOME = Path.home()
|
||||
|
||||
LOG_DIR = CACHE_DIR = CONFIG_DIR = APP_DIR
|
||||
DEFAULT_CONFIG_PATH = os.path.join(CONFIG_DIR, "config.toml")
|
||||
|
||||
DOWNLOADS_DIR = os.path.join(HOME, "StreamripDownloads")
|
||||
# file shipped with script
|
||||
BLANK_CONFIG_PATH = os.path.join(os.path.dirname(__file__), "config.toml")
|
||||
|
||||
DEFAULT_DOWNLOADS_FOLDER = os.path.join(HOME, "StreamripDownloads")
|
||||
DEFAULT_DOWNLOADS_DB_PATH = os.path.join(LOG_DIR, "downloads.db")
|
||||
DEFAULT_FAILED_DOWNLOADS_DB_PATH = os.path.join(LOG_DIR, "failed_downloads.db")
|
||||
DEFAULT_YOUTUBE_VIDEO_DOWNLOADS_FOLDER = os.path.join(DOWNLOADS_DIR, "YouTubeVideos")
|
||||
|
|
@ -1,88 +0,0 @@
|
|||
"""Get app id and secrets for Qobuz.
|
||||
|
||||
Credits to Dash for this tool.
|
||||
"""
|
||||
|
||||
import base64
|
||||
import re
|
||||
from collections import OrderedDict
|
||||
from typing import List
|
||||
|
||||
import requests
|
||||
|
||||
|
||||
class Spoofer:
|
||||
"""Spoofs the information required to stream tracks from Qobuz."""
|
||||
|
||||
def __init__(self):
|
||||
"""Create a Spoofer."""
|
||||
self.seed_timezone_regex = (
|
||||
r'[a-z]\.initialSeed\("(?P<seed>[\w=]+)",window\.ut'
|
||||
r"imezone\.(?P<timezone>[a-z]+)\)"
|
||||
)
|
||||
# note: {timezones} should be replaced with every capitalized timezone joined by a |
|
||||
self.info_extras_regex = (
|
||||
r'name:"\w+/(?P<timezone>{timezones})",info:"'
|
||||
r'(?P<info>[\w=]+)",extras:"(?P<extras>[\w=]+)"'
|
||||
)
|
||||
self.app_id_regex = (
|
||||
r'{app_id:"(?P<app_id>\d{9})",app_secret:"\w{32}",base_port:"80"'
|
||||
r',base_url:"https://www\.qobuz\.com",base_method:"/api\.js'
|
||||
r'on/0\.2/"},n\.base_url="https://nightly-play\.qobuz\.com"'
|
||||
)
|
||||
login_page_request = requests.get("https://play.qobuz.com/login")
|
||||
login_page = login_page_request.text
|
||||
bundle_url_match = re.search(
|
||||
r'<script src="(/resources/\d+\.\d+\.\d+-[a-z]\d{3}/bundle\.js)"></script>',
|
||||
login_page,
|
||||
)
|
||||
assert bundle_url_match is not None
|
||||
bundle_url = bundle_url_match.group(1)
|
||||
bundle_req = requests.get("https://play.qobuz.com" + bundle_url)
|
||||
self.bundle = bundle_req.text
|
||||
|
||||
def get_app_id(self) -> str:
|
||||
"""Get the app id.
|
||||
|
||||
:rtype: str
|
||||
"""
|
||||
match = re.search(self.app_id_regex, self.bundle)
|
||||
if match is not None:
|
||||
return str(match.group("app_id"))
|
||||
|
||||
raise Exception("Could not find app id.")
|
||||
|
||||
def get_secrets(self) -> List[str]:
|
||||
"""Get secrets."""
|
||||
seed_matches = re.finditer(self.seed_timezone_regex, self.bundle)
|
||||
secrets = OrderedDict()
|
||||
for match in seed_matches:
|
||||
seed, timezone = match.group("seed", "timezone")
|
||||
secrets[timezone] = [seed]
|
||||
"""
|
||||
The code that follows switches around the first and second timezone.
|
||||
Qobuz uses two ternary (a shortened if statement) conditions that
|
||||
should always return false. The way Javascript's ternary syntax
|
||||
works, the second option listed is what runs if the condition returns
|
||||
false. Because of this, we must prioritize the *second* seed/timezone
|
||||
pair captured, not the first.
|
||||
"""
|
||||
keypairs = list(secrets.items())
|
||||
secrets.move_to_end(keypairs[1][0], last=False)
|
||||
|
||||
info_extras_regex = self.info_extras_regex.format(
|
||||
timezones="|".join(timezone.capitalize() for timezone in secrets)
|
||||
)
|
||||
info_extras_matches = re.finditer(info_extras_regex, self.bundle)
|
||||
for match in info_extras_matches:
|
||||
timezone, info, extras = match.group("timezone", "info", "extras")
|
||||
secrets[timezone.lower()] += [info, extras]
|
||||
|
||||
for secret_pair in secrets:
|
||||
secrets[secret_pair] = base64.standard_b64decode(
|
||||
"".join(secrets[secret_pair])[:-44]
|
||||
).decode("utf-8")
|
||||
|
||||
vals: List[str] = list(secrets.values())
|
||||
vals.remove("")
|
||||
return vals
|
||||
|
|
@ -1,448 +0,0 @@
|
|||
"""Miscellaneous utility functions."""
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import base64
|
||||
import logging
|
||||
from string import Formatter
|
||||
from typing import Dict, Hashable, Iterator, Optional, Tuple, Union
|
||||
|
||||
import requests
|
||||
from click import secho, style
|
||||
from pathvalidate import sanitize_filename
|
||||
from requests.packages import urllib3
|
||||
from tqdm import tqdm
|
||||
|
||||
from .constants import COVER_SIZES, TIDAL_COVER_URL
|
||||
from .exceptions import InvalidQuality, InvalidSourceError
|
||||
|
||||
urllib3.disable_warnings()
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
|
||||
def safe_get(d: dict, *keys: Hashable, default=None):
|
||||
"""Traverse dict layers safely.
|
||||
|
||||
Usage:
|
||||
>>> d = {'foo': {'bar': 'baz'}}
|
||||
>>> safe_get(d, 'baz')
|
||||
None
|
||||
>>> safe_get(d, 'foo', 'bar')
|
||||
'baz'
|
||||
|
||||
:param d:
|
||||
:type d: dict
|
||||
:param keys:
|
||||
:type keys: Hashable
|
||||
:param default: the default value to use if a key isn't found
|
||||
"""
|
||||
curr = d
|
||||
res = default
|
||||
for key in keys:
|
||||
res = curr.get(key, default)
|
||||
if res == default or not hasattr(res, "__getitem__"):
|
||||
return res
|
||||
else:
|
||||
curr = res
|
||||
return res
|
||||
|
||||
|
||||
def clean_filename(fn: str, restrict=False) -> str:
|
||||
path = sanitize_filename(fn)
|
||||
if restrict:
|
||||
from string import printable
|
||||
|
||||
allowed_chars = set(printable)
|
||||
path = "".join(c for c in path if c in allowed_chars)
|
||||
|
||||
return path
|
||||
|
||||
|
||||
__QUALITY_MAP: Dict[str, Dict[int, Union[int, str, Tuple[int, str]]]] = {
|
||||
"qobuz": {
|
||||
1: 5,
|
||||
2: 6,
|
||||
3: 7,
|
||||
4: 27,
|
||||
},
|
||||
"deezer": {
|
||||
0: (9, "MP3_128"),
|
||||
1: (3, "MP3_320"),
|
||||
2: (1, "FLAC"),
|
||||
},
|
||||
"tidal": {
|
||||
0: "LOW", # AAC
|
||||
1: "HIGH", # AAC
|
||||
2: "LOSSLESS", # CD Quality
|
||||
3: "HI_RES", # MQA
|
||||
},
|
||||
"deezloader": {
|
||||
0: 128,
|
||||
1: 320,
|
||||
2: 1411,
|
||||
},
|
||||
}
|
||||
|
||||
|
||||
def get_quality(quality_id: int, source: str) -> Union[str, int, Tuple[int, str]]:
|
||||
"""Get the source-specific quality id.
|
||||
|
||||
:param quality_id: the universal quality id (0, 1, 2, 4)
|
||||
:type quality_id: int
|
||||
:param source: qobuz, tidal, or deezer
|
||||
:type source: str
|
||||
:rtype: Union[str, int]
|
||||
"""
|
||||
return __QUALITY_MAP[source][quality_id]
|
||||
|
||||
|
||||
def get_quality_id(bit_depth: Optional[int], sampling_rate: Optional[int]):
|
||||
"""Get the universal quality id from bit depth and sampling rate.
|
||||
|
||||
:param bit_depth:
|
||||
:type bit_depth: Optional[int]
|
||||
:param sampling_rate:
|
||||
:type sampling_rate: Optional[int]
|
||||
"""
|
||||
# XXX: Should `0` quality be supported?
|
||||
if bit_depth is None or sampling_rate is None: # is lossy
|
||||
return 1
|
||||
|
||||
if bit_depth == 16:
|
||||
return 2
|
||||
|
||||
if bit_depth == 24:
|
||||
if sampling_rate <= 96:
|
||||
return 3
|
||||
|
||||
return 4
|
||||
|
||||
|
||||
def get_stats_from_quality(
|
||||
quality_id: int,
|
||||
) -> Tuple[Optional[int], Optional[int]]:
|
||||
"""Get bit depth and sampling rate based on the quality id.
|
||||
|
||||
:param quality_id:
|
||||
:type quality_id: int
|
||||
:rtype: Tuple[Optional[int], Optional[int]]
|
||||
"""
|
||||
if quality_id <= 1:
|
||||
return (None, None)
|
||||
elif quality_id == 2:
|
||||
return (16, 44100)
|
||||
elif quality_id == 3:
|
||||
return (24, 96000)
|
||||
elif quality_id == 4:
|
||||
return (24, 192000)
|
||||
else:
|
||||
raise InvalidQuality(quality_id)
|
||||
|
||||
|
||||
def clean_format(formatter: str, format_info, restrict: bool = False):
|
||||
"""Format track or folder names sanitizing every formatter key.
|
||||
|
||||
:param formatter:
|
||||
:type formatter: str
|
||||
:param kwargs:
|
||||
"""
|
||||
fmt_keys = filter(None, (i[1] for i in Formatter().parse(formatter)))
|
||||
# fmt_keys = (i[1] for i in Formatter().parse(formatter) if i[1] is not None)
|
||||
|
||||
logger.debug("Formatter keys: %s", formatter)
|
||||
|
||||
clean_dict = {}
|
||||
for key in fmt_keys:
|
||||
logger.debug(repr(key))
|
||||
logger.debug(format_info.get(key))
|
||||
if isinstance(format_info.get(key), (str, float)):
|
||||
logger.debug("1")
|
||||
clean_dict[key] = clean_filename(str(format_info[key]), restrict=restrict)
|
||||
elif key == "explicit":
|
||||
logger.debug("3")
|
||||
clean_dict[key] = " (Explicit) " if format_info.get(key, False) else ""
|
||||
elif isinstance(format_info.get(key), int): # track/discnumber
|
||||
logger.debug("2")
|
||||
clean_dict[key] = f"{format_info[key]:02}"
|
||||
else:
|
||||
clean_dict[key] = "Unknown"
|
||||
|
||||
return formatter.format(**clean_dict)
|
||||
|
||||
|
||||
def tidal_cover_url(uuid, size):
|
||||
"""Generate a tidal cover url.
|
||||
|
||||
:param uuid:
|
||||
:param size:
|
||||
"""
|
||||
possibles = (80, 160, 320, 640, 1280)
|
||||
assert size in possibles, f"size must be in {possibles}"
|
||||
|
||||
# A common occurance is a valid size but no uuid
|
||||
if not uuid:
|
||||
return None
|
||||
return TIDAL_COVER_URL.format(uuid=uuid.replace("-", "/"), height=size, width=size)
|
||||
|
||||
|
||||
def decrypt_mqa_file(in_path, out_path, encryption_key):
|
||||
"""Decrypt an MQA file.
|
||||
|
||||
:param in_path:
|
||||
:param out_path:
|
||||
:param encryption_key:
|
||||
"""
|
||||
try:
|
||||
from Crypto.Cipher import AES
|
||||
from Crypto.Util import Counter
|
||||
except (ImportError, ModuleNotFoundError):
|
||||
secho(
|
||||
"To download this item in MQA, you need to run ",
|
||||
fg="yellow",
|
||||
nl=False,
|
||||
)
|
||||
secho("pip3 install pycryptodome --upgrade", fg="blue", nl=False)
|
||||
secho(".")
|
||||
exit()
|
||||
|
||||
# Do not change this
|
||||
master_key = "UIlTTEMmmLfGowo/UC60x2H45W6MdGgTRfo/umg4754="
|
||||
|
||||
# Decode the base64 strings to ascii strings
|
||||
master_key = base64.b64decode(master_key)
|
||||
security_token = base64.b64decode(encryption_key)
|
||||
|
||||
# Get the IV from the first 16 bytes of the securityToken
|
||||
iv = security_token[:16]
|
||||
encrypted_st = security_token[16:]
|
||||
|
||||
# Initialize decryptor
|
||||
decryptor = AES.new(master_key, AES.MODE_CBC, iv)
|
||||
|
||||
# Decrypt the security token
|
||||
decrypted_st = decryptor.decrypt(encrypted_st)
|
||||
|
||||
# Get the audio stream decryption key and nonce from the decrypted security token
|
||||
key = decrypted_st[:16]
|
||||
nonce = decrypted_st[16:24]
|
||||
|
||||
counter = Counter.new(64, prefix=nonce, initial_value=0)
|
||||
decryptor = AES.new(key, AES.MODE_CTR, counter=counter)
|
||||
|
||||
with open(in_path, "rb") as enc_file:
|
||||
dec_bytes = decryptor.decrypt(enc_file.read())
|
||||
with open(out_path, "wb") as dec_file:
|
||||
dec_file.write(dec_bytes)
|
||||
|
||||
|
||||
def ext(quality: int, source: str):
|
||||
"""Get the extension of an audio file.
|
||||
|
||||
:param quality:
|
||||
:type quality: int
|
||||
:param source:
|
||||
:type source: str
|
||||
"""
|
||||
if quality <= 1:
|
||||
if source == "tidal":
|
||||
return ".m4a"
|
||||
else:
|
||||
return ".mp3"
|
||||
else:
|
||||
return ".flac"
|
||||
|
||||
|
||||
def gen_threadsafe_session(
|
||||
headers: dict = None, pool_connections: int = 100, pool_maxsize: int = 100
|
||||
) -> requests.Session:
|
||||
"""Create a new Requests session with a large poolsize.
|
||||
|
||||
:param headers:
|
||||
:type headers: dict
|
||||
:param pool_connections:
|
||||
:type pool_connections: int
|
||||
:param pool_maxsize:
|
||||
:type pool_maxsize: int
|
||||
:rtype: requests.Session
|
||||
"""
|
||||
if headers is None:
|
||||
headers = {}
|
||||
|
||||
session = requests.Session()
|
||||
adapter = requests.adapters.HTTPAdapter(pool_connections=100, pool_maxsize=100)
|
||||
session.mount("https://", adapter)
|
||||
session.headers.update(headers)
|
||||
return session
|
||||
|
||||
|
||||
def decho(message, fg=None):
|
||||
"""Debug echo the message.
|
||||
|
||||
:param message:
|
||||
:param fg: ANSI color with which to display the message on the
|
||||
screen
|
||||
"""
|
||||
secho(message, fg=fg)
|
||||
logger.debug(message)
|
||||
|
||||
|
||||
def get_container(quality: int, source: str) -> str:
|
||||
"""Get the file container given the quality.
|
||||
|
||||
`container` can also be the the codec; both work.
|
||||
|
||||
:param quality: quality id
|
||||
:type quality: int
|
||||
:param source:
|
||||
:type source: str
|
||||
:rtype: str
|
||||
"""
|
||||
if quality >= 2:
|
||||
return "FLAC"
|
||||
|
||||
if source == "tidal":
|
||||
return "AAC"
|
||||
|
||||
return "MP3"
|
||||
|
||||
|
||||
def get_cover_urls(resp: dict, source: str) -> dict:
|
||||
"""Parse a response dict containing cover info according to the source.
|
||||
|
||||
:param resp:
|
||||
:type resp: dict
|
||||
:param source:
|
||||
:type source: str
|
||||
:rtype: dict
|
||||
"""
|
||||
|
||||
if source == "qobuz":
|
||||
cover_urls = resp["image"]
|
||||
cover_urls["original"] = cover_urls["large"].replace("600", "org")
|
||||
return cover_urls
|
||||
|
||||
if source == "tidal":
|
||||
uuid = resp["cover"]
|
||||
if not uuid:
|
||||
return None
|
||||
return {
|
||||
sk: tidal_cover_url(uuid, size)
|
||||
for sk, size in zip(COVER_SIZES, (160, 320, 640, 1280))
|
||||
}
|
||||
|
||||
if source == "deezer":
|
||||
resp_keys = ("cover", "cover_medium", "cover_large", "cover_xl")
|
||||
resp_keys_fallback = (
|
||||
"picture",
|
||||
"picture_medium",
|
||||
"picture_large",
|
||||
"picture_xl",
|
||||
)
|
||||
cover_urls = {
|
||||
sk: resp.get(rk, resp.get(rkf)) # size key, resp key, resp key fallback
|
||||
for sk, rk, rkf in zip(
|
||||
COVER_SIZES,
|
||||
resp_keys,
|
||||
resp_keys_fallback,
|
||||
)
|
||||
}
|
||||
|
||||
if cover_urls["large"] is None and resp.get("cover_big") is not None:
|
||||
cover_urls["large"] = resp["cover_big"]
|
||||
|
||||
return cover_urls
|
||||
|
||||
if source == "soundcloud":
|
||||
cover_url = (resp["artwork_url"] or resp["user"].get("avatar_url")).replace(
|
||||
"large", "t500x500"
|
||||
)
|
||||
|
||||
cover_urls = {"large": cover_url}
|
||||
|
||||
return cover_urls
|
||||
|
||||
raise InvalidSourceError(source)
|
||||
|
||||
|
||||
def downsize_image(filepath: str, width: int, height: int):
|
||||
"""Downsize an image.
|
||||
|
||||
If either the width or the height is greater than the image's width or
|
||||
height, that dimension will not be changed.
|
||||
|
||||
:param filepath:
|
||||
:type filepath: str
|
||||
:param width:
|
||||
:type width: int
|
||||
:param height:
|
||||
:type height: int
|
||||
:raises: ValueError
|
||||
"""
|
||||
if width == -1 or height == -1:
|
||||
return
|
||||
|
||||
from PIL import Image, UnidentifiedImageError
|
||||
|
||||
try:
|
||||
image = Image.open(filepath)
|
||||
except UnidentifiedImageError:
|
||||
secho("Cover art not found, skipping downsize.", fg="red")
|
||||
return
|
||||
|
||||
width = min(width, image.width)
|
||||
height = min(height, image.height)
|
||||
|
||||
resized_image = image.resize((width, height))
|
||||
resized_image.save(filepath)
|
||||
|
||||
|
||||
TQDM_THEMES = {
|
||||
"plain": None,
|
||||
"dainty": (
|
||||
"{desc} |{bar}| "
|
||||
+ style("{remaining}", fg="magenta")
|
||||
+ " left at "
|
||||
+ style("{rate_fmt}{postfix} ", fg="cyan", bold=True)
|
||||
),
|
||||
}
|
||||
|
||||
TQDM_DEFAULT_THEME = "dainty"
|
||||
|
||||
TQDM_BAR_FORMAT = TQDM_THEMES["dainty"]
|
||||
|
||||
|
||||
def set_progress_bar_theme(theme: str):
|
||||
"""Set the theme of the tqdm progress bar.
|
||||
|
||||
:param theme:
|
||||
:type theme: str
|
||||
"""
|
||||
global TQDM_BAR_FORMAT
|
||||
TQDM_BAR_FORMAT = TQDM_THEMES[theme]
|
||||
|
||||
|
||||
def tqdm_stream(iterator, desc: Optional[str] = None) -> Iterator[bytes]:
|
||||
"""Return a tqdm bar with presets appropriate for downloading large files.
|
||||
|
||||
:param iterator:
|
||||
:type iterator: DownloadStream
|
||||
:param desc: Description to add for the progress bar
|
||||
:type desc: Optional[str]
|
||||
:rtype: Iterator
|
||||
"""
|
||||
with get_tqdm_bar(len(iterator), desc=desc) as bar:
|
||||
for chunk in iterator:
|
||||
bar.update(len(chunk))
|
||||
yield chunk
|
||||
|
||||
|
||||
def get_tqdm_bar(total, desc: Optional[str] = None, unit="B"):
|
||||
return tqdm(
|
||||
total=total,
|
||||
unit=unit,
|
||||
unit_scale=True,
|
||||
unit_divisor=1024,
|
||||
desc=desc,
|
||||
dynamic_ncols=True,
|
||||
bar_format=TQDM_BAR_FORMAT,
|
||||
)
|
||||
{kind=link}
|
After Width: | Height: | Size: 631 B |
|
|
@ -0,0 +1,26 @@
|
|||
import hashlib
|
||||
import os
|
||||
|
||||
import pytest
|
||||
from util import arun
|
||||
|
||||
from streamrip.client.qobuz import QobuzClient
|
||||
from streamrip.config import Config
|
||||
|
||||
|
||||
@pytest.fixture(scope="session")
|
||||
def qobuz_client():
|
||||
config = Config.defaults()
|
||||
config.session.qobuz.email_or_userid = os.environ["QOBUZ_EMAIL"]
|
||||
config.session.qobuz.password_or_token = hashlib.md5(
|
||||
os.environ["QOBUZ_PASSWORD"].encode("utf-8"),
|
||||
).hexdigest()
|
||||
if "QOBUZ_APP_ID" in os.environ and "QOBUZ_SECRETS" in os.environ:
|
||||
config.session.qobuz.app_id = os.environ["QOBUZ_APP_ID"]
|
||||
config.session.qobuz.secrets = os.environ["QOBUZ_SECRETS"].split(",")
|
||||
client = QobuzClient(config)
|
||||
arun(client.login())
|
||||
|
||||
yield client
|
||||
|
||||
arun(client.session.close())
|
||||
|
|
@ -0,0 +1,16 @@
|
|||
import hashlib
|
||||
import os
|
||||
|
||||
import pytest
|
||||
|
||||
from streamrip.config import Config
|
||||
|
||||
|
||||
@pytest.fixture()
|
||||
def config():
|
||||
c = Config.defaults()
|
||||
c.session.qobuz.email_or_userid = os.environ["QOBUZ_EMAIL"]
|
||||
c.session.qobuz.password_or_token = hashlib.md5(
|
||||
os.environ["QOBUZ_PASSWORD"].encode("utf-8"),
|
||||
).hexdigest()
|
||||
return c
|
||||
|
|
@ -0,0 +1,17 @@
|
|||
import asyncio
|
||||
|
||||
loop = asyncio.new_event_loop()
|
||||
|
||||
|
||||
def arun(coro):
|
||||
return loop.run_until_complete(coro)
|
||||
|
||||
|
||||
def afor(async_gen):
|
||||
async def _afor(async_gen):
|
||||
item = []
|
||||
async for item in async_gen:
|
||||
item.append(item)
|
||||
return item
|
||||
|
||||
return arun(_afor(async_gen))
|
||||
|
|
@ -0,0 +1,103 @@
|
|||
{
|
||||
"maximum_bit_depth": 24,
|
||||
"image": {
|
||||
"small": "https://static.qobuz.com/images/covers/32/10/0603497941032_230.jpg",
|
||||
"thumbnail": "https://static.qobuz.com/images/covers/32/10/0603497941032_50.jpg",
|
||||
"large": "https://static.qobuz.com/images/covers/32/10/0603497941032_600.jpg",
|
||||
"back": null
|
||||
},
|
||||
"media_count": 1,
|
||||
"artist": {
|
||||
"image": null,
|
||||
"name": "Fleetwood Mac",
|
||||
"id": 132127,
|
||||
"albums_count": 424,
|
||||
"slug": "fleetwood-mac",
|
||||
"picture": null
|
||||
},
|
||||
"artists": [
|
||||
{ "id": 132127, "name": "Fleetwood Mac", "roles": ["main-artist"] }
|
||||
],
|
||||
"upc": "0603497941032",
|
||||
"released_at": 223858800,
|
||||
"label": {
|
||||
"name": "Rhino - Warner Records",
|
||||
"id": 323970,
|
||||
"albums_count": 3002,
|
||||
"supplier_id": 5,
|
||||
"slug": "rhino-warner-records"
|
||||
},
|
||||
"title": "Rumours",
|
||||
"qobuz_id": 19512572,
|
||||
"version": "2001 Remaster",
|
||||
"url": "https://www.qobuz.com/fr-fr/album/rumours-fleetwood-mac/0603497941032",
|
||||
"duration": 2387,
|
||||
"parental_warning": false,
|
||||
"popularity": 0,
|
||||
"tracks_count": 11,
|
||||
"genre": {
|
||||
"path": [112, 119],
|
||||
"color": "#5eabc1",
|
||||
"name": "Rock",
|
||||
"id": 119,
|
||||
"slug": "rock"
|
||||
},
|
||||
"maximum_channel_count": 2,
|
||||
"id": "0603497941032",
|
||||
"maximum_sampling_rate": 96,
|
||||
"articles": [],
|
||||
"release_date_original": "1977-02-04",
|
||||
"release_date_download": "1977-02-04",
|
||||
"release_date_stream": "1977-02-04",
|
||||
"purchasable": true,
|
||||
"streamable": true,
|
||||
"previewable": true,
|
||||
"sampleable": true,
|
||||
"downloadable": true,
|
||||
"displayable": true,
|
||||
"purchasable_at": 1693551600,
|
||||
"streamable_at": 1690354800,
|
||||
"hires": true,
|
||||
"hires_streamable": true,
|
||||
"awards": [
|
||||
{
|
||||
"name": "The Qobuz Ideal Discography",
|
||||
"slug": "qobuz",
|
||||
"award_slug": "discotheque_ideale",
|
||||
"awarded_at": 1420066800,
|
||||
"award_id": "70",
|
||||
"publication_id": "2",
|
||||
"publication_name": "Qobuz",
|
||||
"publication_slug": "qobuz"
|
||||
}
|
||||
],
|
||||
"goodies": [],
|
||||
"area": null,
|
||||
"catchline": "",
|
||||
"composer": {
|
||||
"id": 573076,
|
||||
"name": "Various Composers",
|
||||
"slug": "various-composers",
|
||||
"albums_count": 583621,
|
||||
"picture": null,
|
||||
"image": null
|
||||
},
|
||||
"created_at": 0,
|
||||
"genres_list": ["Pop/Rock", "Pop/Rock\u2192Rock"],
|
||||
"period": null,
|
||||
"copyright": "\u00a9 1977 Warner Records Inc. \u2117 1977 Warner Records Inc. Marketed by Rhino Entertainment Company, A Warner Music Group Company.",
|
||||
"is_official": true,
|
||||
"maximum_technical_specifications": "24 bits / 96.0 kHz - Stereo",
|
||||
"product_sales_factors_monthly": 0,
|
||||
"product_sales_factors_weekly": 0,
|
||||
"product_sales_factors_yearly": 0,
|
||||
"product_type": "album",
|
||||
"product_url": "/fr-fr/album/rumours-fleetwood-mac/0603497941032",
|
||||
"recording_information": "",
|
||||
"relative_url": "/album/rumours-fleetwood-mac/0603497941032",
|
||||
"release_tags": ["remaster"],
|
||||
"release_type": "album",
|
||||
"slug": "rumours-fleetwood-mac",
|
||||
"subtitle": "Fleetwood Mac",
|
||||
"description": ""
|
||||
}
|
||||
|
|
@ -0,0 +1,293 @@
|
|||
import os
|
||||
import shutil
|
||||
|
||||
import pytest
|
||||
import tomlkit
|
||||
|
||||
from streamrip.config import (
|
||||
ArtworkConfig,
|
||||
CliConfig,
|
||||
Config,
|
||||
ConfigData,
|
||||
ConversionConfig,
|
||||
DatabaseConfig,
|
||||
DeezerConfig,
|
||||
DownloadsConfig,
|
||||
FilepathsConfig,
|
||||
LastFmConfig,
|
||||
MetadataConfig,
|
||||
MiscConfig,
|
||||
QobuzConfig,
|
||||
QobuzDiscographyFilterConfig,
|
||||
SoundcloudConfig,
|
||||
TidalConfig,
|
||||
YoutubeConfig,
|
||||
_get_dict_keys_r,
|
||||
_nested_set,
|
||||
update_config,
|
||||
)
|
||||
|
||||
SAMPLE_CONFIG = "tests/test_config.toml"
|
||||
OLD_CONFIG = "tests/test_config_old.toml"
|
||||
|
||||
|
||||
# Define a fixture to create a sample ConfigData instance for testing
|
||||
@pytest.fixture()
|
||||
def sample_config_data() -> ConfigData:
|
||||
# Create a sample ConfigData instance here
|
||||
# You can customize this to your specific needs for testing
|
||||
with open(SAMPLE_CONFIG) as f:
|
||||
config_data = ConfigData.from_toml(f.read())
|
||||
return config_data
|
||||
|
||||
|
||||
# Define a fixture to create a sample Config instance for testing
|
||||
@pytest.fixture()
|
||||
def sample_config() -> Config:
|
||||
# Create a sample Config instance here
|
||||
# You can customize this to your specific needs for testing
|
||||
config = Config(SAMPLE_CONFIG)
|
||||
return config
|
||||
|
||||
|
||||
def test_get_keys_r():
|
||||
d = {
|
||||
"key1": {
|
||||
"key2": {
|
||||
"key3": 1,
|
||||
"key4": 1,
|
||||
},
|
||||
"key6": [1, 2],
|
||||
5: 1,
|
||||
}
|
||||
}
|
||||
res = _get_dict_keys_r(d)
|
||||
print(res)
|
||||
assert res == {
|
||||
("key1", "key2", "key3"),
|
||||
("key1", "key2", "key4"),
|
||||
("key1", "key6"),
|
||||
("key1", 5),
|
||||
}
|
||||
|
||||
|
||||
def test_safe_set():
|
||||
d = {
|
||||
"key1": {
|
||||
"key2": {
|
||||
"key3": 1,
|
||||
"key4": 1,
|
||||
},
|
||||
"key6": [1, 2],
|
||||
5: 1,
|
||||
}
|
||||
}
|
||||
_nested_set(d, "key1", "key2", "key3", val=5)
|
||||
assert d == {
|
||||
"key1": {
|
||||
"key2": {
|
||||
"key3": 5,
|
||||
"key4": 1,
|
||||
},
|
||||
"key6": [1, 2],
|
||||
5: 1,
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
def test_config_update():
|
||||
old = {
|
||||
"downloads": {"folder": "some_path", "use_service": True},
|
||||
"qobuz": {"email": "asdf@gmail.com", "password": "test"},
|
||||
"legacy_conf": {"something": 1, "other": 2},
|
||||
}
|
||||
new = {
|
||||
"downloads": {"folder": "", "use_service": False, "keep_artwork": True},
|
||||
"qobuz": {"email": "", "password": ""},
|
||||
"tidal": {"email": "", "password": ""},
|
||||
}
|
||||
update_config(old, new)
|
||||
assert new == {
|
||||
"downloads": {"folder": "some_path", "use_service": True, "keep_artwork": True},
|
||||
"qobuz": {"email": "asdf@gmail.com", "password": "test"},
|
||||
"tidal": {"email": "", "password": ""},
|
||||
}
|
||||
|
||||
|
||||
def test_config_throws_outdated():
|
||||
with pytest.raises(Exception, match="update"):
|
||||
_ = Config(OLD_CONFIG)
|
||||
|
||||
|
||||
def test_config_file_update():
|
||||
tmp_conf = "tests/test_config_old2.toml"
|
||||
shutil.copy("tests/test_config_old.toml", tmp_conf)
|
||||
Config._update_file(tmp_conf, SAMPLE_CONFIG)
|
||||
|
||||
with open(tmp_conf) as f:
|
||||
s = f.read()
|
||||
toml = tomlkit.parse(s) # type: ignore
|
||||
|
||||
assert toml["downloads"]["folder"] == "old_value" # type: ignore
|
||||
assert toml["downloads"]["source_subdirectories"] is True # type: ignore
|
||||
assert toml["downloads"]["concurrency"] is True # type: ignore
|
||||
assert toml["downloads"]["max_connections"] == 6 # type: ignore
|
||||
assert toml["downloads"]["requests_per_minute"] == 60 # type: ignore
|
||||
assert toml["cli"]["text_output"] is True # type: ignore
|
||||
assert toml["cli"]["progress_bars"] is True # type: ignore
|
||||
assert toml["cli"]["max_search_results"] == 100 # type: ignore
|
||||
assert toml["misc"]["version"] == "2.0.6" # type: ignore
|
||||
assert "YouTubeVideos" in str(toml["youtube"]["video_downloads_folder"])
|
||||
# type: ignore
|
||||
os.remove("tests/test_config_old2.toml")
|
||||
|
||||
|
||||
def test_sample_config_data_properties(sample_config_data):
|
||||
# Test the properties of ConfigData
|
||||
assert sample_config_data.modified is False # Ensure initial state is not modified
|
||||
|
||||
|
||||
def test_sample_config_data_modification(sample_config_data):
|
||||
# Test modifying ConfigData and checking modified property
|
||||
sample_config_data.set_modified()
|
||||
assert sample_config_data._modified is True
|
||||
|
||||
|
||||
def test_sample_config_data_fields(sample_config_data):
|
||||
test_config = ConfigData(
|
||||
toml=None, # type: ignore
|
||||
downloads=DownloadsConfig(
|
||||
folder="test_folder",
|
||||
source_subdirectories=False,
|
||||
disc_subdirectories=True,
|
||||
concurrency=True,
|
||||
max_connections=6,
|
||||
requests_per_minute=60,
|
||||
),
|
||||
qobuz=QobuzConfig(
|
||||
use_auth_token=False,
|
||||
email_or_userid="test@gmail.com",
|
||||
password_or_token="test_pwd",
|
||||
app_id="12345",
|
||||
quality=3,
|
||||
download_booklets=True,
|
||||
secrets=["secret1", "secret2"],
|
||||
),
|
||||
tidal=TidalConfig(
|
||||
user_id="userid",
|
||||
country_code="countrycode",
|
||||
access_token="accesstoken",
|
||||
refresh_token="refreshtoken",
|
||||
token_expiry="tokenexpiry",
|
||||
quality=3,
|
||||
download_videos=True,
|
||||
),
|
||||
deezer=DeezerConfig(
|
||||
arl="testarl",
|
||||
quality=2,
|
||||
use_deezloader=True,
|
||||
deezloader_warnings=True,
|
||||
),
|
||||
soundcloud=SoundcloudConfig(
|
||||
client_id="clientid",
|
||||
app_version="appversion",
|
||||
quality=0,
|
||||
),
|
||||
youtube=YoutubeConfig(
|
||||
video_downloads_folder="videodownloadsfolder",
|
||||
quality=0,
|
||||
download_videos=False,
|
||||
),
|
||||
lastfm=LastFmConfig(source="qobuz", fallback_source=""),
|
||||
filepaths=FilepathsConfig(
|
||||
add_singles_to_folder=False,
|
||||
folder_format="{albumartist} - {title} ({year}) [{container}] [{bit_depth}B-{sampling_rate}kHz]",
|
||||
track_format="{tracknumber}. {artist} - {title}{explicit}",
|
||||
restrict_characters=False,
|
||||
truncate_to=120,
|
||||
),
|
||||
artwork=ArtworkConfig(
|
||||
embed=True,
|
||||
embed_size="large",
|
||||
embed_max_width=-1,
|
||||
save_artwork=True,
|
||||
saved_max_width=-1,
|
||||
),
|
||||
metadata=MetadataConfig(
|
||||
set_playlist_to_album=True,
|
||||
renumber_playlist_tracks=True,
|
||||
exclude=[],
|
||||
),
|
||||
qobuz_filters=QobuzDiscographyFilterConfig(
|
||||
extras=False,
|
||||
repeats=False,
|
||||
non_albums=False,
|
||||
features=False,
|
||||
non_studio_albums=False,
|
||||
non_remaster=False,
|
||||
),
|
||||
cli=CliConfig(
|
||||
text_output=False,
|
||||
progress_bars=False,
|
||||
max_search_results=100,
|
||||
),
|
||||
database=DatabaseConfig(
|
||||
downloads_enabled=True,
|
||||
downloads_path="downloadspath",
|
||||
failed_downloads_enabled=True,
|
||||
failed_downloads_path="faileddownloadspath",
|
||||
),
|
||||
conversion=ConversionConfig(
|
||||
enabled=False,
|
||||
codec="ALAC",
|
||||
sampling_rate=48000,
|
||||
bit_depth=24,
|
||||
lossy_bitrate=320,
|
||||
),
|
||||
misc=MiscConfig(version="2.0", check_for_updates=True),
|
||||
_modified=False,
|
||||
)
|
||||
assert sample_config_data.downloads == test_config.downloads
|
||||
assert sample_config_data.qobuz == test_config.qobuz
|
||||
assert sample_config_data.tidal == test_config.tidal
|
||||
assert sample_config_data.deezer == test_config.deezer
|
||||
assert sample_config_data.soundcloud == test_config.soundcloud
|
||||
assert sample_config_data.youtube == test_config.youtube
|
||||
assert sample_config_data.lastfm == test_config.lastfm
|
||||
assert sample_config_data.artwork == test_config.artwork
|
||||
assert sample_config_data.filepaths == test_config.filepaths
|
||||
assert sample_config_data.metadata == test_config.metadata
|
||||
assert sample_config_data.qobuz_filters == test_config.qobuz_filters
|
||||
assert sample_config_data.database == test_config.database
|
||||
assert sample_config_data.conversion == test_config.conversion
|
||||
|
||||
|
||||
def test_config_update_on_save():
|
||||
tmp_config_path = "tests/config2.toml"
|
||||
shutil.copy(SAMPLE_CONFIG, tmp_config_path)
|
||||
conf = Config(tmp_config_path)
|
||||
conf.file.downloads.folder = "new_folder"
|
||||
conf.file.set_modified()
|
||||
conf.save_file()
|
||||
conf2 = Config(tmp_config_path)
|
||||
os.remove(tmp_config_path)
|
||||
|
||||
assert conf2.session.downloads.folder == "new_folder"
|
||||
|
||||
|
||||
def test_config_dont_update_without_set_modified():
|
||||
tmp_config_path = "tests/config2.toml"
|
||||
shutil.copy(SAMPLE_CONFIG, tmp_config_path)
|
||||
conf = Config(tmp_config_path)
|
||||
conf.file.downloads.folder = "new_folder"
|
||||
del conf
|
||||
conf2 = Config(tmp_config_path)
|
||||
os.remove(tmp_config_path)
|
||||
|
||||
assert conf2.session.downloads.folder == "test_folder"
|
||||
|
||||
|
||||
# Other tests for the Config class can be added as needed
|
||||
|
||||
if __name__ == "__main__":
|
||||
pytest.main()
|
||||
|
|
@ -0,0 +1,190 @@
|
|||
[downloads]
|
||||
# Folder where tracks are downloaded to
|
||||
folder = "test_folder"
|
||||
# Put Qobuz albums in a 'Qobuz' folder, Tidal albums in 'Tidal' etc.
|
||||
source_subdirectories = false
|
||||
disc_subdirectories = true
|
||||
|
||||
# Download (and convert) tracks all at once, instead of sequentially.
|
||||
# If you are converting the tracks, or have fast internet, this will
|
||||
# substantially improve processing speed.
|
||||
concurrency = true
|
||||
# The maximum number of tracks to download at once
|
||||
# If you have very fast internet, you will benefit from a higher value,
|
||||
# A value that is too high for your bandwidth may cause slowdowns
|
||||
# Set to -1 for no limit
|
||||
max_connections = 6
|
||||
# Max number of API requests per source to handle per minute
|
||||
# Set to -1 for no limit
|
||||
requests_per_minute = 60
|
||||
|
||||
[qobuz]
|
||||
# 1: 320kbps MP3, 2: 16/44.1, 3: 24/<=96, 4: 24/>=96
|
||||
quality = 3
|
||||
# This will download booklet pdfs that are included with some albums
|
||||
download_booklets = true
|
||||
|
||||
# Authenticate to Qobuz using auth token? Value can be true/false only
|
||||
use_auth_token = false
|
||||
# Enter your userid if the above use_auth_token is set to true, else enter your email
|
||||
email_or_userid = "test@gmail.com"
|
||||
# Enter your auth token if the above use_auth_token is set to true, else enter the md5 hash of your plaintext password
|
||||
password_or_token = "test_pwd"
|
||||
# Do not change
|
||||
app_id = "12345"
|
||||
# Do not change
|
||||
secrets = ['secret1', 'secret2']
|
||||
|
||||
[tidal]
|
||||
# 0: 256kbps AAC, 1: 320kbps AAC, 2: 16/44.1 "HiFi" FLAC, 3: 24/44.1 "MQA" FLAC
|
||||
quality = 3
|
||||
# This will download videos included in Video Albums.
|
||||
download_videos = true
|
||||
|
||||
# Do not change any of the fields below
|
||||
user_id = "userid"
|
||||
country_code = "countrycode"
|
||||
access_token = "accesstoken"
|
||||
refresh_token = "refreshtoken"
|
||||
# Tokens last 1 week after refresh. This is the Unix timestamp of the expiration
|
||||
# time. If you haven't used streamrip in more than a week, you may have to log
|
||||
# in again using `rip config --tidal`
|
||||
token_expiry = "tokenexpiry"
|
||||
|
||||
[deezer]
|
||||
# 0, 1, or 2
|
||||
# This only applies to paid Deezer subscriptions. Those using deezloader
|
||||
# are automatically limited to quality = 1
|
||||
quality = 2
|
||||
# An authentication cookie that allows streamrip to use your Deezer account
|
||||
# See https://github.com/nathom/streamrip/wiki/Finding-Your-Deezer-ARL-Cookie
|
||||
# for instructions on how to find this
|
||||
arl = "testarl"
|
||||
# This allows for free 320kbps MP3 downloads from Deezer
|
||||
# If an arl is provided, deezloader is never used
|
||||
use_deezloader = true
|
||||
# This warns you when the paid deezer account is not logged in and rip falls
|
||||
# back to deezloader, which is unreliable
|
||||
deezloader_warnings = true
|
||||
|
||||
[soundcloud]
|
||||
# Only 0 is available for now
|
||||
quality = 0
|
||||
# This changes periodically, so it needs to be updated
|
||||
client_id = "clientid"
|
||||
app_version = "appversion"
|
||||
|
||||
[youtube]
|
||||
# Only 0 is available for now
|
||||
quality = 0
|
||||
# Download the video along with the audio
|
||||
download_videos = false
|
||||
# The path to download the videos to
|
||||
video_downloads_folder = "videodownloadsfolder"
|
||||
|
||||
[database]
|
||||
# Create a database that contains all the track IDs downloaded so far
|
||||
# Any time a track logged in the database is requested, it is skipped
|
||||
# This can be disabled temporarily with the --no-db flag
|
||||
downloads_enabled = true
|
||||
# Path to the downloads database
|
||||
downloads_path = "downloadspath"
|
||||
# If a download fails, the item ID is stored here. Then, `rip repair` can be
|
||||
# called to retry the downloads
|
||||
failed_downloads_enabled = true
|
||||
failed_downloads_path = "faileddownloadspath"
|
||||
|
||||
# Convert tracks to a codec after downloading them.
|
||||
[conversion]
|
||||
enabled = false
|
||||
# FLAC, ALAC, OPUS, MP3, VORBIS, or AAC
|
||||
codec = "ALAC"
|
||||
# In Hz. Tracks are downsampled if their sampling rate is greater than this.
|
||||
# Value of 48000 is recommended to maximize quality and minimize space
|
||||
sampling_rate = 48000
|
||||
# Only 16 and 24 are available. It is only applied when the bit depth is higher
|
||||
# than this value.
|
||||
bit_depth = 24
|
||||
# Only applicable for lossy codecs
|
||||
lossy_bitrate = 320
|
||||
|
||||
# Filter a Qobuz artist's discography. Set to 'true' to turn on a filter.
|
||||
[qobuz_filters]
|
||||
# Remove Collectors Editions, live recordings, etc.
|
||||
extras = false
|
||||
# Picks the highest quality out of albums with identical titles.
|
||||
repeats = false
|
||||
# Remove EPs and Singles
|
||||
non_albums = false
|
||||
# Remove albums whose artist is not the one requested
|
||||
features = false
|
||||
# Skip non studio albums
|
||||
non_studio_albums = false
|
||||
# Only download remastered albums
|
||||
non_remaster = false
|
||||
|
||||
[artwork]
|
||||
# Write the image to the audio file
|
||||
embed = true
|
||||
# The size of the artwork to embed. Options: thumbnail, small, large, original.
|
||||
# "original" images can be up to 30MB, and may fail embedding.
|
||||
# Using "large" is recommended.
|
||||
embed_size = "large"
|
||||
# If this is set to a value > 0, max(width, height) of the embedded art will be set to this value in pixels
|
||||
# Proportions of the image will remain the same
|
||||
embed_max_width = -1
|
||||
# Save the cover image at the highest quality as a seperate jpg file
|
||||
save_artwork = true
|
||||
# If this is set to a value > 0, max(width, height) of the saved art will be set to this value in pixels
|
||||
# Proportions of the image will remain the same
|
||||
saved_max_width = -1
|
||||
|
||||
|
||||
[metadata]
|
||||
# Sets the value of the 'ALBUM' field in the metadata to the playlist's name.
|
||||
# This is useful if your music library software organizes tracks based on album name.
|
||||
set_playlist_to_album = true
|
||||
# If part of a playlist, sets the `tracknumber` field in the metadata to the track's
|
||||
# position in the playlist instead of its position in its album
|
||||
renumber_playlist_tracks = true
|
||||
# The following metadata tags won't be applied
|
||||
# See https://github.com/nathom/streamrip/wiki/Metadata-Tag-Names for more info
|
||||
exclude = []
|
||||
|
||||
# Changes the folder and file names generated by streamrip.
|
||||
[filepaths]
|
||||
# Create folders for single tracks within the downloads directory using the folder_format
|
||||
# template
|
||||
add_singles_to_folder = false
|
||||
# Available keys: "albumartist", "title", "year", "bit_depth", "sampling_rate",
|
||||
# "id", and "albumcomposer"
|
||||
folder_format = "{albumartist} - {title} ({year}) [{container}] [{bit_depth}B-{sampling_rate}kHz]"
|
||||
# Available keys: "tracknumber", "artist", "albumartist", "composer", "title",
|
||||
# and "albumcomposer", "explicit"
|
||||
track_format = "{tracknumber}. {artist} - {title}{explicit}"
|
||||
# Only allow printable ASCII characters in filenames.
|
||||
restrict_characters = false
|
||||
# Truncate the filename if it is greater than this number of characters
|
||||
# Setting this to false may cause downloads to fail on some systems
|
||||
truncate_to = 120
|
||||
|
||||
# Last.fm playlists are downloaded by searching for the titles of the tracks
|
||||
[lastfm]
|
||||
# The source on which to search for the tracks.
|
||||
source = "qobuz"
|
||||
# If no results were found with the primary source, the item is searched for
|
||||
# on this one.
|
||||
fallback_source = ""
|
||||
|
||||
[cli]
|
||||
# Print "Downloading {Album name}" etc. to screen
|
||||
text_output = true
|
||||
# Show resolve, download progress bars
|
||||
progress_bars = true
|
||||
# The maximum number of search results to show in the interactive menu
|
||||
max_search_results = 100
|
||||
|
||||
[misc]
|
||||
# Metadata to identify this config file. Do not change.
|
||||
version = "2.0.6"
|
||||
check_for_updates = true
|
||||
|
|
@ -0,0 +1,142 @@
|
|||
[downloads]
|
||||
# Folder where tracks are downloaded to
|
||||
folder = "old_value"
|
||||
# Put Qobuz albums in a 'Qobuz' folder, Tidal albums in 'Tidal' etc.
|
||||
source_subdirectories = true
|
||||
|
||||
[qobuz]
|
||||
# 1: 320kbps MP3, 2: 16/44.1, 3: 24/<=96, 4: 24/>=96
|
||||
quality = 3
|
||||
|
||||
# Authenticate to Qobuz using auth token? Value can be true/false only
|
||||
use_auth_token = false
|
||||
# Enter your userid if the above use_auth_token is set to true, else enter your email
|
||||
email_or_userid = "old_test@gmail.com"
|
||||
# Enter your auth token if the above use_auth_token is set to true, else enter the md5 hash of your plaintext password
|
||||
password_or_token = "old_test_pwd"
|
||||
# Do not change
|
||||
app_id = "old_12345"
|
||||
# Do not change
|
||||
secrets = ['old_secret1', 'old_secret2']
|
||||
|
||||
[tidal]
|
||||
# 0: 256kbps AAC, 1: 320kbps AAC, 2: 16/44.1 "HiFi" FLAC, 3: 24/44.1 "MQA" FLAC
|
||||
quality = 3
|
||||
# This will download videos included in Video Albums.
|
||||
download_videos = true
|
||||
|
||||
# Do not change any of the fields below
|
||||
user_id = "old_userid"
|
||||
country_code = "old_countrycode"
|
||||
access_token = "old_accesstoken"
|
||||
refresh_token = "old_refreshtoken"
|
||||
# Tokens last 1 week after refresh. This is the Unix timestamp of the expiration
|
||||
# time. If you haven't used streamrip in more than a week, you may have to log
|
||||
# in again using `rip config --tidal`
|
||||
token_expiry = "old_tokenexpiry"
|
||||
|
||||
[deezer]
|
||||
# 0, 1, or 2
|
||||
# This only applies to paid Deezer subscriptions. Those using deezloader
|
||||
# are automatically limited to quality = 1
|
||||
quality = 2
|
||||
# An authentication cookie that allows streamrip to use your Deezer account
|
||||
# See https://github.com/nathom/streamrip/wiki/Finding-Your-Deezer-ARL-Cookie
|
||||
# for instructions on how to find this
|
||||
arl = "old_testarl"
|
||||
# This allows for free 320kbps MP3 downloads from Deezer
|
||||
# If an arl is provided, deezloader is never used
|
||||
use_deezloader = true
|
||||
# This warns you when the paid deezer account is not logged in and rip falls
|
||||
# back to deezloader, which is unreliable
|
||||
deezloader_warnings = true
|
||||
|
||||
[soundcloud]
|
||||
# Only 0 is available for now
|
||||
quality = 0
|
||||
# This changes periodically, so it needs to be updated
|
||||
client_id = "old_clientid"
|
||||
app_version = "old_appversion"
|
||||
|
||||
[youtube]
|
||||
# Only 0 is available for now
|
||||
quality = 0
|
||||
# Download the video along with the audio
|
||||
download_videos = false
|
||||
|
||||
[database]
|
||||
# Create a database that contains all the track IDs downloaded so far
|
||||
# Any time a track logged in the database is requested, it is skipped
|
||||
# This can be disabled temporarily with the --no-db flag
|
||||
downloads_enabled = true
|
||||
# Path to the downloads database
|
||||
downloads_path = "old_downloadspath"
|
||||
# If a download fails, the item ID is stored here. Then, `rip repair` can be
|
||||
# called to retry the downloads
|
||||
failed_downloads_enabled = true
|
||||
failed_downloads_path = "old_faileddownloadspath"
|
||||
|
||||
# Convert tracks to a codec after downloading them.
|
||||
[conversion]
|
||||
enabled = false
|
||||
# FLAC, ALAC, OPUS, MP3, VORBIS, or AAC
|
||||
codec = "old_ALAC"
|
||||
# In Hz. Tracks are downsampled if their sampling rate is greater than this.
|
||||
# Value of 48000 is recommended to maximize quality and minimize space
|
||||
sampling_rate = 48000
|
||||
# Only 16 and 24 are available. It is only applied when the bit depth is higher
|
||||
# than this value.
|
||||
bit_depth = 24
|
||||
# Only applicable for lossy codecs
|
||||
lossy_bitrate = 320
|
||||
|
||||
# Filter a Qobuz artist's discography. Set to 'true' to turn on a filter.
|
||||
[qobuz_filters]
|
||||
# Remove Collectors Editions, live recordings, etc.
|
||||
extras = false
|
||||
# Picks the highest quality out of albums with identical titles.
|
||||
repeats = false
|
||||
# Remove EPs and Singles
|
||||
non_albums = false
|
||||
# Remove albums whose artist is not the one requested
|
||||
features = false
|
||||
# Skip non studio albums
|
||||
non_studio_albums = false
|
||||
# Only download remastered albums
|
||||
non_remaster = false
|
||||
|
||||
[artwork]
|
||||
# Write the image to the audio file
|
||||
embed = true
|
||||
# The size of the artwork to embed. Options: thumbnail, small, large, original.
|
||||
# "original" images can be up to 30MB, and may fail embedding.
|
||||
# Using "large" is recommended.
|
||||
embed_size = "old_large"
|
||||
|
||||
|
||||
[metadata]
|
||||
# Sets the value of the 'ALBUM' field in the metadata to the playlist's name.
|
||||
# This is useful if your music library software organizes tracks based on album name.
|
||||
set_playlist_to_album = true
|
||||
# If part of a playlist, sets the `tracknumber` field in the metadata to the track's
|
||||
# position in the playlist instead of its position in its album
|
||||
renumber_playlist_tracks = true
|
||||
# The following metadata tags won't be applied
|
||||
# See https://github.com/nathom/streamrip/wiki/Metadata-Tag-Names for more info
|
||||
exclude = []
|
||||
|
||||
# Changes the folder and file names generated by streamrip.
|
||||
[filepaths]
|
||||
# Create folders for single tracks within the downloads directory using the folder_format
|
||||
# template
|
||||
add_singles_to_folder = false
|
||||
# Available keys: "albumartist", "title", "year", "bit_depth", "sampling_rate",
|
||||
# "id", and "albumcomposer"
|
||||
folder_format = "old_{albumartist} - {title} ({year}) [{container}] [{bit_depth}B-{sampling_rate}kHz]"
|
||||
# Available keys: "tracknumber", "artist", "albumartist", "composer", "title",
|
||||
# and "albumcomposer", "explicit"
|
||||
|
||||
[misc]
|
||||
# Metadata to identify this config file. Do not change.
|
||||
version = "0.0.1"
|
||||
check_for_updates = true
|
||||
|
|
@ -0,0 +1,42 @@
|
|||
import pytest
|
||||
import tomlkit
|
||||
from tomlkit.toml_document import TOMLDocument
|
||||
|
||||
from streamrip.config import ConfigData
|
||||
|
||||
|
||||
@pytest.fixture()
|
||||
def toml():
|
||||
with open("streamrip/config.toml") as f:
|
||||
t = tomlkit.parse(f.read()) # type: ignore
|
||||
return t
|
||||
|
||||
|
||||
@pytest.fixture()
|
||||
def config():
|
||||
return ConfigData.defaults()
|
||||
|
||||
|
||||
def test_toml_subset_of_py(toml, config):
|
||||
"""Test that all keys in the TOML file are in the config classes."""
|
||||
for k, v in toml.items():
|
||||
if k in config.__slots__:
|
||||
if isinstance(v, TOMLDocument):
|
||||
test_toml_subset_of_py(v, getattr(config, k))
|
||||
else:
|
||||
raise Exception(f"{k} not in {config.__slots__}")
|
||||
|
||||
|
||||
exclude = {"toml", "_modified"}
|
||||
|
||||
|
||||
def test_py_subset_of_toml(toml, config):
|
||||
"""Test that all keys in the python classes are in the TOML file."""
|
||||
for item in config.__slots__:
|
||||
if item in exclude:
|
||||
continue
|
||||
if item in toml:
|
||||
if "Config" in item.__class__.__name__:
|
||||
test_py_subset_of_toml(toml[item], getattr(config, item))
|
||||
else:
|
||||
raise Exception(f"Config field {item} not in {list(toml.keys())}")
|
||||
|
|
@ -0,0 +1,71 @@
|
|||
import pytest
|
||||
|
||||
from streamrip.metadata import Covers
|
||||
|
||||
|
||||
@pytest.fixture()
|
||||
def covers_all():
|
||||
c = Covers()
|
||||
c.set_cover("original", "ourl", None)
|
||||
c.set_cover("large", "lurl", None)
|
||||
c.set_cover("small", "surl", None)
|
||||
c.set_cover("thumbnail", "turl", None)
|
||||
|
||||
return c
|
||||
|
||||
|
||||
@pytest.fixture()
|
||||
def covers_none():
|
||||
return Covers()
|
||||
|
||||
|
||||
@pytest.fixture()
|
||||
def covers_one():
|
||||
c = Covers()
|
||||
c.set_cover("small", "surl", None)
|
||||
return c
|
||||
|
||||
|
||||
@pytest.fixture()
|
||||
def covers_some():
|
||||
c = Covers()
|
||||
c.set_cover("large", "lurl", None)
|
||||
c.set_cover("small", "surl", None)
|
||||
return c
|
||||
|
||||
|
||||
def test_covers_all(covers_all):
|
||||
assert covers_all._covers == [
|
||||
("original", "ourl", None),
|
||||
("large", "lurl", None),
|
||||
("small", "surl", None),
|
||||
("thumbnail", "turl", None),
|
||||
]
|
||||
assert covers_all.largest() == ("original", "ourl", None)
|
||||
assert covers_all.get_size("original") == ("original", "ourl", None)
|
||||
assert covers_all.get_size("thumbnail") == ("thumbnail", "turl", None)
|
||||
|
||||
|
||||
def test_covers_none(covers_none):
|
||||
assert covers_none.empty()
|
||||
with pytest.raises(Exception):
|
||||
covers_none.largest()
|
||||
with pytest.raises(Exception):
|
||||
covers_none.get_size("original")
|
||||
|
||||
|
||||
def test_covers_one(covers_one):
|
||||
assert not covers_one.empty()
|
||||
assert covers_one.largest() == ("small", "surl", None)
|
||||
assert covers_one.get_size("original") == ("small", "surl", None)
|
||||
with pytest.raises(Exception):
|
||||
covers_one.get_size("thumbnail")
|
||||
|
||||
|
||||
def test_covers_some(covers_some):
|
||||
assert not covers_some.empty()
|
||||
assert covers_some.largest() == ("large", "lurl", None)
|
||||
assert covers_some.get_size("original") == ("large", "lurl", None)
|
||||
assert covers_some.get_size("small") == ("small", "surl", None)
|
||||
with pytest.raises(Exception):
|
||||
covers_some.get_size("thumbnail")
|
||||
|
|
@ -1,20 +0,0 @@
|
|||
import os
|
||||
import time
|
||||
from pprint import pprint
|
||||
|
||||
from streamrip.downloadtools import DownloadPool
|
||||
|
||||
|
||||
def test_downloadpool(tmpdir):
|
||||
start = time.perf_counter()
|
||||
with DownloadPool(
|
||||
(f"https://pokeapi.co/api/v2/pokemon/{number}" for number in range(1, 151)),
|
||||
tempdir=tmpdir,
|
||||
) as pool:
|
||||
pool.download()
|
||||
assert len(os.listdir(tmpdir)) == 151
|
||||
|
||||
# the tempfiles should be removed at this point
|
||||
assert len(os.listdir(tmpdir)) == 0
|
||||
|
||||
print(f"Finished in {time.perf_counter() - start}s")
|
||||
|
|
@ -0,0 +1,63 @@
|
|||
import json
|
||||
|
||||
from streamrip.metadata import AlbumMetadata, TrackMetadata
|
||||
|
||||
with open("tests/qobuz_album_resp.json") as f:
|
||||
qobuz_album_resp = json.load(f)
|
||||
|
||||
with open("tests/qobuz_track_resp.json") as f:
|
||||
qobuz_track_resp = json.load(f)
|
||||
|
||||
|
||||
def test_album_metadata_qobuz():
|
||||
m = AlbumMetadata.from_qobuz(qobuz_album_resp)
|
||||
info = m.info
|
||||
assert info.id == "19512572"
|
||||
assert info.quality == 3
|
||||
assert info.container == "FLAC"
|
||||
assert info.label == "Rhino - Warner Records"
|
||||
assert info.explicit is False
|
||||
assert info.sampling_rate == 96
|
||||
assert info.bit_depth == 24
|
||||
assert info.booklets is None
|
||||
|
||||
assert m.album == "Rumours"
|
||||
assert m.albumartist == "Fleetwood Mac"
|
||||
assert m.year == "1977"
|
||||
assert "Pop" in m.genre
|
||||
assert "Rock" in m.genre
|
||||
assert not m.covers.empty()
|
||||
|
||||
assert m.albumcomposer == "Various Composers"
|
||||
assert m.comment is None
|
||||
assert m.compilation is None
|
||||
assert (
|
||||
m.copyright
|
||||
== "© 1977 Warner Records Inc. ℗ 1977 Warner Records Inc. Marketed by Rhino Entertainment Company, A Warner Music Group Company."
|
||||
)
|
||||
assert m.date == "1977-02-04"
|
||||
assert m.description == ""
|
||||
assert m.disctotal == 1
|
||||
assert m.encoder is None
|
||||
assert m.grouping is None
|
||||
assert m.lyrics is None
|
||||
assert m.purchase_date is None
|
||||
assert m.tracktotal == 11
|
||||
|
||||
|
||||
def test_track_metadata_qobuz():
|
||||
a = AlbumMetadata.from_qobuz(qobuz_track_resp["album"])
|
||||
t = TrackMetadata.from_qobuz(a, qobuz_track_resp)
|
||||
info = t.info
|
||||
assert info.id == "216020864"
|
||||
assert info.quality == 3
|
||||
assert info.bit_depth == 24
|
||||
assert info.sampling_rate == 96
|
||||
assert info.work is None
|
||||
|
||||
assert t.title == "Water Tower"
|
||||
assert t.album == a
|
||||
assert t.artist == "The Mountain Goats"
|
||||
assert t.tracknumber == 9
|
||||
assert t.discnumber == 1
|
||||
assert t.composer == "John Darnielle"
|
||||
|
|
@ -0,0 +1,83 @@
|
|||
import hashlib
|
||||
import logging
|
||||
import os
|
||||
|
||||
import pytest
|
||||
from util import arun
|
||||
|
||||
from streamrip.client.downloadable import BasicDownloadable
|
||||
from streamrip.client.qobuz import QobuzClient
|
||||
from streamrip.config import Config
|
||||
from streamrip.exceptions import MissingCredentialsError
|
||||
|
||||
logger = logging.getLogger("streamrip")
|
||||
|
||||
|
||||
@pytest.fixture(scope="session")
|
||||
def qobuz_client():
|
||||
config = Config.defaults()
|
||||
config.session.qobuz.email_or_userid = os.environ["QOBUZ_EMAIL"]
|
||||
config.session.qobuz.password_or_token = hashlib.md5(
|
||||
os.environ["QOBUZ_PASSWORD"].encode("utf-8"),
|
||||
).hexdigest()
|
||||
if "QOBUZ_APP_ID" in os.environ and "QOBUZ_SECRETS" in os.environ:
|
||||
config.session.qobuz.app_id = os.environ["QOBUZ_APP_ID"]
|
||||
config.session.qobuz.secrets = os.environ["QOBUZ_SECRETS"].split(",")
|
||||
client = QobuzClient(config)
|
||||
arun(client.login())
|
||||
|
||||
yield client
|
||||
|
||||
arun(client.session.close())
|
||||
|
||||
|
||||
def test_client_raises_missing_credentials():
|
||||
c = Config.defaults()
|
||||
with pytest.raises(MissingCredentialsError):
|
||||
arun(QobuzClient(c).login())
|
||||
|
||||
|
||||
@pytest.mark.skipif(
|
||||
"QOBUZ_EMAIL" not in os.environ, reason="Qobuz credentials not found in env."
|
||||
)
|
||||
def test_client_get_metadata(qobuz_client):
|
||||
meta = arun(qobuz_client.get_metadata("s9nzkwg2rh1nc", "album"))
|
||||
assert meta["title"] == "I Killed Your Dog"
|
||||
assert len(meta["tracks"]["items"]) == 16
|
||||
assert meta["maximum_bit_depth"] == 24
|
||||
|
||||
|
||||
@pytest.mark.skipif(
|
||||
"QOBUZ_EMAIL" not in os.environ, reason="Qobuz credentials not found in env."
|
||||
)
|
||||
def test_client_get_downloadable(qobuz_client):
|
||||
d = arun(qobuz_client.get_downloadable("19512574", 3))
|
||||
assert isinstance(d, BasicDownloadable)
|
||||
assert d.extension == "flac"
|
||||
assert isinstance(d.url, str)
|
||||
assert "https://" in d.url
|
||||
|
||||
|
||||
@pytest.mark.skipif(
|
||||
"QOBUZ_EMAIL" not in os.environ, reason="Qobuz credentials not found in env."
|
||||
)
|
||||
def test_client_search_limit(qobuz_client):
|
||||
res = qobuz_client.search("album", "rumours", limit=5)
|
||||
total = 0
|
||||
for r in arun(res):
|
||||
total += len(r["albums"]["items"])
|
||||
assert total == 5
|
||||
|
||||
|
||||
@pytest.mark.skipif(
|
||||
"QOBUZ_EMAIL" not in os.environ, reason="Qobuz credentials not found in env."
|
||||
)
|
||||
def test_client_search_no_limit(qobuz_client):
|
||||
# Setting no limit has become impossible because `limit: int` now
|
||||
res = qobuz_client.search("album", "rumours", limit=10000)
|
||||
correct_total = 0
|
||||
total = 0
|
||||
for r in arun(res):
|
||||
total += len(r["albums"]["items"])
|
||||
correct_total = max(correct_total, r["albums"]["total"])
|
||||
assert total == correct_total
|
||||
|
|
@ -0,0 +1,111 @@
|
|||
import os
|
||||
import shutil
|
||||
|
||||
import pytest
|
||||
from mutagen.flac import FLAC
|
||||
from util import arun
|
||||
|
||||
from streamrip.metadata import (
|
||||
AlbumInfo,
|
||||
AlbumMetadata,
|
||||
Covers,
|
||||
TrackInfo,
|
||||
TrackMetadata,
|
||||
tag_file,
|
||||
)
|
||||
|
||||
TEST_FLAC_ORIGINAL = "tests/silence.flac"
|
||||
TEST_FLAC_COPY = "tests/silence_copy.flac"
|
||||
test_cover = "tests/1x1_pixel.jpg"
|
||||
|
||||
|
||||
def wipe_test_flac():
|
||||
audio = FLAC(TEST_FLAC_COPY)
|
||||
# Remove all tags
|
||||
audio.delete()
|
||||
audio.save()
|
||||
|
||||
|
||||
@pytest.fixture()
|
||||
def sample_metadata() -> TrackMetadata:
|
||||
return TrackMetadata(
|
||||
TrackInfo(
|
||||
id="12345",
|
||||
quality=3,
|
||||
bit_depth=24,
|
||||
explicit=True,
|
||||
sampling_rate=96,
|
||||
work=None,
|
||||
),
|
||||
"testtitle",
|
||||
AlbumMetadata(
|
||||
AlbumInfo("5678", 4, "flac"),
|
||||
"testalbum",
|
||||
"testalbumartist",
|
||||
"1999",
|
||||
["rock", "pop"],
|
||||
Covers(),
|
||||
14,
|
||||
3,
|
||||
"testalbumcomposer",
|
||||
"testcomment",
|
||||
compilation="testcompilation",
|
||||
copyright="(c) stuff (p) other stuff",
|
||||
date="1998-02-13",
|
||||
description="testdesc",
|
||||
encoder="ffmpeg",
|
||||
grouping="testgroup",
|
||||
lyrics="ye ye ye",
|
||||
purchase_date=None,
|
||||
),
|
||||
"testartist",
|
||||
3,
|
||||
1,
|
||||
"testcomposer",
|
||||
)
|
||||
|
||||
|
||||
def test_tag_flac_no_cover(sample_metadata):
|
||||
shutil.copy(TEST_FLAC_ORIGINAL, TEST_FLAC_COPY)
|
||||
wipe_test_flac()
|
||||
arun(tag_file(TEST_FLAC_COPY, sample_metadata, None))
|
||||
file = FLAC(TEST_FLAC_COPY)
|
||||
assert file["title"][0] == "testtitle"
|
||||
assert file["album"][0] == "testalbum"
|
||||
assert file["composer"][0] == "testcomposer"
|
||||
assert file["comment"][0] == "testcomment"
|
||||
assert file["artist"][0] == "testartist"
|
||||
assert file["albumartist"][0] == "testalbumartist"
|
||||
assert file["year"][0] == "1999"
|
||||
assert file["genre"][0] == "rock, pop"
|
||||
assert file["tracknumber"][0] == "03"
|
||||
assert file["discnumber"][0] == "01"
|
||||
assert file["copyright"][0] == "© stuff ℗ other stuff"
|
||||
assert file["tracktotal"][0] == "14"
|
||||
assert file["date"][0] == "1998-02-13"
|
||||
assert "purchase_date" not in file, file["purchase_date"]
|
||||
os.remove(TEST_FLAC_COPY)
|
||||
|
||||
|
||||
def test_tag_flac_cover(sample_metadata):
|
||||
shutil.copy(TEST_FLAC_ORIGINAL, TEST_FLAC_COPY)
|
||||
wipe_test_flac()
|
||||
arun(tag_file(TEST_FLAC_COPY, sample_metadata, test_cover))
|
||||
file = FLAC(TEST_FLAC_COPY)
|
||||
assert file["title"][0] == "testtitle"
|
||||
assert file["album"][0] == "testalbum"
|
||||
assert file["composer"][0] == "testcomposer"
|
||||
assert file["comment"][0] == "testcomment"
|
||||
assert file["artist"][0] == "testartist"
|
||||
assert file["albumartist"][0] == "testalbumartist"
|
||||
assert file["year"][0] == "1999"
|
||||
assert file["genre"][0] == "rock, pop"
|
||||
assert file["tracknumber"][0] == "03"
|
||||
assert file["discnumber"][0] == "01"
|
||||
assert file["copyright"][0] == "© stuff ℗ other stuff"
|
||||
assert file["tracktotal"][0] == "14"
|
||||
assert file["date"][0] == "1998-02-13"
|
||||
with open(test_cover, "rb") as img:
|
||||
assert file.pictures[0].data == img.read()
|
||||
assert "purchase_date" not in file, file["purchase_date"]
|
||||
os.remove(TEST_FLAC_COPY)
|
||||
|
|
@ -0,0 +1,32 @@
|
|||
import os
|
||||
import shutil
|
||||
|
||||
import pytest
|
||||
from util import arun
|
||||
|
||||
import streamrip.db as db
|
||||
from streamrip.client.downloadable import Downloadable
|
||||
from streamrip.client.qobuz import QobuzClient
|
||||
from streamrip.media.track import PendingSingle, Track
|
||||
|
||||
|
||||
@pytest.mark.skipif(
|
||||
"QOBUZ_EMAIL" not in os.environ, reason="Qobuz credentials not found in env."
|
||||
)
|
||||
def test_pending_resolve(qobuz_client: QobuzClient):
|
||||
qobuz_client.config.session.downloads.folder = "./tests"
|
||||
p = PendingSingle(
|
||||
"19512574",
|
||||
qobuz_client,
|
||||
qobuz_client.config,
|
||||
db.Database(db.Dummy(), db.Dummy()),
|
||||
)
|
||||
t = arun(p.resolve())
|
||||
dir = "tests/tests/Fleetwood Mac - Rumours (1977) [FLAC] [24B-96kHz]"
|
||||
assert os.path.isdir(dir)
|
||||
assert os.path.isfile(os.path.join(dir, "cover.jpg"))
|
||||
assert os.path.isfile(t.cover_path)
|
||||
assert isinstance(t, Track)
|
||||
assert isinstance(t.downloadable, Downloadable)
|
||||
assert t.cover_path is not None
|
||||
shutil.rmtree(dir)
|
||||
|
|
@ -0,0 +1,32 @@
|
|||
import re
|
||||
|
||||
import pytest
|
||||
|
||||
from streamrip import __version__ as init_version
|
||||
from streamrip.config import CURRENT_CONFIG_VERSION
|
||||
|
||||
toml_version_re = re.compile(r'version\s*\=\s*"([\d\.]+)"')
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def pyproject_version() -> str:
|
||||
with open("pyproject.toml") as f:
|
||||
m = toml_version_re.search(f.read())
|
||||
assert m is not None
|
||||
return m.group(1)
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def config_version() -> str | None:
|
||||
with open("streamrip/config.toml") as f:
|
||||
m = toml_version_re.search(f.read())
|
||||
assert m is not None
|
||||
return m.group(1)
|
||||
|
||||
|
||||
def test_config_versions_match(config_version):
|
||||
assert config_version == CURRENT_CONFIG_VERSION
|
||||
|
||||
|
||||
def test_streamrip_versions_match(pyproject_version):
|
||||
assert pyproject_version == init_version
|
||||
119
tests/tests.py
|
|
@ -1,119 +0,0 @@
|
|||
import os
|
||||
import shutil
|
||||
import subprocess
|
||||
|
||||
from click import echo, secho
|
||||
|
||||
test_urls = {
|
||||
"qobuz": "https://www.qobuz.com/us-en/album/blackest-blue-morcheeba/h4nngz0wgqesc",
|
||||
"tidal": "https://tidal.com/browse/album/183284294",
|
||||
"deezer": "https://www.deezer.com/us/album/225281222",
|
||||
"soundcloud": "https://soundcloud.com/dj-khaled/sets/khaled-khaled",
|
||||
}
|
||||
|
||||
|
||||
def reset_config():
|
||||
global cfg_path
|
||||
global new_cfg_path
|
||||
|
||||
p = subprocess.Popen(
|
||||
["rip", "config", "-p"], stdout=subprocess.PIPE, stderr=subprocess.PIPE
|
||||
)
|
||||
out, err = p.communicate()
|
||||
cfg_path = out.decode("utf-8").strip()
|
||||
# cfg_path = re.search(
|
||||
# r"(/[\w\d\s]+(?:/[\w\d \.]+)*)", out.decode("utf-8")
|
||||
# ).group(1)
|
||||
new_cfg_path = f"{cfg_path}.tmp"
|
||||
shutil.copy(cfg_path, new_cfg_path)
|
||||
subprocess.Popen(["rip", "config", "--update"])
|
||||
|
||||
|
||||
def restore_config():
|
||||
global cfg_path
|
||||
global new_cfg_path
|
||||
|
||||
os.remove(cfg_path)
|
||||
shutil.move(new_cfg_path, cfg_path)
|
||||
|
||||
|
||||
def download_albums():
|
||||
rip_url = ["rip", "-nd", "-u"]
|
||||
procs = []
|
||||
for url in test_urls.values():
|
||||
procs.append(subprocess.run([*rip_url, url]))
|
||||
|
||||
for p in procs:
|
||||
echo(p)
|
||||
|
||||
|
||||
def check_album_dl_success(folder, correct):
|
||||
if set(os.listdir(folder)) != set(correct):
|
||||
secho(f"Check for {folder} failed!", fg="red")
|
||||
else:
|
||||
secho(f"Check for {folder} succeeded!", fg="green")
|
||||
|
||||
|
||||
def main():
|
||||
reset_config()
|
||||
download_albums()
|
||||
check_album_dl_success(
|
||||
"/Users/nathan/StreamripDownloads/Morcheeba - Blackest Blue (2021) [FLAC] [24B-44.1kHz]",
|
||||
{
|
||||
"04. Morcheeba - Say It's Over.flac",
|
||||
"01. Morcheeba - Cut My Heart Out.flac",
|
||||
"02. Morcheeba - Killed Our Love.flac",
|
||||
"07. Morcheeba - Namaste.flac",
|
||||
"03. Morcheeba - Sounds Of Blue.flac",
|
||||
"10. Morcheeba - The Edge Of The World.flac",
|
||||
"08. Morcheeba - The Moon.flac",
|
||||
"09. Morcheeba - Falling Skies.flac",
|
||||
"cover.jpg",
|
||||
"05. Morcheeba - Sulphur Soul.flac",
|
||||
"06. Morcheeba - Oh Oh Yeah.flac",
|
||||
},
|
||||
)
|
||||
|
||||
check_album_dl_success(
|
||||
"/Users/nathan/StreamripDownloads/KHALED KHALED",
|
||||
{
|
||||
"05. DJ Khaled - I DID IT (feat. Post Malone, Megan Thee Stallion, Lil Baby & DaBaby).mp3",
|
||||
"09. DJ Khaled - THIS IS MY YEAR (feat. A Boogie Wit Da Hoodie, Big Sean, Rick Ross & Puff Daddy).mp3",
|
||||
"01. DJ Khaled - THANKFUL (feat. Lil Wayne & Jeremih).mp3",
|
||||
"12. DJ Khaled - I CAN HAVE IT ALL (feat. Bryson Tiller, H.E.R. & Meek Mill).mp3",
|
||||
"02. DJ Khaled - EVERY CHANCE I GET (feat. Lil Baby & Lil Durk).mp3",
|
||||
"08. DJ Khaled - POPSTAR (feat. Drake).mp3",
|
||||
"13. DJ Khaled - GREECE (feat. Drake).mp3",
|
||||
"04. DJ Khaled - WE GOING CRAZY (feat. H.E.R. & Migos).mp3",
|
||||
"10. DJ Khaled - SORRY NOT SORRY (Harmonies by The Hive) [feat. Nas, JAY-Z & James Fauntleroy].mp3",
|
||||
"03. DJ Khaled - BIG PAPER (feat. Cardi B).mp3",
|
||||
"14. DJ Khaled - WHERE YOU COME FROM (feat. Buju Banton, Capleton & Bounty Killer).mp3",
|
||||
"07. DJ Khaled - BODY IN MOTION (feat. Bryson Tiller, Lil Baby & Roddy Ricch).mp3",
|
||||
"06. DJ Khaled - LET IT GO (feat. Justin Bieber & 21 Savage).mp3",
|
||||
"11. DJ Khaled - JUST BE (feat. Justin Timberlake).mp3",
|
||||
},
|
||||
)
|
||||
|
||||
check_album_dl_success(
|
||||
"/Users/nathan/StreamripDownloads/Paul Weller - Fat Pop (2021) [FLAC] [24B-44.1kHz]",
|
||||
{
|
||||
"01. Paul Weller - Cosmic Fringes.flac",
|
||||
"11. Paul Weller - In Better Times.flac",
|
||||
"05. Paul Weller - Glad Times.flac",
|
||||
"08. Paul Weller - That Pleasure.flac",
|
||||
"04. Paul Weller - Shades Of Blue.flac",
|
||||
"12. Paul Weller - Still Glides The Stream.flac",
|
||||
"03. Paul Weller - Fat Pop.flac",
|
||||
"cover.jpg",
|
||||
"02. Paul Weller - True.flac",
|
||||
"09. Paul Weller - Failed.flac",
|
||||
"06. Paul Weller - Cobweb Connections.flac",
|
||||
"10. Paul Weller - Moving Canvas.flac",
|
||||
"07. Paul Weller - Testify.flac",
|
||||
},
|
||||
)
|
||||
restore_config()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
|
|
@ -0,0 +1,17 @@
|
|||
import asyncio
|
||||
|
||||
loop = asyncio.new_event_loop()
|
||||
|
||||
|
||||
def arun(coro):
|
||||
return loop.run_until_complete(coro)
|
||||
|
||||
|
||||
def afor(async_gen):
|
||||
async def _afor(async_gen):
|
||||
items = []
|
||||
async for item in async_gen:
|
||||
items.append(item)
|
||||
return items
|
||||
|
||||
return arun(_afor(async_gen))
|
||||